 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver-the-Air Federated Learning and Optimization
Oct 16, 2023Federated learning (FL), as an emerging distributed machine learning paradigm, allows a mass of edge devices to collaboratively train a global model while preserving privacy. In this tutorial, we focus on FL via over-the-air computation (AirComp), which is proposed to reduce the communication overhead for FL over wireless networks at the cost of compromising in the learning performance due to model aggregation error arising from channel fading and noise. We first provide a comprehensive study on the convergence of AirComp-based FedAvg (AirFedAvg) algorithms under both strongly convex and non-convex settings with constant and diminishing learning rates in the presence of data heterogeneity. Through convergence and asymptotic analysis, we characterize the impact of aggregation error on the convergence bound and provide insights for system design with convergence guarantees. Then we derive convergence rates for AirFedAvg algorithms for strongly convex and non-convex objectives. For different types of local updates that can be transmitted by edge devices (i.e., local model, gradient, and model difference), we reveal that transmitting local model in AirFedAvg may cause divergence in the training procedure. In addition, we consider more practical signal processing schemes to improve the communication efficiency and further extend the convergence analysis to different forms of model aggregation error caused by these signal processing schemes. Extensive simulation results under different settings of objective functions, transmitted local information, and communication schemes verify the theoretical conclusions.
Towards Scalable Wireless Federated Learning: Challenges and Solutions
Oct 08, 2023



The explosive growth of smart devices (e.g., mobile phones, vehicles, drones) with sensing, communication, and computation capabilities gives rise to an unprecedented amount of data. The generated massive data together with the rapid advancement of machine learning (ML) techniques spark a variety of intelligent applications. To distill intelligence for supporting these applications, federated learning (FL) emerges as an effective distributed ML framework, given its potential to enable privacy-preserving model training at the network edge. In this article, we discuss the challenges and solutions of achieving scalable wireless FL from the perspectives of both network design and resource orchestration. For network design, we discuss how task-oriented model aggregation affects the performance of wireless FL, followed by proposing effective wireless techniques to enhance the communication scalability via reducing the model aggregation distortion and improving the device participation. For resource orchestration, we identify the limitations of the existing optimization-based algorithms and propose three task-oriented learning algorithms to enhance the algorithmic scalability via achieving computation-efficient resource allocation for wireless FL. We highlight several potential research issues that deserve further study.
CT-Net: Arbitrary-Shaped Text Detection via Contour Transformer
Jul 25, 2023



Contour based scene text detection methods have rapidly developed recently, but still suffer from inaccurate frontend contour initialization, multi-stage error accumulation, or deficient local information aggregation. To tackle these limitations, we propose a novel arbitrary-shaped scene text detection framework named CT-Net by progressive contour regression with contour transformers. Specifically, we first employ a contour initialization module that generates coarse text contours without any post-processing. Then, we adopt contour refinement modules to adaptively refine text contours in an iterative manner, which are beneficial for context information capturing and progressive global contour deformation. Besides, we propose an adaptive training strategy to enable the contour transformers to learn more potential deformation paths, and introduce a re-score mechanism that can effectively suppress false positives. Extensive experiments are conducted on four challenging datasets, which demonstrate the accuracy and efficiency of our CT-Net over state-of-the-art methods. Particularly, CT-Net achieves F-measure of 86.1 at 11.2 frames per second (FPS) and F-measure of 87.8 at 10.1 FPS for CTW1500 and Total-Text datasets, respectively.
Integrated Sensing-Communication-Computation for Edge Artificial Intelligence
Jun 01, 2023Edge artificial intelligence (AI) has been a promising solution towards 6G to empower a series of advanced techniques such as digital twin, holographic projection, semantic communications, and auto-driving, for achieving intelligence of everything. The performance of edge AI tasks, including edge learning and edge AI inference, depends on the quality of three highly coupled processes, i.e., sensing for data acquisition, computation for information extraction, and communication for information transmission. However, these three modules need to compete for network resources for enhancing their own quality-of-services. To this end, integrated sensing-communication-computation (ISCC) is of paramount significance for improving resource utilization as well as achieving the customized goals of edge AI tasks. By investigating the interplay among the three modules, this article presents various kinds of ISCC schemes for federated edge learning tasks and edge AI inference tasks in both application and physical layers.
