 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlurality and Quantification in Graph Representation of Meaning
Dec 13, 2021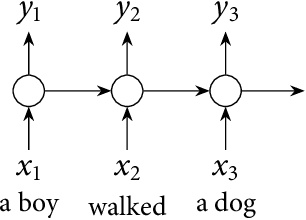

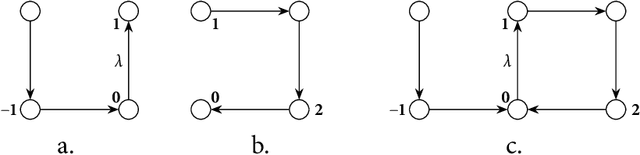
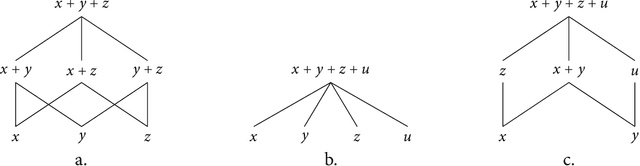
In this thesis we present a semantic representation formalism based on directed graphs and explore its linguistic adequacy and explanatory benefits in the semantics of plurality and quantification. Our graph language covers the essentials of natural language semantics using only monadic second-order variables. We define its model-theoretical interpretation in terms of graph traversal, where the relative scope of variables arises from their order of valuation. We present a unification-based mechanism for constructing semantic graphs at a simple syntax-semantics interface, where syntax as a partition function on discourse referents is implemented with categorial grammars by establishing a partly deterministic relation between semantics and syntactic distribution. This mechanism is automated to facilitate future exploration. The present graph formalism is applied to linguistic issues in distributive predication, cross-categorial conjunction, and scope permutation of quantificational expressions, including the exceptional scoping behaviors of indefinites.
Serving DNN Models with Multi-Instance GPUs: A Case of the Reconfigurable Machine Scheduling Problem
Sep 18, 2021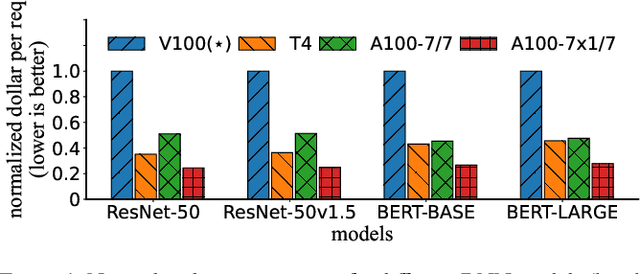
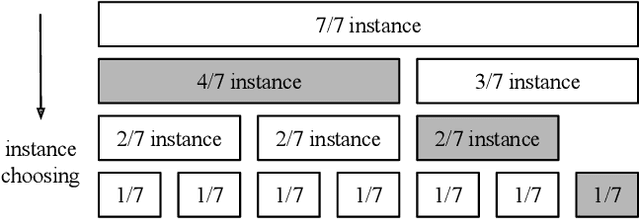
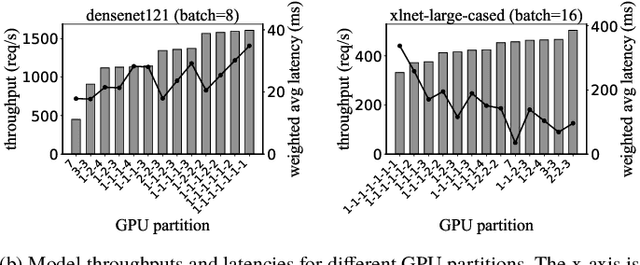
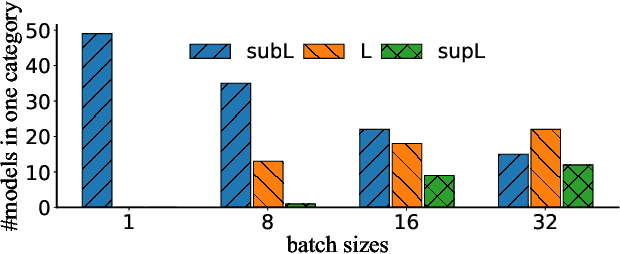
Multi-Instance GPU (MIG) is a new feature introduced by NVIDIA A100 GPUs that partitions one physical GPU into multiple GPU instances. With MIG, A100 can be the most cost-efficient GPU ever for serving Deep Neural Networks (DNNs). However, discovering the most efficient GPU partitions is challenging. The underlying problem is NP-hard; moreover, it is a new abstract problem, which we define as the Reconfigurable Machine Scheduling Problem (RMS). This paper studies serving DNNs with MIG, a new case of RMS. We further propose a solution, MIG-serving. MIG- serving is an algorithm pipeline that blends a variety of newly designed algorithms and customized classic algorithms, including a heuristic greedy algorithm, Genetic Algorithm (GA), and Monte Carlo Tree Search algorithm (MCTS). We implement MIG-serving on Kubernetes. Our experiments show that compared to using A100 as-is, MIG-serving can save up to 40% of GPUs while providing the same throughput.
