 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyEdit++: Adaptive Long-Form Knowledge Editing via Bayesian Surprise
May 31, 2026Editing complex, long-form knowledge in Large Language Models remains a significant challenge due to the difficulty of maintaining generation coherence. Existing autoregressive methods like AnyEdit alleviate length constraints but rely on Fixed-window Chunking, which disregards logical structure and compromises consistency. To address this, we present AnyEdit++, a structure-aware framework incorporating Bayes-Chunk, an adaptive segmentation mechanism that dynamically identifies semantic boundaries based on Bayesian Surprise. We underpin this approach with a theoretical framework establishing two key principles: (1) Structural Independence: we prove that cross-segment interference is minimized when anchor keys are geometrically orthogonal (a condition naturally satisfied by our surprisal-based boundaries but violated by fixed windows), and (2) Causal Locality: we demonstrate that updates injected at these semantic peaks yield strictly superior control compared to arbitrary split points. Extensive experiments across mathematical reasoning, code generation, and narrative tasks demonstrate that AnyEdit++ achieves superior performance and robustness compared to state-of-the-art baselines, validating that structural awareness is critical for effective long-form knowledge editing.
VL-RouterBench: A Benchmark for Vision-Language Model Routing
Dec 29, 2025Multi-model routing has evolved from an engineering technique into essential infrastructure, yet existing work lacks a systematic, reproducible benchmark for evaluating vision-language models (VLMs). We present VL-RouterBench to assess the overall capability of VLM routing systems systematically. The benchmark is grounded in raw inference and scoring logs from VLMs and constructs quality and cost matrices over sample-model pairs. In scale, VL-RouterBench covers 14 datasets across 3 task groups, totaling 30,540 samples, and includes 15 open-source models and 2 API models, yielding 519,180 sample-model pairs and a total input-output token volume of 34,494,977. The evaluation protocol jointly measures average accuracy, average cost, and throughput, and builds a ranking score from the harmonic mean of normalized cost and accuracy to enable comparison across router configurations and cost budgets. On this benchmark, we evaluate 10 routing methods and baselines and observe a significant routability gain, while the best current routers still show a clear gap to the ideal Oracle, indicating considerable room for improvement in router architecture through finer visual cues and modeling of textual structure. We will open-source the complete data construction and evaluation toolchain to promote comparability, reproducibility, and practical deployment in multimodal routing research.
MienCap: Realtime Performance-Based Facial Animation with Live Mood Dynamics
Aug 06, 2025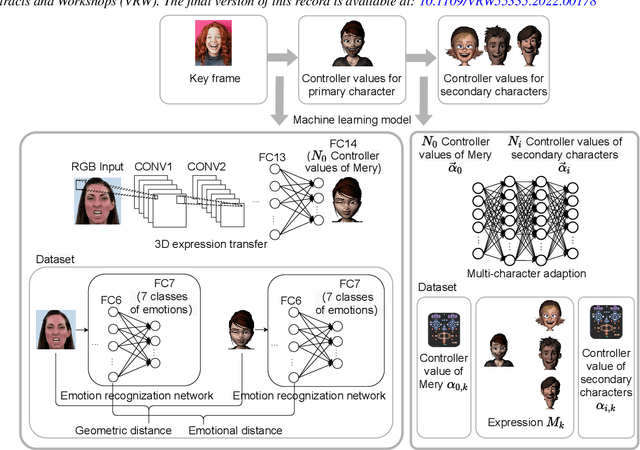
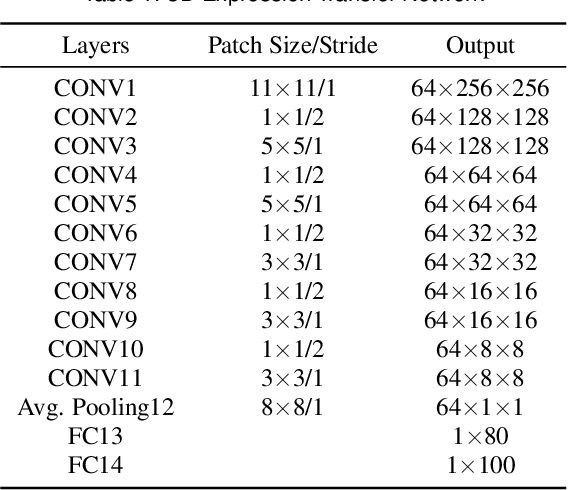
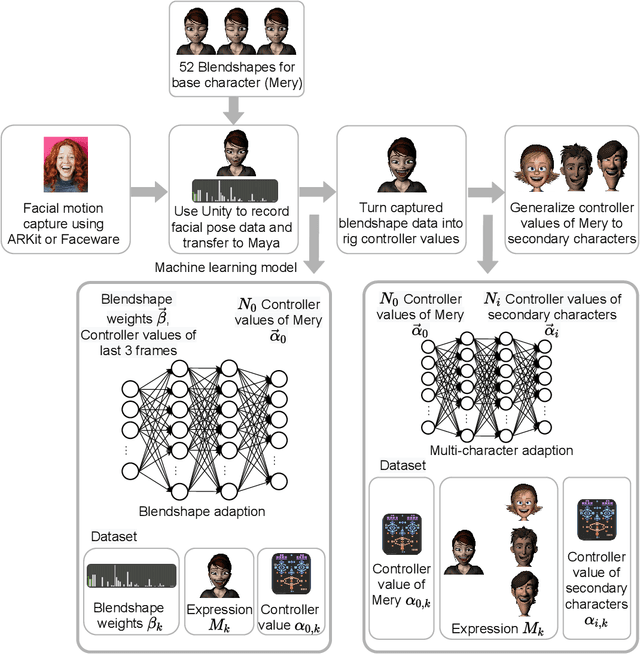

Our purpose is to improve performance-based animation which can drive believable 3D stylized characters that are truly perceptual. By combining traditional blendshape animation techniques with multiple machine learning models, we present both non-real time and real time solutions which drive character expressions in a geometrically consistent and perceptually valid way. For the non-real time system, we propose a 3D emotion transfer network makes use of a 2D human image to generate a stylized 3D rig parameters. For the real time system, we propose a blendshape adaption network which generates the character rig parameter motions with geometric consistency and temporally stability. We demonstrate the effectiveness of our system by comparing to a commercial product Faceware. Results reveal that ratings of the recognition, intensity, and attractiveness of expressions depicted for animated characters via our systems are statistically higher than Faceware. Our results may be implemented into the animation pipeline, and provide animators with a system for creating the expressions they wish to use more quickly and accurately.
Surgment: Segmentation-enabled Semantic Search and Creation of Visual Question and Feedback to Support Video-Based Surgery Learning
Feb 27, 2024



Videos are prominent learning materials to prepare surgical trainees before they enter the operating room (OR). In this work, we explore techniques to enrich the video-based surgery learning experience. We propose Surgment, a system that helps expert surgeons create exercises with feedback based on surgery recordings. Surgment is powered by a few-shot-learning-based pipeline (SegGPT+SAM) to segment surgery scenes, achieving an accuracy of 92\%. The segmentation pipeline enables functionalities to create visual questions and feedback desired by surgeons from a formative study. Surgment enables surgeons to 1) retrieve frames of interest through sketches, and 2) design exercises that target specific anatomical components and offer visual feedback. In an evaluation study with 11 surgeons, participants applauded the search-by-sketch approach for identifying frames of interest and found the resulting image-based questions and feedback to be of high educational value.