 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Layer Removal: Preserving Critical Components with Task-Aware Singular Value Decomposition
Dec 31, 2024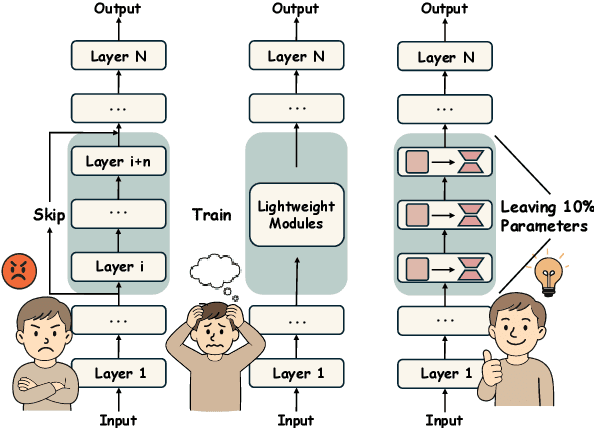



Layer removal has emerged as a promising approach for compressing large language models (LLMs) by leveraging redundancy within layers to reduce model size and accelerate inference. However, this technique often compromises internal consistency, leading to performance degradation and instability, with varying impacts across different model architectures. In this work, we propose Taco-SVD, a task-aware framework that retains task-critical singular value directions, preserving internal consistency while enabling efficient compression. Unlike direct layer removal, Taco-SVD preserves task-critical transformations to mitigate performance degradation. By leveraging gradient-based attribution methods, Taco-SVD aligns singular values with downstream task objectives. Extensive evaluations demonstrate that Taco-SVD outperforms existing methods in perplexity and task performance across different architectures while ensuring minimal computational overhead.
VideoMaker: Zero-shot Customized Video Generation with the Inherent Force of Video Diffusion Models
Dec 27, 2024



Zero-shot customized video generation has gained significant attention due to its substantial application potential. Existing methods rely on additional models to extract and inject reference subject features, assuming that the Video Diffusion Model (VDM) alone is insufficient for zero-shot customized video generation. However, these methods often struggle to maintain consistent subject appearance due to suboptimal feature extraction and injection techniques. In this paper, we reveal that VDM inherently possesses the force to extract and inject subject features. Departing from previous heuristic approaches, we introduce a novel framework that leverages VDM's inherent force to enable high-quality zero-shot customized video generation. Specifically, for feature extraction, we directly input reference images into VDM and use its intrinsic feature extraction process, which not only provides fine-grained features but also significantly aligns with VDM's pre-trained knowledge. For feature injection, we devise an innovative bidirectional interaction between subject features and generated content through spatial self-attention within VDM, ensuring that VDM has better subject fidelity while maintaining the diversity of the generated video.Experiments on both customized human and object video generation validate the effectiveness of our framework.
DiTCtrl: Exploring Attention Control in Multi-Modal Diffusion Transformer for Tuning-Free Multi-Prompt Longer Video Generation
Dec 24, 2024



Sora-like video generation models have achieved remarkable progress with a Multi-Modal Diffusion Transformer MM-DiT architecture. However, the current video generation models predominantly focus on single-prompt, struggling to generate coherent scenes with multiple sequential prompts that better reflect real-world dynamic scenarios. While some pioneering works have explored multi-prompt video generation, they face significant challenges including strict training data requirements, weak prompt following, and unnatural transitions. To address these problems, we propose DiTCtrl, a training-free multi-prompt video generation method under MM-DiT architectures for the first time. Our key idea is to take the multi-prompt video generation task as temporal video editing with smooth transitions. To achieve this goal, we first analyze MM-DiT's attention mechanism, finding that the 3D full attention behaves similarly to that of the cross/self-attention blocks in the UNet-like diffusion models, enabling mask-guided precise semantic control across different prompts with attention sharing for multi-prompt video generation. Based on our careful design, the video generated by DiTCtrl achieves smooth transitions and consistent object motion given multiple sequential prompts without additional training. Besides, we also present MPVBench, a new benchmark specially designed for multi-prompt video generation to evaluate the performance of multi-prompt generation. Extensive experiments demonstrate that our method achieves state-of-the-art performance without additional training.
CustomTTT: Motion and Appearance Customized Video Generation via Test-Time Training
Dec 23, 2024Benefiting from large-scale pre-training of text-video pairs, current text-to-video (T2V) diffusion models can generate high-quality videos from the text description. Besides, given some reference images or videos, the parameter-efficient fine-tuning method, i.e. LoRA, can generate high-quality customized concepts, e.g., the specific subject or the motions from a reference video. However, combining the trained multiple concepts from different references into a single network shows obvious artifacts. To this end, we propose CustomTTT, where we can joint custom the appearance and the motion of the given video easily. In detail, we first analyze the prompt influence in the current video diffusion model and find the LoRAs are only needed for the specific layers for appearance and motion customization. Besides, since each LoRA is trained individually, we propose a novel test-time training technique to update parameters after combination utilizing the trained customized models. We conduct detailed experiments to verify the effectiveness of the proposed methods. Our method outperforms several state-of-the-art works in both qualitative and quantitative evaluations.
Evaluating LLM Reasoning in the Operations Research Domain with ORQA
Dec 22, 2024



