 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Adapters for Giant Speech Models
Jun 13, 2023



Large pre-trained speech models are widely used as the de-facto paradigm, especially in scenarios when there is a limited amount of labeled data available. However, finetuning all parameters from the self-supervised learned model can be computationally expensive, and becomes infeasiable as the size of the model and the number of downstream tasks scales. In this paper, we propose a novel approach called Two Parallel Adapter (TPA) that is inserted into the conformer-based model pre-trained model instead. TPA is based on systematic studies of the residual adapter, a popular approach for finetuning a subset of parameters. We evaluate TPA on various public benchmarks and experiment results demonstrates its superior performance, which is close to the full finetuning on different datasets and speech tasks. These results show that TPA is an effective and efficient approach for serving large pre-trained speech models. Ablation studies show that TPA can also be pruned, especially for lower blocks.
A Study of Generative Large Language Model for Medical Research and Healthcare
May 22, 2023There is enormous enthusiasm and concerns in using large language models (LLMs) in healthcare, yet current assumptions are all based on general-purpose LLMs such as ChatGPT. This study develops a clinical generative LLM, GatorTronGPT, using 277 billion words of mixed clinical and English text with a GPT-3 architecture of 20 billion parameters. GatorTronGPT improves biomedical natural language processing for medical research. Synthetic NLP models trained using GatorTronGPT generated text outperform NLP models trained using real-world clinical text. Physicians Turing test using 1 (worst) to 9 (best) scale shows that there is no significant difference in linguistic readability (p = 0.22; 6.57 of GatorTronGPT compared with 6.93 of human) and clinical relevance (p = 0.91; 7.0 of GatorTronGPT compared with 6.97 of human) and that physicians cannot differentiate them (p < 0.001). This study provides insights on the opportunities and challenges of LLMs for medical research and healthcare.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Extracting Thyroid Nodules Characteristics from Ultrasound Reports Using Transformer-based Natural Language Processing Methods
Mar 31, 2023



The ultrasound characteristics of thyroid nodules guide the evaluation of thyroid cancer in patients with thyroid nodules. However, the characteristics of thyroid nodules are often documented in clinical narratives such as ultrasound reports. Previous studies have examined natural language processing (NLP) methods in extracting a limited number of characteristics (<9) using rule-based NLP systems. In this study, a multidisciplinary team of NLP experts and thyroid specialists, identified thyroid nodule characteristics that are important for clinical care, composed annotation guidelines, developed a corpus, and compared 5 state-of-the-art transformer-based NLP methods, including BERT, RoBERTa, LongFormer, DeBERTa, and GatorTron, for extraction of thyroid nodule characteristics from ultrasound reports. Our GatorTron model, a transformer-based large language model trained using over 90 billion words of text, achieved the best strict and lenient F1-score of 0.8851 and 0.9495 for the extraction of a total number of 16 thyroid nodule characteristics, and 0.9321 for linking characteristics to nodules, outperforming other clinical transformer models. To the best of our knowledge, this is the first study to systematically categorize and apply transformer-based NLP models to extract a large number of clinical relevant thyroid nodule characteristics from ultrasound reports. This study lays ground for assessing the documentation quality of thyroid ultrasound reports and examining outcomes of patients with thyroid nodules using electronic health records.
Identifying Symptoms of Delirium from Clinical Narratives Using Natural Language Processing
Mar 31, 2023



Delirium is an acute decline or fluctuation in attention, awareness, or other cognitive function that can lead to serious adverse outcomes. Despite the severe outcomes, delirium is frequently unrecognized and uncoded in patients' electronic health records (EHRs) due to its transient and diverse nature. Natural language processing (NLP), a key technology that extracts medical concepts from clinical narratives, has shown great potential in studies of delirium outcomes and symptoms. To assist in the diagnosis and phenotyping of delirium, we formed an expert panel to categorize diverse delirium symptoms, composed annotation guidelines, created a delirium corpus with diverse delirium symptoms, and developed NLP methods to extract delirium symptoms from clinical notes. We compared 5 state-of-the-art transformer models including 2 models (BERT and RoBERTa) from the general domain and 3 models (BERT_MIMIC, RoBERTa_MIMIC, and GatorTron) from the clinical domain. GatorTron achieved the best strict and lenient F1 scores of 0.8055 and 0.8759, respectively. We conducted an error analysis to identify challenges in annotating delirium symptoms and developing NLP systems. To the best of our knowledge, this is the first large language model-based delirium symptom extraction system. Our study lays the foundation for the future development of computable phenotypes and diagnosis methods for delirium.
VILA: Learning Image Aesthetics from User Comments with Vision-Language Pretraining
Mar 24, 2023



Assessing the aesthetics of an image is challenging, as it is influenced by multiple factors including composition, color, style, and high-level semantics. Existing image aesthetic assessment (IAA) methods primarily rely on human-labeled rating scores, which oversimplify the visual aesthetic information that humans perceive. Conversely, user comments offer more comprehensive information and are a more natural way to express human opinions and preferences regarding image aesthetics. In light of this, we propose learning image aesthetics from user comments, and exploring vision-language pretraining methods to learn multimodal aesthetic representations. Specifically, we pretrain an image-text encoder-decoder model with image-comment pairs, using contrastive and generative objectives to learn rich and generic aesthetic semantics without human labels. To efficiently adapt the pretrained model for downstream IAA tasks, we further propose a lightweight rank-based adapter that employs text as an anchor to learn the aesthetic ranking concept. Our results show that our pretrained aesthetic vision-language model outperforms prior works on image aesthetic captioning over the AVA-Captions dataset, and it has powerful zero-shot capability for aesthetic tasks such as zero-shot style classification and zero-shot IAA, surpassing many supervised baselines. With only minimal finetuning parameters using the proposed adapter module, our model achieves state-of-the-art IAA performance over the AVA dataset.
Clinical Concept and Relation Extraction Using Prompt-based Machine Reading Comprehension
Mar 14, 2023



