 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPPO: Contrastive Perception for Vision Language Policy Optimization
Jan 01, 2026We introduce CPPO, a Contrastive Perception Policy Optimization method for finetuning vision-language models (VLMs). While reinforcement learning (RL) has advanced reasoning in language models, extending it to multimodal reasoning requires improving both the perception and reasoning aspects. Prior works tackle this challenge mainly with explicit perception rewards, but disentangling perception tokens from reasoning tokens is difficult, requiring extra LLMs, ground-truth data, forced separation of perception from reasoning by policy model, or applying rewards indiscriminately to all output tokens. CPPO addresses this problem by detecting perception tokens via entropy shifts in the model outputs under perturbed input images. CPPO then extends the RL objective function with a Contrastive Perception Loss (CPL) that enforces consistency under information-preserving perturbations and sensitivity under information-removing ones. Experiments show that CPPO surpasses previous perception-rewarding methods, while avoiding extra models, making training more efficient and scalable.
Task-Agnostic Language Model Watermarking via High Entropy Passthrough Layers
Dec 17, 2024In the era of costly pre-training of large language models, ensuring the intellectual property rights of model owners, and insuring that said models are responsibly deployed, is becoming increasingly important. To this end, we propose model watermarking via passthrough layers, which are added to existing pre-trained networks and trained using a self-supervised loss such that the model produces high-entropy output when prompted with a unique private key, and acts normally otherwise. Unlike existing model watermarking methods, our method is fully task-agnostic, and can be applied to both classification and sequence-to-sequence tasks without requiring advanced access to downstream fine-tuning datasets. We evaluate the proposed passthrough layers on a wide range of downstream tasks, and show experimentally our watermarking method achieves a near-perfect watermark extraction accuracy and false-positive rate in most cases without damaging original model performance. Additionally, we show our method is robust to both downstream fine-tuning, fine-pruning, and layer removal attacks, and can be trained in a fraction of the time required to train the original model. Code is available in the paper.
LaWa: Using Latent Space for In-Generation Image Watermarking
Aug 11, 2024



With generative models producing high quality images that are indistinguishable from real ones, there is growing concern regarding the malicious usage of AI-generated images. Imperceptible image watermarking is one viable solution towards such concerns. Prior watermarking methods map the image to a latent space for adding the watermark. Moreover, Latent Diffusion Models (LDM) generate the image in the latent space of a pre-trained autoencoder. We argue that this latent space can be used to integrate watermarking into the generation process. To this end, we present LaWa, an in-generation image watermarking method designed for LDMs. By using coarse-to-fine watermark embedding modules, LaWa modifies the latent space of pre-trained autoencoders and achieves high robustness against a wide range of image transformations while preserving perceptual quality of the image. We show that LaWa can also be used as a general image watermarking method. Through extensive experiments, we demonstrate that LaWa outperforms previous works in perceptual quality, robustness against attacks, and computational complexity, while having very low false positive rate. Code is available here.
LRDB: LSTM Raw data DNA Base-caller based on long-short term models in an active learning environment
Mar 15, 2023



The first important step in extracting DNA characters is using the output data of MinION devices in the form of electrical current signals. Various cutting-edge base callers use this data to detect the DNA characters based on the input. In this paper, we discuss several shortcomings of prior base callers in the case of time-critical applications, privacy-aware design, and the problem of catastrophic forgetting. Next, we propose the LRDB model, a lightweight open-source model for private developments with a better read-identity (0.35% increase) for the target bacterial samples in the paper. We have limited the extent of training data and benefited from the transfer learning algorithm to make the active usage of the LRDB viable in critical applications. Henceforth, less training time for adapting to new DNA samples (in our case, Bacterial samples) is needed. Furthermore, LRDB can be modified concerning the user constraints as the results show a negligible accuracy loss in case of using fewer parameters. We have also assessed the noise-tolerance property, which offers about a 1.439% decline in accuracy for a 15dB noise injection, and the performance metrics show that the model executes in a medium speed range compared with current cutting-edge models.