SIAM: Chiplet-based Scalable In-Memory Acceleration with Mesh for Deep Neural Networks
Aug 14, 2021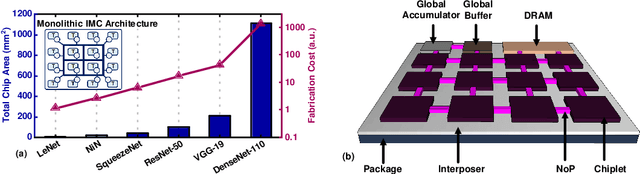
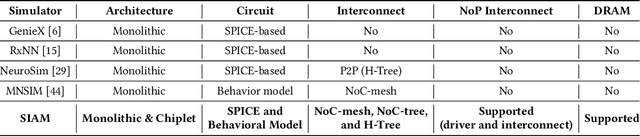
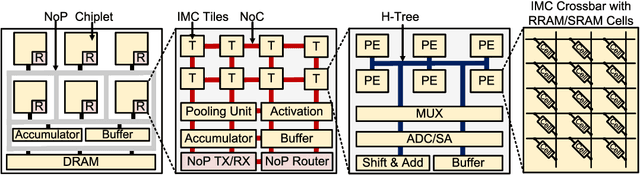
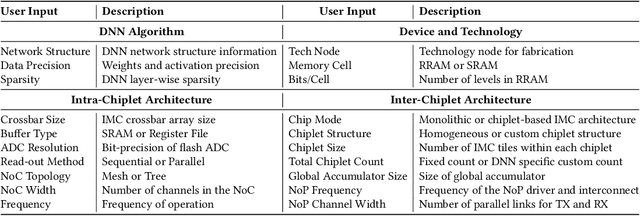
In-memory computing (IMC) on a monolithic chip for deep learning faces dramatic challenges on area, yield, and on-chip interconnection cost due to the ever-increasing model sizes. 2.5D integration or chiplet-based architectures interconnect multiple small chips (i.e., chiplets) to form a large computing system, presenting a feasible solution beyond a monolithic IMC architecture to accelerate large deep learning models. This paper presents a new benchmarking simulator, SIAM, to evaluate the performance of chiplet-based IMC architectures and explore the potential of such a paradigm shift in IMC architecture design. SIAM integrates device, circuit, architecture, network-on-chip (NoC), network-on-package (NoP), and DRAM access models to realize an end-to-end system. SIAM is scalable in its support of a wide range of deep neural networks (DNNs), customizable to various network structures and configurations, and capable of efficient design space exploration. We demonstrate the flexibility, scalability, and simulation speed of SIAM by benchmarking different state-of-the-art DNNs with CIFAR-10, CIFAR-100, and ImageNet datasets. We further calibrate the simulation results with a published silicon result, SIMBA. The chiplet-based IMC architecture obtained through SIAM shows 130$\times$ and 72$\times$ improvement in energy-efficiency for ResNet-50 on the ImageNet dataset compared to Nvidia V100 and T4 GPUs.
