 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Calibration: Plug-and-play Content-Preserving Video Enhancement using Pre-trained Video Diffusion Models
Jul 14, 2024



In order to improve the quality of synthesized videos, currently, one predominant method involves retraining an expert diffusion model and then implementing a noising-denoising process for refinement. Despite the significant training costs, maintaining consistency of content between the original and enhanced videos remains a major challenge. To tackle this challenge, we propose a novel formulation that considers both visual quality and consistency of content. Consistency of content is ensured by a proposed loss function that maintains the structure of the input, while visual quality is improved by utilizing the denoising process of pretrained diffusion models. To address the formulated optimization problem, we have developed a plug-and-play noise optimization strategy, referred to as Noise Calibration. By refining the initial random noise through a few iterations, the content of original video can be largely preserved, and the enhancement effect demonstrates a notable improvement. Extensive experiments have demonstrated the effectiveness of the proposed method.
Multi-task multi-constraint differential evolution with elite-guided knowledge transfer for coal mine integrated energy system dispatching
Jun 29, 2024The dispatch optimization of coal mine integrated energy system is challenging due to high dimensionality, strong coupling constraints, and multiobjective. Existing constrained multiobjective evolutionary algorithms struggle with locating multiple small and irregular feasible regions, making them inaplicable to this problem. To address this issue, we here develop a multitask evolutionary algorithm framework that incorporates the dispatch correlated domain knowledge to effectively deal with strong constraints and multiobjective optimization. Possible evolutionary multitask construction strategy based on complex constraint relationship analysis and handling, i.e., constraint coupled spatial decomposition, constraint strength classification and constraint handling technique, is first explored. Within the multitask evolutionary optimization framework, two strategies, i.e., an elite guided knowledge transfer by designing a special crowding distance mechanism to select dominant individuals from each task, and an adaptive neighborhood technology based mutation to effectively balance the diversity and convergence of each optimized task for the differential evolution algorithm, are further developed. The performance of the proposed algorithm in feasibility, convergence, and diversity is demonstrated in a case study of a coal mine integrated energy system by comparing with CPLEX solver and seven constrained multiobjective evolutionary algorithms.
PFID: Privacy First Inference Delegation Framework for LLMs
Jun 18, 2024



This paper introduces a novel privacy-preservation framework named PFID for LLMs that addresses critical privacy concerns by localizing user data through model sharding and singular value decomposition. When users are interacting with LLM systems, their prompts could be subject to being exposed to eavesdroppers within or outside LLM system providers who are interested in collecting users' input. In this work, we proposed a framework to camouflage user input, so as to alleviate privacy issues. Our framework proposes to place model shards on the client and the public server, we sent compressed hidden states instead of prompts to and from servers. Clients have held back information that can re-privatized the hidden states so that overall system performance is comparable to traditional LLMs services. Our framework was designed to be communication efficient, computation can be delegated to the local client so that the server's computation burden can be lightened. We conduct extensive experiments on machine translation tasks to verify our framework's performance.
DeTriever: Decoder-representation-based Retriever for Improving NL2SQL In-Context Learning
Jun 12, 2024



While in-context Learning (ICL) has proven to be an effective technique to improve the performance of Large Language Models (LLMs) in a variety of complex tasks, notably in translating natural language questions into Structured Query Language (NL2SQL), the question of how to select the most beneficial demonstration examples remains an open research problem. While prior works often adapted off-the-shelf encoders to retrieve examples dynamically, an inherent discrepancy exists in the representational capacities between the external retrievers and the LLMs. Further, optimizing the selection of examples is a non-trivial task, since there are no straightforward methods to assess the relative benefits of examples without performing pairwise inference. To address these shortcomings, we propose DeTriever, a novel demonstration retrieval framework that learns a weighted combination of LLM hidden states, where rich semantic information is encoded. To train the model, we propose a proxy score that estimates the relative benefits of examples based on the similarities between output queries. Experiments on two popular NL2SQL benchmarks demonstrate that our method significantly outperforms the state-of-the-art baselines on one-shot NL2SQL tasks.
A Combination Model for Time Series Prediction using LSTM via Extracting Dynamic Features Based on Spatial Smoothing and Sequential General Variational Mode Decomposition
Jun 05, 2024