In this paper, we introduce and apply Operations Research Question Answering (ORQA), a new benchmark designed to assess the generalization capabilities of Large Language Models (LLMs) in the specialized technical domain of Operations Research (OR). This benchmark evaluates whether LLMs can emulate the knowledge and reasoning skills of OR experts when confronted with diverse and complex optimization problems. The dataset, developed by OR experts, features real-world optimization problems that demand multistep reasoning to construct their mathematical models. Our evaluations of various open source LLMs, such as LLaMA 3.1, DeepSeek, and Mixtral, reveal their modest performance, highlighting a gap in their ability to generalize to specialized technical domains. This work contributes to the ongoing discourse on LLMs generalization capabilities, offering valuable insights for future research in this area. The dataset and evaluation code are publicly available.
Task-Agnostic Language Model Watermarking via High Entropy Passthrough Layers
Dec 17, 2024In the era of costly pre-training of large language models, ensuring the intellectual property rights of model owners, and insuring that said models are responsibly deployed, is becoming increasingly important. To this end, we propose model watermarking via passthrough layers, which are added to existing pre-trained networks and trained using a self-supervised loss such that the model produces high-entropy output when prompted with a unique private key, and acts normally otherwise. Unlike existing model watermarking methods, our method is fully task-agnostic, and can be applied to both classification and sequence-to-sequence tasks without requiring advanced access to downstream fine-tuning datasets. We evaluate the proposed passthrough layers on a wide range of downstream tasks, and show experimentally our watermarking method achieves a near-perfect watermark extraction accuracy and false-positive rate in most cases without damaging original model performance. Additionally, we show our method is robust to both downstream fine-tuning, fine-pruning, and layer removal attacks, and can be trained in a fraction of the time required to train the original model. Code is available in the paper.
A Data-Driven Framework for Discovering Fractional Differential Equations in Complex Systems
Dec 05, 2024



In complex physical systems, conventional differential equations often fall short in capturing non-local and memory effects, as they are limited to local dynamics and integer-order interactions. This study introduces a stepwise data-driven framework for discovering fractional differential equations (FDEs) directly from data. FDEs, known for their capacity to model non-local dynamics with fewer parameters than integer-order derivatives, can represent complex systems with long-range interactions. Our framework applies deep neural networks as surrogate models for denoising and reconstructing sparse and noisy observations while using Gaussian-Jacobi quadrature to handle the challenges posed by singularities in fractional derivatives. To optimize both the sparse coefficients and fractional order, we employ an alternating optimization approach that combines sparse regression with global optimization techniques. We validate the framework across various datasets, including synthetic anomalous diffusion data, experimental data on the creep behavior of frozen soils, and single-particle trajectories modeled by L\'{e}vy motion. Results demonstrate the framework's robustness in identifying the structure of FDEs across diverse noise levels and its capacity to capture integer-order dynamics, offering a flexible approach for modeling memory effects in complex systems.
AnchorCrafter: Animate CyberAnchors Saling Your Products via Human-Object Interacting Video Generation
Nov 26, 2024



The automatic generation of anchor-style product promotion videos presents promising opportunities in online commerce, advertising, and consumer engagement. However, this remains a challenging task despite significant advancements in pose-guided human video generation. In addressing this challenge, we identify the integration of human-object interactions (HOI) into pose-guided human video generation as a core issue. To this end, we introduce AnchorCrafter, a novel diffusion-based system designed to generate 2D videos featuring a target human and a customized object, achieving high visual fidelity and controllable interactions. Specifically, we propose two key innovations: the HOI-appearance perception, which enhances object appearance recognition from arbitrary multi-view perspectives and disentangles object and human appearance, and the HOI-motion injection, which enables complex human-object interactions by overcoming challenges in object trajectory conditioning and inter-occlusion management. Additionally, we introduce the HOI-region reweighting loss, a training objective that enhances the learning of object details. Extensive experiments demonstrate that our proposed system outperforms existing methods in preserving object appearance and shape awareness, while simultaneously maintaining consistency in human appearance and motion. Project page: https://cangcz.github.io/Anchor-Crafter/
Text-guided Zero-Shot Object Localization
Nov 18, 2024



Object localization is a hot issue in computer vision area, which aims to identify and determine the precise location of specific objects from image or video. Most existing object localization methods heavily rely on extensive labeled data, which are costly to annotate and constrain their applicability. Therefore, we propose a new Zero-Shot Object Localization (ZSOL) framework for addressing the aforementioned challenges. In the proposed framework, we introduce the Contrastive Language Image Pre-training (CLIP) module which could integrate visual and linguistic information effectively. Furthermore, we design a Text Self-Similarity Matching (TSSM) module, which could improve the localization accuracy by enhancing the representation of text features extracted by CLIP module. Hence, the proposed framework can be guided by prompt words to identify and locate specific objects in an image in the absence of labeled samples. The results of extensive experiments demonstrate that the proposed method could improve the localization performance significantly and establishes an effective benchmark for further research.
User Activity Detection with Delay-Calibration for Asynchronous Massive Random Access
Nov 04, 2024



This work considers an uplink asynchronous massive random access scenario in which a large number of users asynchronously access a base station equipped with multiple receive antennas. The objective is to alleviate the problem of massive collision due to the limited number of orthogonal preambles of an access scheme in which user activity detection is performed. We propose a user activity detection with delay-calibration (UAD-DC) algorithm and investigate the benefits of oversampling for the estimation of continuous time delays at the receiver. The proposed algorithm iteratively estimates time delays and detects active users by noting that the collided users can be identified through accurate estimation of time delays. Due to the sporadic user activity patterns, the user activity detection problem can be formulated as a compressive sensing (CS) problem, which can be solved by a modified Turbo-CS algorithm under the consideration of correlated noise samples resulting from oversampling. A sliding-window technique is applied in the proposed algorithm to reduce the overall computational complexity. Moreover, we propose a new design of the pulse shaping filter by minimizing the Bayesian Cram\'er-Rao bound of the detection problem under the constraint of limited spectral bandwidth. Numerical results demonstrate the efficacy of the proposed algorithm in terms of the normalized mean squared error of the estimated channel, the probability of misdetection and the successful detection ratio.