 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStickMotion: Generating 3D Human Motions by Drawing a Stickman
Mar 05, 2025

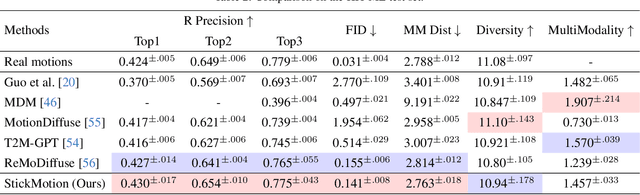
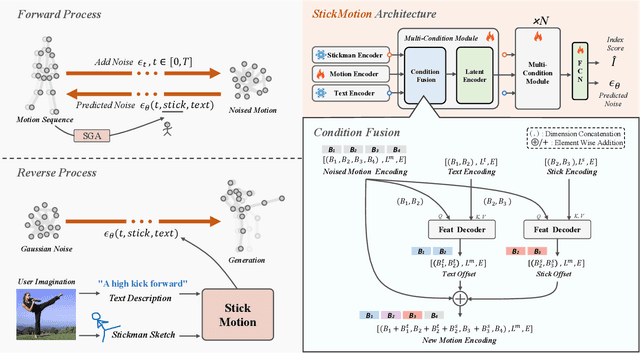
Text-to-motion generation, which translates textual descriptions into human motions, has been challenging in accurately capturing detailed user-imagined motions from simple text inputs. This paper introduces StickMotion, an efficient diffusion-based network designed for multi-condition scenarios, which generates desired motions based on traditional text and our proposed stickman conditions for global and local control of these motions, respectively. We address the challenges introduced by the user-friendly stickman from three perspectives: 1) Data generation. We develop an algorithm to generate hand-drawn stickmen automatically across different dataset formats. 2) Multi-condition fusion. We propose a multi-condition module that integrates into the diffusion process and obtains outputs of all possible condition combinations, reducing computational complexity and enhancing StickMotion's performance compared to conventional approaches with the self-attention module. 3) Dynamic supervision. We empower StickMotion to make minor adjustments to the stickman's position within the output sequences, generating more natural movements through our proposed dynamic supervision strategy. Through quantitative experiments and user studies, sketching stickmen saves users about 51.5% of their time generating motions consistent with their imagination. Our codes, demos, and relevant data will be released to facilitate further research and validation within the scientific community.
Liger: Linearizing Large Language Models to Gated Recurrent Structures
Mar 03, 2025



Transformers with linear recurrent modeling offer linear-time training and constant-memory inference. Despite their demonstrated efficiency and performance, pretraining such non-standard architectures from scratch remains costly and risky. The linearization of large language models (LLMs) transforms pretrained standard models into linear recurrent structures, enabling more efficient deployment. However, current linearization methods typically introduce additional feature map modules that require extensive fine-tuning and overlook the gating mechanisms used in state-of-the-art linear recurrent models. To address these issues, this paper presents Liger, short for Linearizing LLMs to gated recurrent structures. Liger is a novel approach for converting pretrained LLMs into gated linear recurrent models without adding extra parameters. It repurposes the pretrained key matrix weights to construct diverse gating mechanisms, facilitating the formation of various gated recurrent structures while avoiding the need to train additional components from scratch. Using lightweight fine-tuning with Low-Rank Adaptation (LoRA), Liger restores the performance of the linearized gated recurrent models to match that of the original LLMs. Additionally, we introduce Liger Attention, an intra-layer hybrid attention mechanism, which significantly recovers 93\% of the Transformer-based LLM at 0.02\% pre-training tokens during the linearization process, achieving competitive results across multiple benchmarks, as validated on models ranging from 1B to 8B parameters. Code is available at https://github.com/OpenSparseLLMs/Linearization.
Extrapolating and Decoupling Image-to-Video Generation Models: Motion Modeling is Easier Than You Think
Mar 02, 2025Image-to-Video (I2V) generation aims to synthesize a video clip according to a given image and condition (e.g., text). The key challenge of this task lies in simultaneously generating natural motions while preserving the original appearance of the images. However, current I2V diffusion models (I2V-DMs) often produce videos with limited motion degrees or exhibit uncontrollable motion that conflicts with the textual condition. To address these limitations, we propose a novel Extrapolating and Decoupling framework, which introduces model merging techniques to the I2V domain for the first time. Specifically, our framework consists of three separate stages: (1) Starting with a base I2V-DM, we explicitly inject the textual condition into the temporal module using a lightweight, learnable adapter and fine-tune the integrated model to improve motion controllability. (2) We introduce a training-free extrapolation strategy to amplify the dynamic range of the motion, effectively reversing the fine-tuning process to enhance the motion degree significantly. (3) With the above two-stage models excelling in motion controllability and degree, we decouple the relevant parameters associated with each type of motion ability and inject them into the base I2V-DM. Since the I2V-DM handles different levels of motion controllability and dynamics at various denoising time steps, we adjust the motion-aware parameters accordingly over time. Extensive qualitative and quantitative experiments have been conducted to demonstrate the superiority of our framework over existing methods.
* Accepted by CVPR2025
Make LoRA Great Again: Boosting LoRA with Adaptive Singular Values and Mixture-of-Experts Optimization Alignment
Feb 26, 2025