Vertical Federated Learning over Cloud-RAN: Convergence Analysis and System Optimization
May 04, 2023Vertical federated learning (FL) is a collaborative machine learning framework that enables devices to learn a global model from the feature-partition datasets without sharing local raw data. However, as the number of the local intermediate outputs is proportional to the training samples, it is critical to develop communication-efficient techniques for wireless vertical FL to support high-dimensional model aggregation with full device participation. In this paper, we propose a novel cloud radio access network (Cloud-RAN) based vertical FL system to enable fast and accurate model aggregation by leveraging over-the-air computation (AirComp) and alleviating communication straggler issue with cooperative model aggregation among geographically distributed edge servers. However, the model aggregation error caused by AirComp and quantization errors caused by the limited fronthaul capacity degrade the learning performance for vertical FL. To address these issues, we characterize the convergence behavior of the vertical FL algorithm considering both uplink and downlink transmissions. To improve the learning performance, we establish a system optimization framework by joint transceiver and fronthaul quantization design, for which successive convex approximation and alternate convex search based system optimization algorithms are developed. We conduct extensive simulations to demonstrate the effectiveness of the proposed system architecture and optimization framework for vertical FL.
Learning from Stochastic Labels
Feb 01, 2023Annotating multi-class instances is a crucial task in the field of machine learning. Unfortunately, identifying the correct class label from a long sequence of candidate labels is time-consuming and laborious. To alleviate this problem, we design a novel labeling mechanism called stochastic label. In this setting, stochastic label includes two cases: 1) identify a correct class label from a small number of randomly given labels; 2) annotate the instance with None label when given labels do not contain correct class label. In this paper, we propose a novel suitable approach to learn from these stochastic labels. We obtain an unbiased estimator that utilizes less supervised information in stochastic labels to train a multi-class classifier. Additionally, it is theoretically justifiable by deriving the estimation error bound of the proposed method. Finally, we conduct extensive experiments on widely-used benchmark datasets to validate the superiority of our method by comparing it with existing state-of-the-art methods.
Machine Learning for Large-Scale Optimization in 6G Wireless Networks
Jan 03, 2023The sixth generation (6G) wireless systems are envisioned to enable the paradigm shift from "connected things" to "connected intelligence", featured by ultra high density, large-scale, dynamic heterogeneity, diversified functional requirements and machine learning capabilities, which leads to a growing need for highly efficient intelligent algorithms. The classic optimization-based algorithms usually require highly precise mathematical model of data links and suffer from poor performance with high computational cost in realistic 6G applications. Based on domain knowledge (e.g., optimization models and theoretical tools), machine learning (ML) stands out as a promising and viable methodology for many complex large-scale optimization problems in 6G, due to its superior performance, generalizability, computational efficiency and robustness. In this paper, we systematically review the most representative "learning to optimize" techniques in diverse domains of 6G wireless networks by identifying the inherent feature of the underlying optimization problem and investigating the specifically designed ML frameworks from the perspective of optimization. In particular, we will cover algorithm unrolling, learning to branch-and-bound, graph neural network for structured optimization, deep reinforcement learning for stochastic optimization, end-to-end learning for semantic optimization, as well as federated learning for distributed optimization, for solving challenging large-scale optimization problems arising from various important wireless applications. Through the in-depth discussion, we shed light on the excellent performance of ML-based optimization algorithms with respect to the classical methods, and provide insightful guidance to develop advanced ML techniques in 6G networks.
Proximal Gradient-Based Unfolding for Massive Random Access in IoT Networks
Dec 04, 2022



Grant-free random access is an effective technology for enabling low-overhead and low-latency massive access, where joint activity detection and channel estimation (JADCE) is a critical issue. Although existing compressive sensing algorithms can be applied for JADCE, they usually fail to simultaneously harvest the following properties: effective sparsity inducing, fast convergence, robust to different pilot sequences, and adaptive to time-varying networks. To this end, we propose an unfolding framework for JADCE based on the proximal gradient method. Specifically, we formulate the JADCE problem as a group-row-sparse matrix recovery problem and leverage a minimax concave penalty rather than the widely-used $\ell_1$-norm to induce sparsity. We then develop a proximal gradient-based unfolding neural network that parameterizes the algorithmic iterations. To improve convergence rate, we incorporate momentum into the unfolding neural network, and prove the accelerated convergence theoretically. Based on the convergence analysis, we further develop an adaptive-tuning algorithm, which adjusts its parameters to different signal-to-noise ratio settings. Simulations show that the proposed unfolding neural network achieves better recovery performance, convergence rate, and adaptivity than current baselines.