Objective: To develop a natural language processing system that solves both clinical concept extraction and relation extraction in a unified prompt-based machine reading comprehension (MRC) architecture with good generalizability for cross-institution applications. Methods: We formulate both clinical concept extraction and relation extraction using a unified prompt-based MRC architecture and explore state-of-the-art transformer models. We compare our MRC models with existing deep learning models for concept extraction and end-to-end relation extraction using two benchmark datasets developed by the 2018 National NLP Clinical Challenges (n2c2) challenge (medications and adverse drug events) and the 2022 n2c2 challenge (relations of social determinants of health [SDoH]). We also evaluate the transfer learning ability of the proposed MRC models in a cross-institution setting. We perform error analyses and examine how different prompting strategies affect the performance of MRC models. Results and Conclusion: The proposed MRC models achieve state-of-the-art performance for clinical concept and relation extraction on the two benchmark datasets, outperforming previous non-MRC transformer models. GatorTron-MRC achieves the best strict and lenient F1-scores for concept extraction, outperforming previous deep learning models on the two datasets by 1%~3% and 0.7%~1.3%, respectively. For end-to-end relation extraction, GatorTron-MRC and BERT-MIMIC-MRC achieve the best F1-scores, outperforming previous deep learning models by 0.9%~2.4% and 10%-11%, respectively. For cross-institution evaluation, GatorTron-MRC outperforms traditional GatorTron by 6.4% and 16% for the two datasets, respectively. The proposed method is better at handling nested/overlapped concepts, extracting relations, and has good portability for cross-institute applications.
Contextualized Medication Information Extraction Using Transformer-based Deep Learning Architectures
Mar 14, 2023Objective: To develop a natural language processing (NLP) system to extract medications and contextual information that help understand drug changes. This project is part of the 2022 n2c2 challenge. Materials and methods: We developed NLP systems for medication mention extraction, event classification (indicating medication changes discussed or not), and context classification to classify medication changes context into 5 orthogonal dimensions related to drug changes. We explored 6 state-of-the-art pretrained transformer models for the three subtasks, including GatorTron, a large language model pretrained using >90 billion words of text (including >80 billion words from >290 million clinical notes identified at the University of Florida Health). We evaluated our NLP systems using annotated data and evaluation scripts provided by the 2022 n2c2 organizers. Results:Our GatorTron models achieved the best F1-scores of 0.9828 for medication extraction (ranked 3rd), 0.9379 for event classification (ranked 2nd), and the best micro-average accuracy of 0.9126 for context classification. GatorTron outperformed existing transformer models pretrained using smaller general English text and clinical text corpora, indicating the advantage of large language models. Conclusion: This study demonstrated the advantage of using large transformer models for contextual medication information extraction from clinical narratives.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
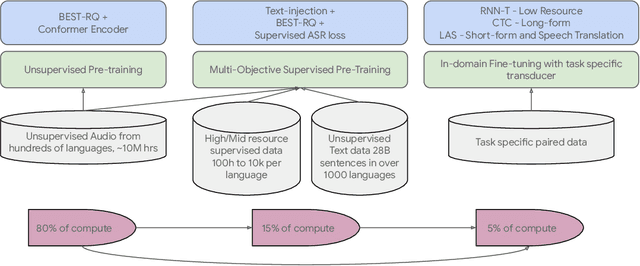
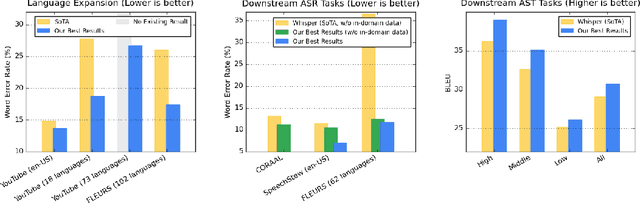

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
AnyTOD: A Programmable Task-Oriented Dialog System
Dec 20, 2022



We propose AnyTOD, an end-to-end task-oriented dialog (TOD) system with zero-shot capability for unseen tasks. We view TOD as a program executed by a language model (LM), where program logic and ontology is provided by a designer in the form of a schema. To enable generalization onto unseen schemas and programs without prior training, AnyTOD adopts a neuro-symbolic approach. A neural LM keeps track of events that occur during a conversation, and a symbolic program implementing the dialog policy is executed to recommend next actions AnyTOD should take. This approach drastically reduces data annotation and model training requirements, addressing a long-standing challenge in TOD research: rapidly adapting a TOD system to unseen tasks and domains. We demonstrate state-of-the-art results on the STAR and ABCD benchmarks, as well as AnyTOD's strong zero-shot transfer capability in low-resource settings. In addition, we release STARv2, an updated version of the STAR dataset with richer data annotations, for benchmarking zero-shot end-to-end TOD models.