While Low-Rank Adaptation (LoRA) enables parameter-efficient fine-tuning for Large Language Models (LLMs), its performance often falls short of Full Fine-Tuning (Full FT). Current methods optimize LoRA by initializing with static singular value decomposition (SVD) subsets, leading to suboptimal leveraging of pre-trained knowledge. Another path for improving LoRA is incorporating a Mixture-of-Experts (MoE) architecture. However, weight misalignment and complex gradient dynamics make it challenging to adopt SVD prior to the LoRA MoE architecture. To mitigate these issues, we propose \underline{G}reat L\underline{o}R\underline{A} Mixture-of-Exper\underline{t} (GOAT), a framework that (1) adaptively integrates relevant priors using an SVD-structured MoE, and (2) aligns optimization with full fine-tuned MoE by deriving a theoretical scaling factor. We demonstrate that proper scaling, without modifying the architecture or training algorithms, boosts LoRA MoE's efficiency and performance. Experiments across 25 datasets, including natural language understanding, commonsense reasoning, image classification, and natural language generation, demonstrate GOAT's state-of-the-art performance, closing the gap with Full FT.
Multi-LLM Collaborative Search for Complex Problem Solving
Feb 26, 2025



Large language models (LLMs) often struggle with complex reasoning tasks due to their limitations in addressing the vast reasoning space and inherent ambiguities of natural language. We propose the Mixture-of-Search-Agents (MoSA) paradigm, a novel approach leveraging the collective expertise of multiple LLMs to enhance search-based reasoning. MoSA integrates diverse reasoning pathways by combining independent exploration with iterative refinement among LLMs, mitigating the limitations of single-model approaches. Using Monte Carlo Tree Search (MCTS) as a backbone, MoSA enables multiple agents to propose and aggregate reasoning steps, resulting in improved accuracy. Our comprehensive evaluation across four reasoning benchmarks demonstrates MoSA's consistent performance improvements over single-agent and other multi-agent baselines, particularly in complex mathematical and commonsense reasoning tasks.
AttentionEngine: A Versatile Framework for Efficient Attention Mechanisms on Diverse Hardware Platforms
Feb 21, 2025Transformers and large language models (LLMs) have revolutionized machine learning, with attention mechanisms at the core of their success. As the landscape of attention variants expands, so too do the challenges of optimizing their performance, particularly across different hardware platforms. Current optimization strategies are often narrowly focused, requiring extensive manual intervention to accommodate changes in model configurations or hardware environments. In this paper, we introduce AttentionEngine, a comprehensive framework designed to streamline the optimization of attention mechanisms across heterogeneous hardware backends. By decomposing attention computation into modular operations with customizable components, AttentionEngine enables flexible adaptation to diverse algorithmic requirements. The framework further automates kernel optimization through a combination of programmable templates and a robust cross-platform scheduling strategy. Empirical results reveal performance gains of up to 10x on configurations beyond the reach of existing methods. AttentionEngine offers a scalable, efficient foundation for developing and deploying attention mechanisms with minimal manual tuning. Our code has been open-sourced and is available at https://github.com/microsoft/AttentionEngine.
Unveiling Attractor Cycles in Large Language Models: A Dynamical Systems View of Successive Paraphrasing
Feb 21, 2025



Dynamical systems theory provides a framework for analyzing iterative processes and evolution over time. Within such systems, repetitive transformations can lead to stable configurations, known as attractors, including fixed points and limit cycles. Applying this perspective to large language models (LLMs), which iteratively map input text to output text, provides a principled approach to characterizing long-term behaviors. Successive paraphrasing serves as a compelling testbed for exploring such dynamics, as paraphrases re-express the same underlying meaning with linguistic variation. Although LLMs are expected to explore a diverse set of paraphrases in the text space, our study reveals that successive paraphrasing converges to stable periodic states, such as 2-period attractor cycles, limiting linguistic diversity. This phenomenon is attributed to the self-reinforcing nature of LLMs, as they iteratively favour and amplify certain textual forms over others. This pattern persists with increasing generation randomness or alternating prompts and LLMs. These findings underscore inherent constraints in LLM generative capability, while offering a novel dynamical systems perspective for studying their expressive potential.
MoM: Linear Sequence Modeling with Mixture-of-Memories
Feb 19, 2025