In order to solve the problems such as difficult to extract effective features and low accuracy of sales volume prediction caused by complex relationships such as market sales volume in time series prediction, we proposed a time series prediction method of market sales volume based on Sequential General VMD and spatial smoothing Long short-term memory neural network (SS-LSTM) combination model. Firstly, the spatial smoothing algorithm is used to decompose and calculate the sample data of related industry sectors affected by the linkage effect of market sectors, extracting modal features containing information via Sequential General VMD on overall market and specific price trends; Then, according to the background of different Market data sets, LSTM network is used to model and predict the price of fundamental data and modal characteristics. The experimental results of data prediction with seasonal and periodic trends show that this method can achieve higher price prediction accuracy and more accurate accuracy in specific market contexts compared to traditional prediction methods Describe the changes in market sales volume.
ZeroSmooth: Training-free Diffuser Adaptation for High Frame Rate Video Generation
Jun 03, 2024



Video generation has made remarkable progress in recent years, especially since the advent of the video diffusion models. Many video generation models can produce plausible synthetic videos, e.g., Stable Video Diffusion (SVD). However, most video models can only generate low frame rate videos due to the limited GPU memory as well as the difficulty of modeling a large set of frames. The training videos are always uniformly sampled at a specified interval for temporal compression. Previous methods promote the frame rate by either training a video interpolation model in pixel space as a postprocessing stage or training an interpolation model in latent space for a specific base video model. In this paper, we propose a training-free video interpolation method for generative video diffusion models, which is generalizable to different models in a plug-and-play manner. We investigate the non-linearity in the feature space of video diffusion models and transform a video model into a self-cascaded video diffusion model with incorporating the designed hidden state correction modules. The self-cascaded architecture and the correction module are proposed to retain the temporal consistency between key frames and the interpolated frames. Extensive evaluations are preformed on multiple popular video models to demonstrate the effectiveness of the propose method, especially that our training-free method is even comparable to trained interpolation models supported by huge compute resources and large-scale datasets.
MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model
Jun 02, 2024