Underwater inspection and intervention dataset
Jul 28, 2021
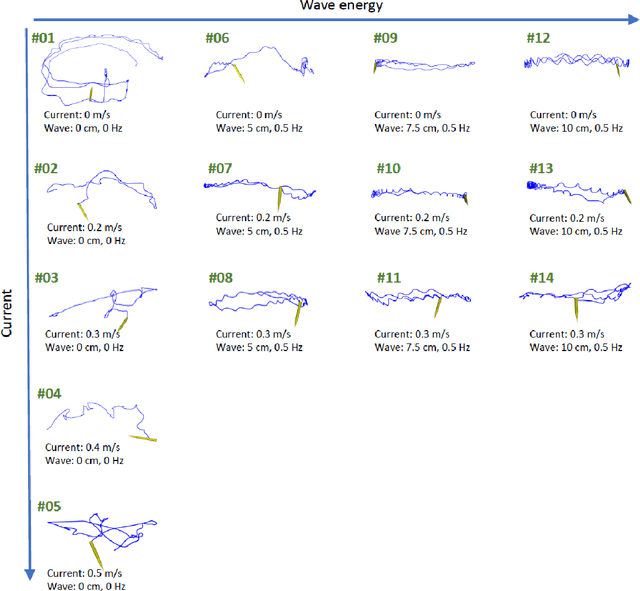
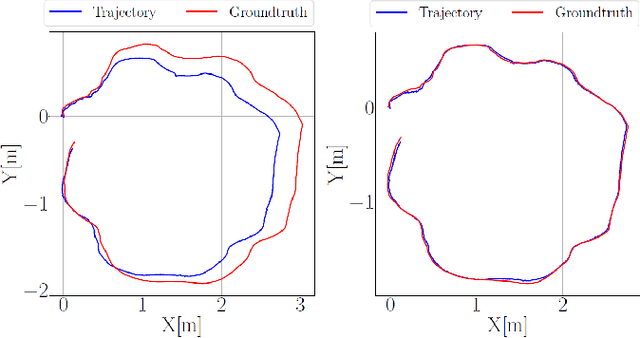

This paper presents a novel dataset for the development of visual navigation and simultaneous localisation and mapping (SLAM) algorithms as well as for underwater intervention tasks. It differs from existing datasets as it contains ground truth for the vehicle's position captured by an underwater motion tracking system. The dataset contains distortion-free and rectified stereo images along with the calibration parameters of the stereo camera setup. Furthermore, the experiments were performed and recorded in a controlled environment, where current and waves could be generated allowing the dataset to cover a wide range of conditions - from calm water to waves and currents of significant strength.
Impact of On-Chip Interconnect on In-Memory Acceleration of Deep Neural Networks
Jul 06, 2021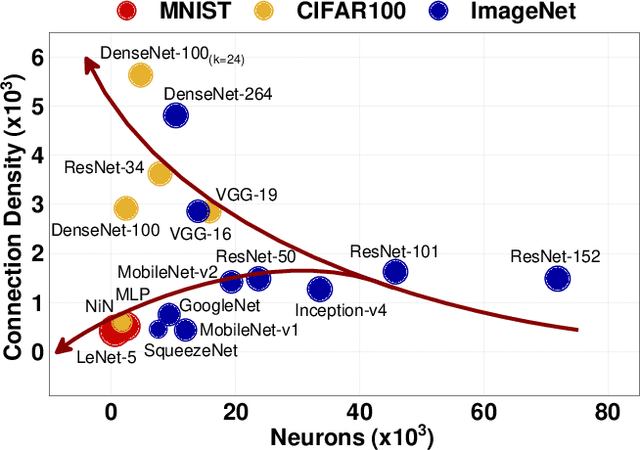
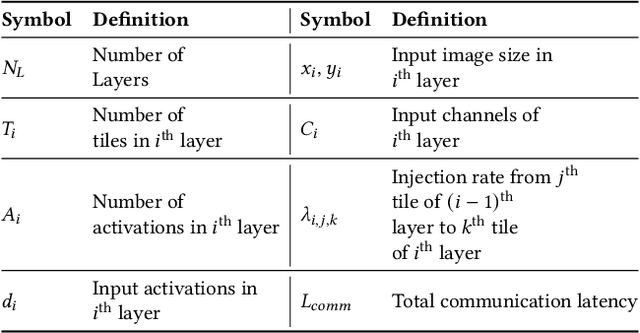
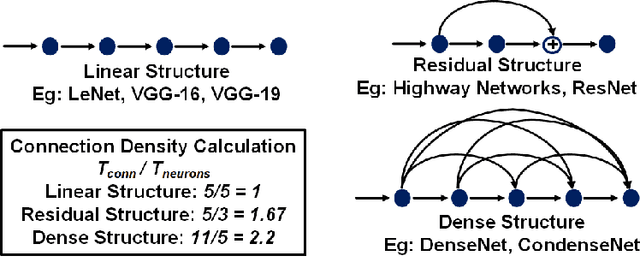

With the widespread use of Deep Neural Networks (DNNs), machine learning algorithms have evolved in two diverse directions -- one with ever-increasing connection density for better accuracy and the other with more compact sizing for energy efficiency. The increase in connection density increases on-chip data movement, which makes efficient on-chip communication a critical function of the DNN accelerator. The contribution of this work is threefold. First, we illustrate that the point-to-point (P2P)-based interconnect is incapable of handling a high volume of on-chip data movement for DNNs. Second, we evaluate P2P and network-on-chip (NoC) interconnect (with a regular topology such as a mesh) for SRAM- and ReRAM-based in-memory computing (IMC) architectures for a range of DNNs. This analysis shows the necessity for the optimal interconnect choice for an IMC DNN accelerator. Finally, we perform an experimental evaluation for different DNNs to empirically obtain the performance of the IMC architecture with both NoC-tree and NoC-mesh. We conclude that, at the tile