 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeMoGen: Towards Decompositional Human Motion Generation with Energy-Based Diffusion Models
Dec 26, 2025Human motions are compositional: complex behaviors can be described as combinations of simpler primitives. However, existing approaches primarily focus on forward modeling, e.g., learning holistic mappings from text to motion or composing a complex motion from a set of motion concepts. In this paper, we consider the inverse perspective: decomposing a holistic motion into semantically meaningful sub-components. We propose DeMoGen, a compositional training paradigm for decompositional learning that employs an energy-based diffusion model. This energy formulation directly captures the composed distribution of multiple motion concepts, enabling the model to discover them without relying on ground-truth motions for individual concepts. Within this paradigm, we introduce three training variants to encourage a decompositional understanding of motion: 1. DeMoGen-Exp explicitly trains on decomposed text prompts; 2. DeMoGen-OSS performs orthogonal self-supervised decomposition; 3. DeMoGen-SC enforces semantic consistency between original and decomposed text embeddings. These variants enable our approach to disentangle reusable motion primitives from complex motion sequences. We also demonstrate that the decomposed motion concepts can be flexibly recombined to generate diverse and novel motions, generalizing beyond the training distribution. Additionally, we construct a text-decomposed dataset to support compositional training, serving as an extended resource to facilitate text-to-motion generation and motion composition.
EnergyMoGen: Compositional Human Motion Generation with Energy-Based Diffusion Model in Latent Space
Dec 19, 2024Diffusion models, particularly latent diffusion models, have demonstrated remarkable success in text-driven human motion generation. However, it remains challenging for latent diffusion models to effectively compose multiple semantic concepts into a single, coherent motion sequence. To address this issue, we propose EnergyMoGen, which includes two spectrums of Energy-Based Models: (1) We interpret the diffusion model as a latent-aware energy-based model that generates motions by composing a set of diffusion models in latent space; (2) We introduce a semantic-aware energy model based on cross-attention, which enables semantic composition and adaptive gradient descent for text embeddings. To overcome the challenges of semantic inconsistency and motion distortion across these two spectrums, we introduce Synergistic Energy Fusion. This design allows the motion latent diffusion model to synthesize high-quality, complex motions by combining multiple energy terms corresponding to textual descriptions. Experiments show that our approach outperforms existing state-of-the-art models on various motion generation tasks, including text-to-motion generation, compositional motion generation, and multi-concept motion generation. Additionally, we demonstrate that our method can be used to extend motion datasets and improve the text-to-motion task.
CktGen: Specification-Conditioned Analog Circuit Generation
Oct 01, 2024



Automatic synthesis of analog circuits presents significant challenges. Existing methods usually treat the task as optimization problems, which limits their transferability and reusability for new requirements. To address this limitation, we introduce a task that directly generates analog circuits based on specified specifications, termed specification-conditioned analog circuit generation. Specifically, we propose CktGen, a simple yet effective variational autoencoder (VAE) model, that maps specifications and circuits into a joint latent space, and reconstructs the circuit from the latent. Moreover, given that a single specification can correspond to multiple distinct circuits, simply minimizing the distance between the mapped latent representations of the circuit and specification does not capture these one-to-many relationships. To address this, we integrate contrastive learning and classifier guidance to prevent model collapse. We conduct comprehensive experiments on the Open Circuit Benchmark (OCB) and introduce new evaluation metrics for cross-model consistency in the specification-to-circuit generation task. Experimental results demonstrate substantial improvements over existing state-of-the-art methods.
DoLLM: How Large Language Models Understanding Network Flow Data to Detect Carpet Bombing DDoS
May 13, 2024



It is an interesting question Can and How Large Language Models (LLMs) understand non-language network data, and help us detect unknown malicious flows. This paper takes Carpet Bombing as a case study and shows how to exploit LLMs' powerful capability in the networking area. Carpet Bombing is a new DDoS attack that has dramatically increased in recent years, significantly threatening network infrastructures. It targets multiple victim IPs within subnets, causing congestion on access links and disrupting network services for a vast number of users. Characterized by low-rates, multi-vectors, these attacks challenge traditional DDoS defenses. We propose DoLLM, a DDoS detection model utilizes open-source LLMs as backbone. By reorganizing non-contextual network flows into Flow-Sequences and projecting them into LLMs semantic space as token embeddings, DoLLM leverages LLMs' contextual understanding to extract flow representations in overall network context. The representations are used to improve the DDoS detection performance. We evaluate DoLLM with public datasets CIC-DDoS2019 and real NetFlow trace from Top-3 countrywide ISP. The tests have proven that DoLLM possesses strong detection capabilities. Its F1 score increased by up to 33.3% in zero-shot scenarios and by at least 20.6% in real ISP traces.
Hand-Centric Motion Refinement for 3D Hand-Object Interaction via Hierarchical Spatial-Temporal Modeling
Jan 29, 2024Hands are the main medium when people interact with the world. Generating proper 3D motion for hand-object interaction is vital for applications such as virtual reality and robotics. Although grasp tracking or object manipulation synthesis can produce coarse hand motion, this kind of motion is inevitably noisy and full of jitter. To address this problem, we propose a data-driven method for coarse motion refinement. First, we design a hand-centric representation to describe the dynamic spatial-temporal relation between hands and objects. Compared to the object-centric representation, our hand-centric representation is straightforward and does not require an ambiguous projection process that converts object-based prediction into hand motion. Second, to capture the dynamic clues of hand-object interaction, we propose a new architecture that models the spatial and temporal structure in a hierarchical manner. Extensive experiments demonstrate that our method outperforms previous methods by a noticeable margin.
T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations
Jan 18, 2023