Over-the-Air Computation: Foundations, Technologies, and Applications
Oct 19, 2022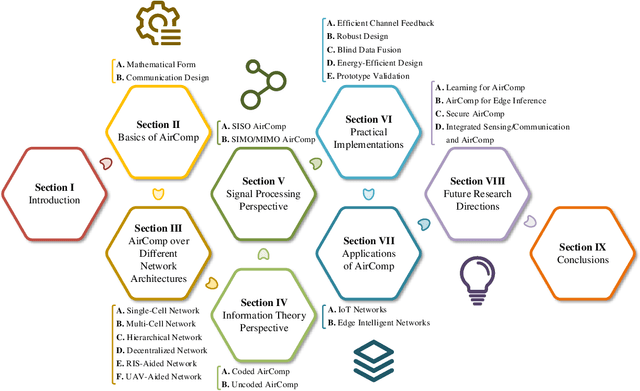
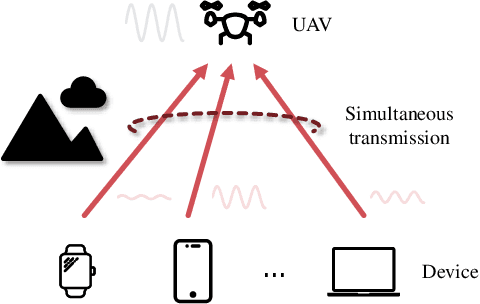
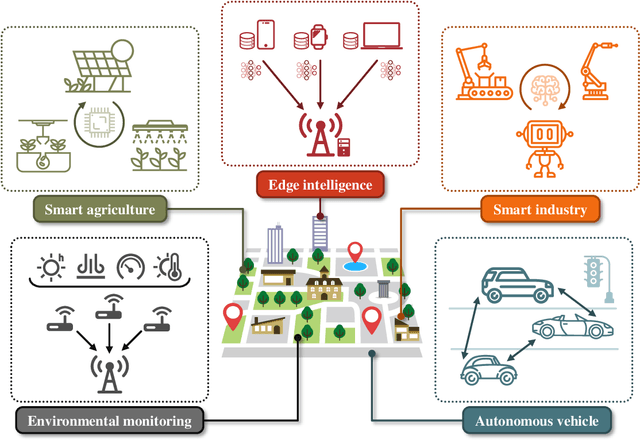
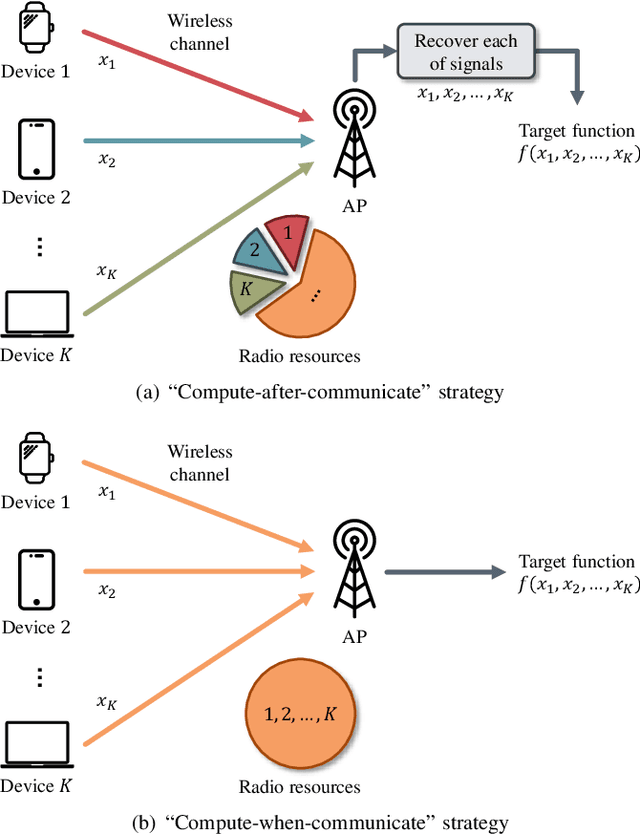
The rapid advancement of artificial intelligence technologies has given rise to diversified intelligent services, which place unprecedented demands on massive connectivity and gigantic data aggregation. However, the scarce radio resources and stringent latency requirement make it challenging to meet these demands. To tackle these challenges, over-the-air computation (AirComp) emerges as a potential technology. Specifically, AirComp seamlessly integrates the communication and computation procedures through the superposition property of multiple-access channels, which yields a revolutionary multiple-access paradigm shift from "compute-after-communicate" to "compute-when-communicate". Meanwhile, low-latency and spectral-efficient wireless data aggregation can be achieved via AirComp by allowing multiple devices to access the wireless channels non-orthogonally. In this paper, we aim to present the recent advancement of AirComp in terms of foundations, technologies, and applications. The mathematical form and communication design are introduced as the foundations of AirComp, and the critical issues of AirComp over different network architectures are then discussed along with the review of existing literature. The technologies employed for the analysis and optimization on AirComp are reviewed from the information theory and signal processing perspectives. Moreover, we present the existing studies that tackle the practical implementation issues in AirComp systems, and elaborate the applications of AirComp in Internet of Things and edge intelligent networks. Finally, potential research directions are highlighted to motivate the future development of AirComp.