TriPose: A Weakly-Supervised 3D Human Pose Estimation via Triangulation from Video
May 14, 2021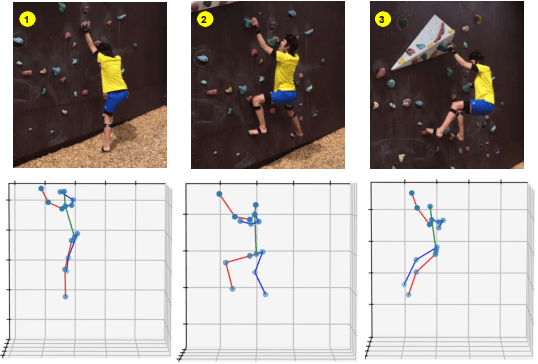
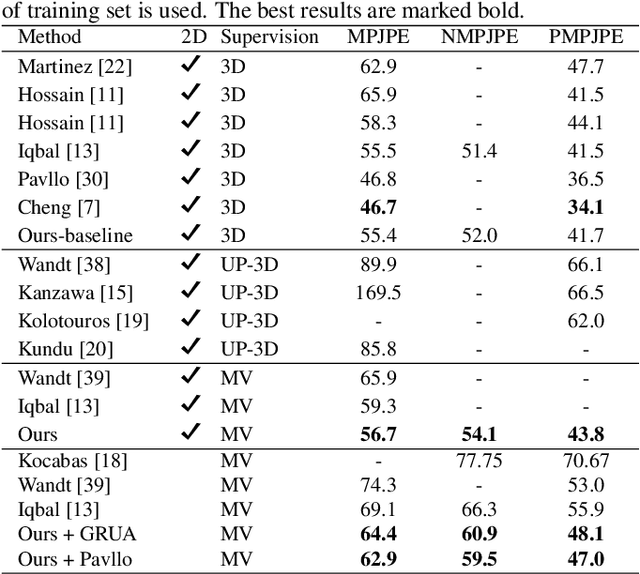
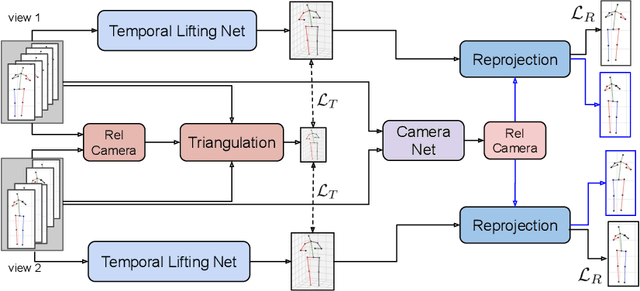
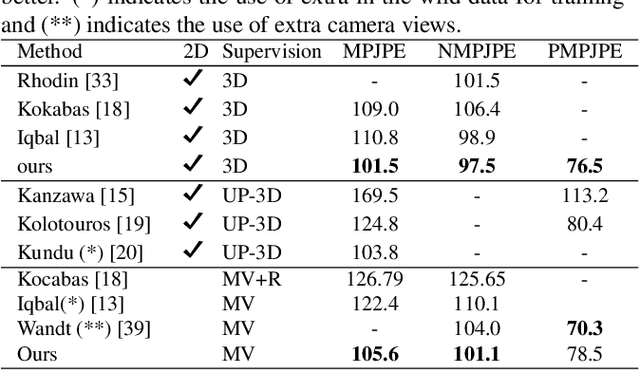
Estimating 3D human poses from video is a challenging problem. The lack of 3D human pose annotations is a major obstacle for supervised training and for generalization to unseen datasets. In this work, we address this problem by proposing a weakly-supervised training scheme that does not require 3D annotations or calibrated cameras. The proposed method relies on temporal information and triangulation. Using 2D poses from multiple views as the input, we first estimate the relative camera orientations and then generate 3D poses via triangulation. The triangulation is only applied to the views with high 2D human joint confidence. The generated 3D poses are then used to train a recurrent lifting network (RLN) that estimates 3D poses from 2D poses. We further apply a multi-view re-projection loss to the estimated 3D poses and enforce the 3D poses estimated from multi-views to be consistent. Therefore, our method relaxes the constraints in practice, only multi-view videos are required for training, and is thus convenient for in-the-wild settings. At inference, RLN merely requires single-view videos. The proposed method outperforms previous works on two challenging datasets, Human3.6M and MPI-INF-3DHP. Codes and pretrained models will be publicly available.