In this work, we investigate a simple and must-known conditional generative framework based on Vector Quantised-Variational AutoEncoder (VQ-VAE) and Generative Pre-trained Transformer (GPT) for human motion generation from textural descriptions. We show that a simple CNN-based VQ-VAE with commonly used training recipes (EMA and Code Reset) allows us to obtain high-quality discrete representations. For GPT, we incorporate a simple corruption strategy during the training to alleviate training-testing discrepancy. Despite its simplicity, our T2M-GPT shows better performance than competitive approaches, including recent diffusion-based approaches. For example, on HumanML3D, which is currently the largest dataset, we achieve comparable performance on the consistency between text and generated motion (R-Precision), but with FID 0.116 largely outperforming MotionDiffuse of 0.630. Additionally, we conduct analyses on HumanML3D and observe that the dataset size is a limitation of our approach. Our work suggests that VQ-VAE still remains a competitive approach for human motion generation.
Region-level Contrastive and Consistency Learning for Semi-Supervised Semantic Segmentation
Apr 28, 2022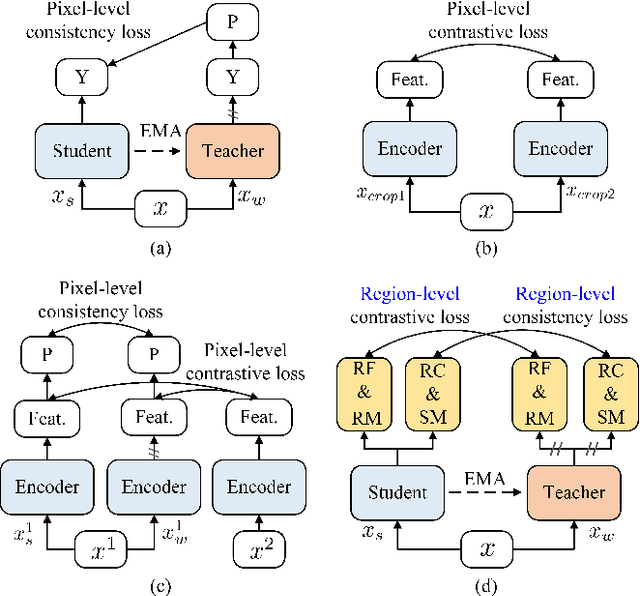
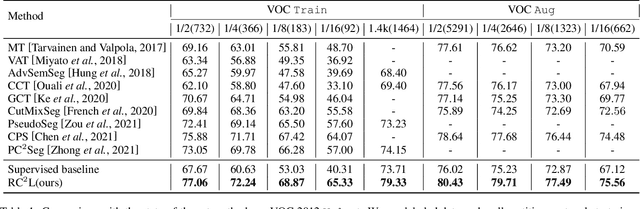
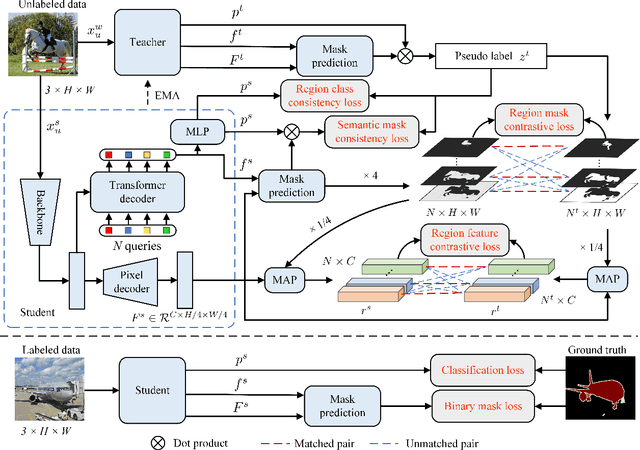
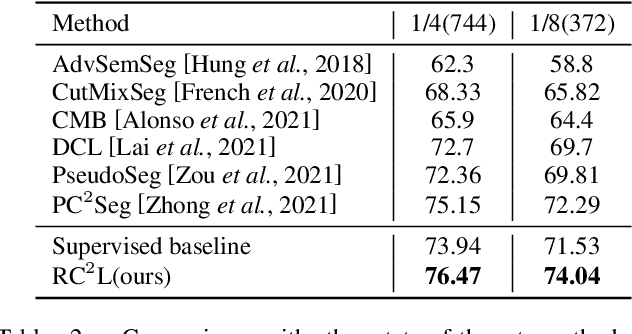
Current semi-supervised semantic segmentation methods mainly focus on designing pixel-level consistency and contrastive regularization. However, pixel-level regularization is sensitive to noise from pixels with incorrect predictions, and pixel-level contrastive regularization has memory and computational cost with O(pixel_num^2). To address the issues, we propose a novel region-level contrastive and consistency learning framework (RC^2L) for semi-supervised semantic segmentation. Specifically, we first propose a Region Mask Contrastive (RMC) loss and a Region Feature Contrastive (RFC) loss to accomplish region-level contrastive property. Furthermore, Region Class Consistency (RCC) loss and Semantic Mask Consistency (SMC) loss are proposed for achieving region-level consistency. Based on the proposed region-level contrastive and consistency regularization, we develop a region-level contrastive and consistency learning framework (RC^2L) for semi-supervised semantic segmentation, and evaluate our RC$^2$L on two challenging benchmarks (PASCAL VOC 2012 and Cityscapes), outperforming the state-of-the-art.