Class-Imbalanced Complementary-Label Learning via Weighted Loss
Sep 28, 2022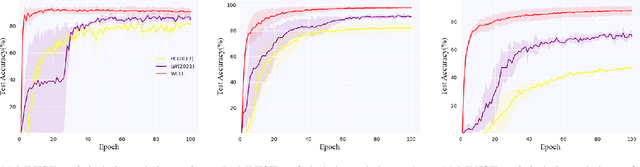
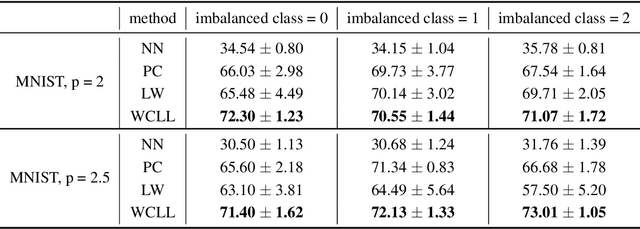
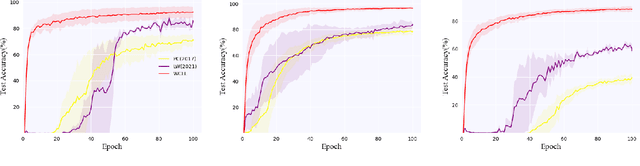
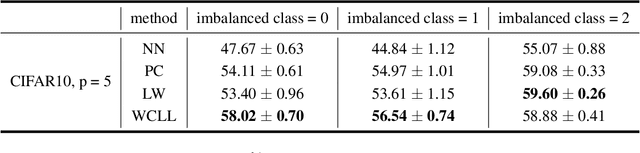
Complementary-label learning (CLL) is a common application in the scenario of weak supervision. However, in real-world datasets, CLL encounters class-imbalanced training samples, where the quantity of samples of one class is significantly lower than those of other classes. Unfortunately, existing CLL approaches have yet to explore the problem of class-imbalanced samples, which reduces the prediction accuracy, especially in imbalanced classes. In this paper, we propose a novel problem setting to allow learning from class-imbalanced complementarily labeled samples for multi-class classification. Accordingly, to deal with this novel problem, we propose a new CLL approach, called Weighted Complementary-Label Learning (WCLL). The proposed method models a weighted empirical risk minimization loss by utilizing the class-imbalanced complementarily labeled information, which is also applicable to multi-class imbalanced training samples. Furthermore, the estimation error bound of the proposed method was derived to provide a theoretical guarantee. Finally, we do extensive experiments on widely-used benchmark datasets to validate the superiority of our method by comparing it with existing state-of-the-art methods.