We present MOFA-Video, an advanced controllable image animation method that generates video from the given image using various additional controllable signals (such as human landmarks reference, manual trajectories, and another even provided video) or their combinations. This is different from previous methods which only can work on a specific motion domain or show weak control abilities with diffusion prior. To achieve our goal, we design several domain-aware motion field adapters (\ie, MOFA-Adapters) to control the generated motions in the video generation pipeline. For MOFA-Adapters, we consider the temporal motion consistency of the video and generate the dense motion flow from the given sparse control conditions first, and then, the multi-scale features of the given image are wrapped as a guided feature for stable video diffusion generation. We naively train two motion adapters for the manual trajectories and the human landmarks individually since they both contain sparse information about the control. After training, the MOFA-Adapters in different domains can also work together for more controllable video generation. Project Page: https://myniuuu.github.io/MOFA_Video/
Research on Foundation Model for Spatial Data Intelligence: China's 2024 White Paper on Strategic Development of Spatial Data Intelligence
May 30, 2024This report focuses on spatial data intelligent large models, delving into the principles, methods, and cutting-edge applications of these models. It provides an in-depth discussion on the definition, development history, current status, and trends of spatial data intelligent large models, as well as the challenges they face. The report systematically elucidates the key technologies of spatial data intelligent large models and their applications in urban environments, aerospace remote sensing, geography, transportation, and other scenarios. Additionally, it summarizes the latest application cases of spatial data intelligent large models in themes such as urban development, multimodal systems, remote sensing, smart transportation, and resource environments. Finally, the report concludes with an overview and outlook on the development prospects of spatial data intelligent large models.
CV-VAE: A Compatible Video VAE for Latent Generative Video Models
May 30, 2024Spatio-temporal compression of videos, utilizing networks such as Variational Autoencoders (VAE), plays a crucial role in OpenAI's SORA and numerous other video generative models. For instance, many LLM-like video models learn the distribution of discrete tokens derived from 3D VAEs within the VQVAE framework, while most diffusion-based video models capture the distribution of continuous latent extracted by 2D VAEs without quantization. The temporal compression is simply realized by uniform frame sampling which results in unsmooth motion between consecutive frames. Currently, there lacks of a commonly used continuous video (3D) VAE for latent diffusion-based video models in the research community. Moreover, since current diffusion-based approaches are often implemented using pre-trained text-to-image (T2I) models, directly training a video VAE without considering the compatibility with existing T2I models will result in a latent space gap between them, which will take huge computational resources for training to bridge the gap even with the T2I models as initialization. To address this issue, we propose a method for training a video VAE of latent video models, namely CV-VAE, whose latent space is compatible with that of a given image VAE, e.g., image VAE of Stable Diffusion (SD). The compatibility is achieved by the proposed novel latent space regularization, which involves formulating a regularization loss using the image VAE. Benefiting from the latent space compatibility, video models can be trained seamlessly from pre-trained T2I or video models in a truly spatio-temporally compressed latent space, rather than simply sampling video frames at equal intervals. With our CV-VAE, existing video models can generate four times more frames with minimal finetuning. Extensive experiments are conducted to demonstrate the effectiveness of the proposed video VAE.
Reasoning3D -- Grounding and Reasoning in 3D: Fine-Grained Zero-Shot Open-Vocabulary 3D Reasoning Part Segmentation via Large Vision-Language Models
May 29, 2024


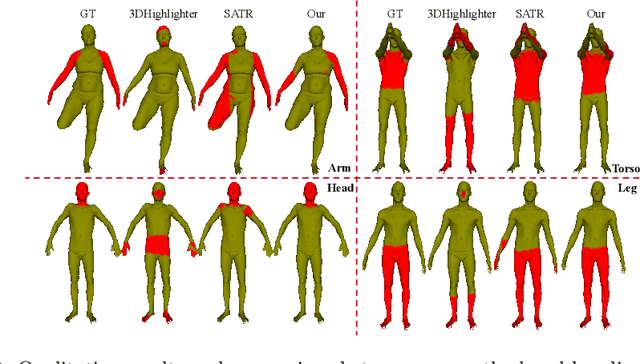
In this paper, we introduce a new task: Zero-Shot 3D Reasoning Segmentation for parts searching and localization for objects, which is a new paradigm to 3D segmentation that transcends limitations for previous category-specific 3D semantic segmentation, 3D instance segmentation, and open-vocabulary 3D segmentation. We design a simple baseline method, Reasoning3D, with the capability to understand and execute complex commands for (fine-grained) segmenting specific parts for 3D meshes with contextual awareness and reasoned answers for interactive segmentation. Specifically, Reasoning3D leverages an off-the-shelf pre-trained 2D segmentation network, powered by Large Language Models (LLMs), to interpret user input queries in a zero-shot manner. Previous research have shown that extensive pre-training endows foundation models with prior world knowledge, enabling them to comprehend complex commands, a capability we can harness to "segment anything" in 3D with limited 3D datasets (source efficient). Experimentation reveals that our approach is generalizable and can effectively localize and highlight parts of 3D objects (in 3D mesh) based on implicit textual queries, including these articulated 3d objects and real-world scanned data. Our method can also generate natural language explanations corresponding to these 3D models and the decomposition. Moreover, our training-free approach allows rapid deployment and serves as a viable universal baseline for future research of part-level 3d (semantic) object understanding in various fields including robotics, object manipulation, part assembly, autonomous driving applications, augment reality and virtual reality (AR/VR), and medical applications. The code, the model weight, the deployment guide, and the evaluation protocol are: http://tianrun-chen.github.io/Reason3D/