Linear sequence modeling methods, such as linear attention, state space modeling, and linear RNNs, offer significant efficiency improvements by reducing the complexity of training and inference. However, these methods typically compress the entire input sequence into a single fixed-size memory state, which leads to suboptimal performance on recall-intensive downstream tasks. Drawing inspiration from neuroscience, particularly the brain's ability to maintain robust long-term memory while mitigating "memory interference", we introduce a novel architecture called Mixture-of-Memories (MoM). MoM utilizes multiple independent memory states, with a router network directing input tokens to specific memory states. This approach greatly enhances the overall memory capacity while minimizing memory interference. As a result, MoM performs exceptionally well on recall-intensive tasks, surpassing existing linear sequence modeling techniques. Despite incorporating multiple memory states, the computation of each memory state remains linear in complexity, allowing MoM to retain the linear-complexity advantage during training, while constant-complexity during inference. Our experimental results show that MoM significantly outperforms current linear sequence models on downstream language tasks, particularly recall-intensive tasks, and even achieves performance comparable to Transformer models. The code is released at https://github.com/OpenSparseLLMs/MoM and is also released as a part of https://github.com/OpenSparseLLMs/Linear-MoE.
DGSense: A Domain Generalization Framework for Wireless Sensing
Feb 12, 2025Wireless sensing is of great benefits to our daily lives. However, wireless signals are sensitive to the surroundings. Various factors, e.g. environments, locations, and individuals, may induce extra impact on wireless propagation. Such a change can be regarded as a domain, in which the data distribution shifts. A vast majority of the sensing schemes are learning-based. They are dependent on the training domains, resulting in performance degradation in unseen domains. Researchers have proposed various solutions to address this issue. But these solutions leverage either semi-supervised or unsupervised domain adaptation techniques. They still require some data in the target domains and do not perform well in unseen domains. In this paper, we propose a domain generalization framework DGSense, to eliminate the domain dependence problem in wireless sensing. The framework is a general solution working across diverse sensing tasks and wireless technologies. Once the sensing model is built, it can generalize to unseen domains without any data from the target domain. To achieve the goal, we first increase the diversity of the training set by a virtual data generator, and then extract the domain independent features via episodic training between the main feature extractor and the domain feature extractors. The feature extractors employ a pre-trained Residual Network (ResNet) with an attention mechanism for spatial features, and a 1D Convolutional Neural Network (1DCNN) for temporal features. To demonstrate the effectiveness and generality of DGSense, we evaluated on WiFi gesture recognition, Millimeter Wave (mmWave) activity recognition, and acoustic fall detection. All the systems exhibited high generalization capability to unseen domains, including new users, locations, and environments, free of new data and retraining.
LASP-2: Rethinking Sequence Parallelism for Linear Attention and Its Hybrid
Feb 11, 2025



Linear sequence modeling approaches, such as linear attention, provide advantages like linear-time training and constant-memory inference over sequence lengths. However, existing sequence parallelism (SP) methods are either not optimized for the right-product-first feature of linear attention or use a ring-style communication strategy, which results in lower computation parallelism, limits their scalability for longer sequences in distributed systems. In this paper, we introduce LASP-2, a new SP method to enhance both communication and computation parallelism when training linear attention transformer models with very-long input sequences. Compared to previous work LASP, LASP-2 rethinks the minimal communication requirement for SP on linear attention layers, reorganizes the whole communication-computation workflow of LASP. In this way, only one single AllGather collective communication is needed on intermediate memory states, whose sizes are independent of the sequence length, leading to significant improvements of both communication and computation parallelism, as well as their overlap. Additionally, we extend LASP-2 to LASP-2H by applying similar communication redesign to standard attention modules, offering an efficient SP solution for hybrid models that blend linear and standard attention layers. Our evaluation on a Linear-Llama3 model, a variant of Llama3 with linear attention replacing standard attention, demonstrates the effectiveness of LASP-2 and LASP-2H. Specifically, LASP-2 achieves training speed improvements of 15.2% over LASP and 36.6% over Ring Attention, with a sequence length of 2048K across 64 GPUs. The Code is released as a part of: https://github.com/OpenSparseLLMs/Linear-MoE.