level, NoC-tree is appropriate for compact DNNs employed at the edge, and NoC-mesh is necessary to accelerate DNNs with high connection density. Furthermore, we propose a technique to determine the optimal choice of interconnect for any given DNN. In this technique, we use analytical models of NoC to evaluate end-to-end communication latency of any given DNN. We demonstrate that the interconnect optimization in the IMC architecture results in up to 6$\times$ improvement in energy-delay-area product for VGG-19 inference compared to the state-of-the-art ReRAM-based IMC architectures.
Alternate Model Growth and Pruning for Efficient Training of Recommendation Systems
May 04, 2021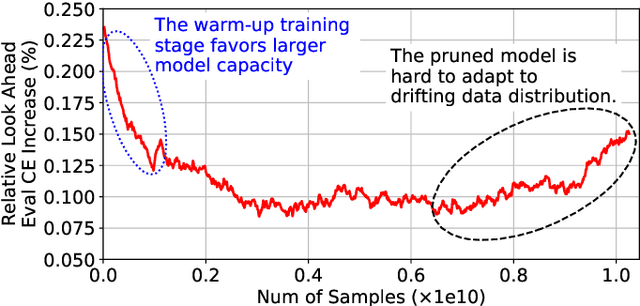

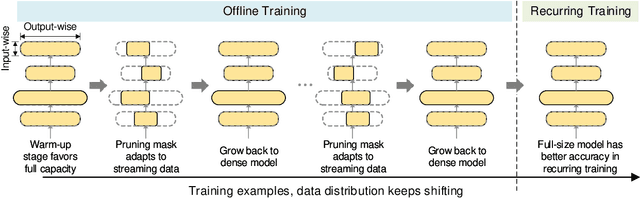

Deep learning recommendation systems at scale have provided remarkable gains through increasing model capacity (i.e. wider and deeper neural networks), but it comes at significant training cost and infrastructure cost. Model pruning is an effective technique to reduce computation overhead for deep neural networks by removing redundant parameters. However, modern recommendation systems are still thirsty for model capacity due to the demand for handling big data. Thus, pruning a recommendation model at scale results in a smaller model capacity and consequently lower accuracy. To reduce computation cost without sacrificing model capacity, we propose a dynamic training scheme, namely alternate model growth and pruning, to alternatively construct and prune weights in the course of training. Our method leverages structured sparsification to reduce computational cost without hurting the model capacity at the end of offline training so that a full-size model is available in the recurring training stage to learn new data in real-time. To the best of our knowledge, this is the first work to provide in-depth experiments and discussion of applying structural dynamics to recommendation systems at scale to reduce training cost. The proposed method is validated with an open-source deep-learning recommendation model (DLRM) and state-of-the-art industrial-scale production models.
CLVSA: A Convolutional LSTM Based Variational Sequence-to-Sequence Model with Attention for Predicting Trends of Financial Markets
Apr 08, 2021

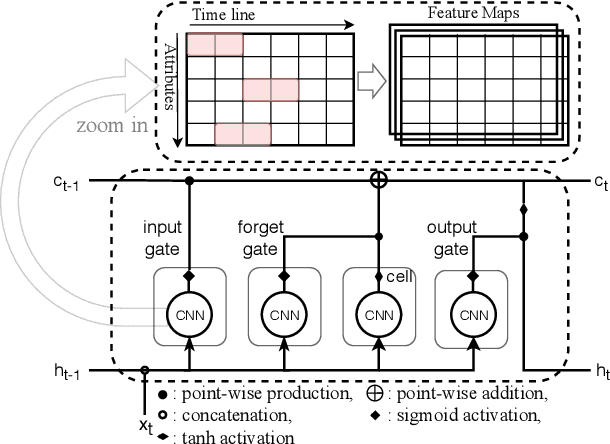
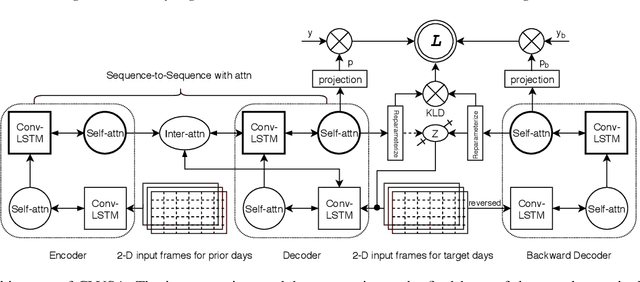
Financial markets are a complex dynamical system. The complexity comes from the interaction between a market and its participants, in other words, the integrated outcome of activities of the entire participants determines the markets trend, while the markets trend affects activities of participants. These interwoven interactions make financial markets keep evolving. Inspired by stochastic recurrent models that successfully capture variability observed in natural sequential data such as speech and video, we propose CLVSA, a hybrid model that consists of stochastic recurrent networks, the sequence-to-sequence architecture, the self- and inter-attention mechanism, and convolutional LSTM units to capture variationally underlying features in raw financial trading data. Our model outperforms basic models, such as convolutional neural network, vanilla LSTM network, and sequence-to-sequence model with attention, based on backtesting results of six futures from January 2010 to December 2017. Our experimental results show that, by introducing an approximate posterior, CLVSA takes advantage of an extra regularizer based on the Kullback-Leibler divergence to prevent itself from overfitting traps.
DAGN: Discourse-Aware Graph Network for Logical Reasoning
Apr 08, 2021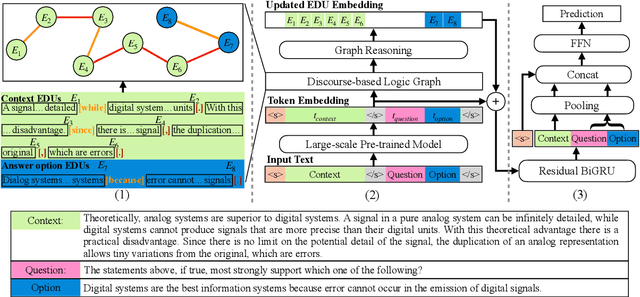
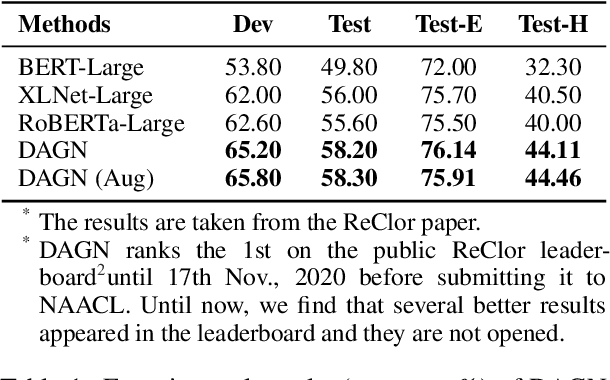
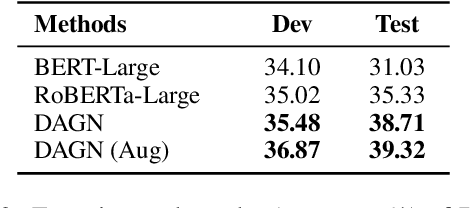

Recent QA with logical reasoning questions requires passage-level relations among the sentences. However, current approaches still focus on sentence-level relations interacting among tokens. In this work, we explore aggregating passage-level clues for solving logical reasoning QA by using discourse-based information. We propose a discourse-aware graph network (DAGN) that reasons relying on the discourse structure of the texts. The model encodes discourse information as a graph with elementary discourse units (EDUs) and discourse relations, and learns the discourse-aware features via a graph network for downstream QA tasks. Experiments are conducted on two logical reasoning QA datasets, ReClor and LogiQA, and our proposed DAGN achieves competitive results. The source code is available at https://github.com/Eleanor-H/DAGN.
Financial Markets Prediction with Deep Learning
Apr 05, 2021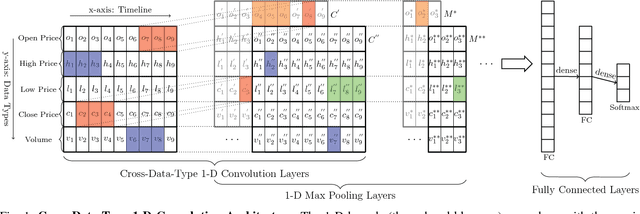
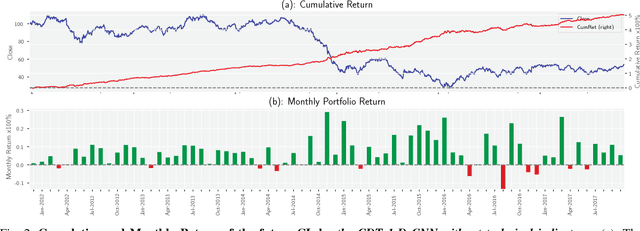
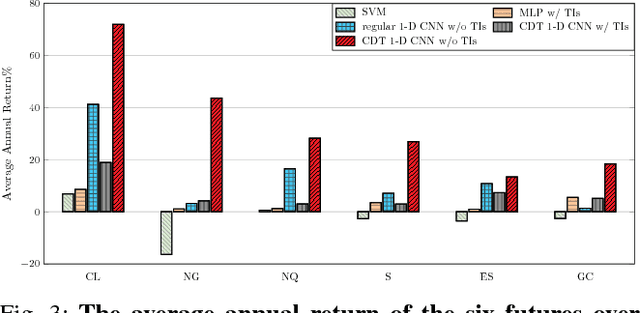
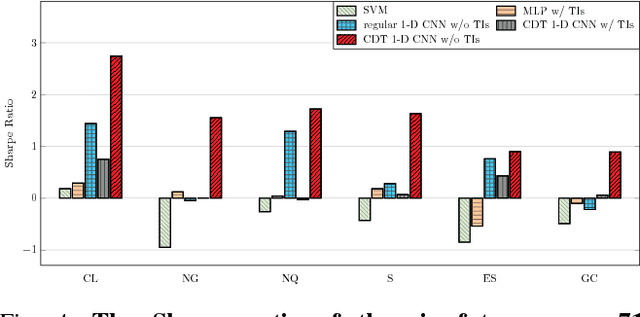
Financial markets are difficult to predict due to its complex systems dynamics. Although there have been some recent studies that use machine learning techniques for financial markets prediction, they do not offer satisfactory performance on financial returns. We propose a novel one-dimensional convolutional neural networks (CNN) model to predict financial market movement. The customized one-dimensional convolutional layers scan financial trading data through time, while different types of data, such as prices and volume, share parameters (kernels) with each other. Our model automatically extracts features instead of using traditional technical indicators and thus can avoid biases caused by selection of technical indicators and pre-defined coefficients in technical indicators. We evaluate the performance of our prediction model with strictly backtesting on historical trading data of six futures from January 2010 to October 2017. The experiment results show that our CNN model can effectively extract more generalized and informative features than traditional technical indicators, and achieves more robust and profitable financial performance than previous machine learning approaches.
RA-BNN: Constructing Robust & Accurate Binary Neural Network to Simultaneously Defend Adversarial Bit-Flip Attack and Improve Accuracy
Mar 22, 2021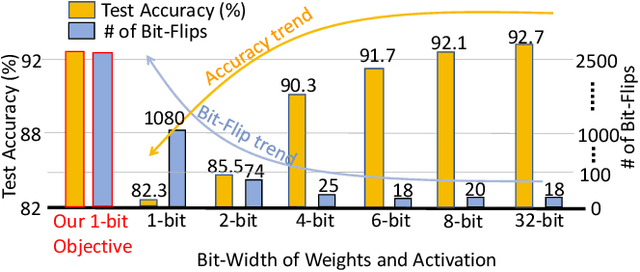
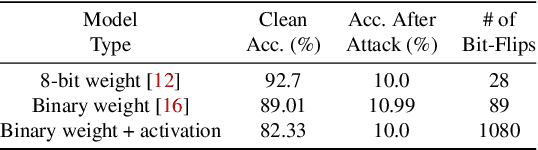
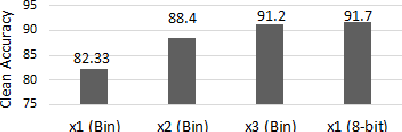

Recently developed adversarial weight attack, a.k.a. bit-flip attack (BFA), has shown enormous success in compromising Deep Neural Network (DNN) performance with an extremely small amount of model parameter perturbation. To defend against this threat, we propose RA-BNN that adopts a complete binary (i.e., for both weights and activation) neural network (BNN) to significantly improve DNN model robustness (defined as the number of bit-flips required to degrade the accuracy to as low as a random guess). However, such an aggressive low bit-width model suffers from poor clean (i.e., no attack) inference accuracy. To counter this, we propose a novel and efficient two-stage network growing method, named Early-Growth. It selectively grows the channel size of each BNN layer based on channel-wise binary masks training with Gumbel-Sigmoid function. Apart from recovering the inference accuracy, our RA-BNN after growing also shows significantly higher resistance to BFA. Our evaluation of the CIFAR-10 dataset shows that the proposed RA-BNN can improve the clean model accuracy by ~2-8 %, compared with a baseline BNN, while simultaneously improving the resistance to BFA by more than 125 x. Moreover, on ImageNet, with a sufficiently large (e.g., 5,000) amount of bit-flips, the baseline BNN accuracy drops to 4.3 % from 51.9 %, while our RA-BNN accuracy only drops to 37.1 % from 60.9 % (9 % clean accuracy improvement).