 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Language Models to Tackle Fundamental Challenges in Graph Learning: A Comprehensive Survey
May 24, 2025



Graphs are a widely used paradigm for representing non-Euclidean data, with applications ranging from social network analysis to biomolecular prediction. Conventional graph learning approaches typically rely on fixed structural assumptions or fully observed data, limiting their effectiveness in more complex, noisy, or evolving settings. Consequently, real-world graph data often violates the assumptions of traditional graph learning methods, in particular, it leads to four fundamental challenges: (1) Incompleteness, real-world graphs have missing nodes, edges, or attributes; (2) Imbalance, the distribution of the labels of nodes or edges and their structures for real-world graphs are highly skewed; (3) Cross-domain Heterogeneity, graphs from different domains exhibit incompatible feature spaces or structural patterns; and (4) Dynamic Instability, graphs evolve over time in unpredictable ways. Recent advances in Large Language Models (LLMs) offer the potential to tackle these challenges by leveraging rich semantic reasoning and external knowledge. This survey provides a comprehensive review of how LLMs can be integrated with graph learning to address the aforementioned challenges. For each challenge, we review both traditional solutions and modern LLM-driven approaches, highlighting how LLMs contribute unique advantages. Finally, we discuss open research questions and promising future directions in this emerging interdisciplinary field. To support further exploration, we have curated a repository of recent advances on graph learning challenges: https://github.com/limengran98/Awesome-Literature-Graph-Learning-Challenges.
Enhancing Learned Knowledge in LoRA Adapters Through Efficient Contrastive Decoding on Ascend NPUs
May 20, 2025Huawei Cloud users leverage LoRA (Low-Rank Adaptation) as an efficient and scalable method to fine-tune and customize large language models (LLMs) for application-specific needs. However, tasks that require complex reasoning or deep contextual understanding are often hindered by biases or interference from the base model when using typical decoding methods like greedy or beam search. These biases can lead to generic or task-agnostic responses from the base model instead of leveraging the LoRA-specific adaptations. In this paper, we introduce Contrastive LoRA Decoding (CoLD), a novel decoding framework designed to maximize the use of task-specific knowledge in LoRA-adapted models, resulting in better downstream performance. CoLD uses contrastive decoding by scoring candidate tokens based on the divergence between the probability distributions of a LoRA-adapted expert model and the corresponding base model. This approach prioritizes tokens that better align with the LoRA's learned representations, enhancing performance for specialized tasks. While effective, a naive implementation of CoLD is computationally expensive because each decoding step requires evaluating multiple token candidates across both models. To address this, we developed an optimized kernel for Huawei's Ascend NPU. CoLD achieves up to a 5.54% increase in task accuracy while reducing end-to-end latency by 28% compared to greedy decoding. This work provides practical and efficient decoding strategies for fine-tuned LLMs in resource-constrained environments and has broad implications for applied data science in both cloud and on-premises settings.
Avoid Recommending Out-of-Domain Items: Constrained Generative Recommendation with LLMs
May 06, 2025Large Language Models (LLMs) have shown promise for generative recommender systems due to their transformative capabilities in user interaction. However, ensuring they do not recommend out-of-domain (OOD) items remains a challenge. We study two distinct methods to address this issue: RecLM-ret, a retrieval-based method, and RecLM-cgen, a constrained generation method. Both methods integrate seamlessly with existing LLMs to ensure in-domain recommendations. Comprehensive experiments on three recommendation datasets demonstrate that RecLM-cgen consistently outperforms RecLM-ret and existing LLM-based recommender models in accuracy while eliminating OOD recommendations, making it the preferred method for adoption. Additionally, RecLM-cgen maintains strong generalist capabilities and is a lightweight plug-and-play module for easy integration into LLMs, offering valuable practical benefits for the community. Source code is available at https://github.com/microsoft/RecAI
CASP: Compression of Large Multimodal Models Based on Attention Sparsity
Mar 07, 2025



In this work, we propose an extreme compression technique for Large Multimodal Models (LMMs). While previous studies have explored quantization as an efficient post-training compression method for Large Language Models (LLMs), low-bit compression for multimodal models remains under-explored. The redundant nature of inputs in multimodal models results in a highly sparse attention matrix. We theoretically and experimentally demonstrate that the attention matrix's sparsity bounds the compression error of the Query and Key weight matrices. Based on this, we introduce CASP, a model compression technique for LMMs. Our approach performs a data-aware low-rank decomposition on the Query and Key weight matrix, followed by quantization across all layers based on an optimal bit allocation process. CASP is compatible with any quantization technique and enhances state-of-the-art 2-bit quantization methods (AQLM and QuIP#) by an average of 21% on image- and video-language benchmarks.
DivPrune: Diversity-based Visual Token Pruning for Large Multimodal Models
Mar 04, 2025



Large Multimodal Models (LMMs) have emerged as powerful models capable of understanding various data modalities, including text, images, and videos. LMMs encode both text and visual data into tokens that are then combined and processed by an integrated Large Language Model (LLM). Including visual tokens substantially increases the total token count, often by thousands. The increased input length for LLM significantly raises the complexity of inference, resulting in high latency in LMMs. To address this issue, token pruning methods, which remove part of the visual tokens, are proposed. The existing token pruning methods either require extensive calibration and fine-tuning or rely on suboptimal importance metrics which results in increased redundancy among the retained tokens. In this paper, we first formulate token pruning as Max-Min Diversity Problem (MMDP) where the goal is to select a subset such that the diversity among the selected {tokens} is maximized. Then, we solve the MMDP to obtain the selected subset and prune the rest. The proposed method, DivPrune, reduces redundancy and achieves the highest diversity of the selected tokens. By ensuring high diversity, the selected tokens better represent the original tokens, enabling effective performance even at high pruning ratios without requiring fine-tuning. Extensive experiments with various LMMs show that DivPrune achieves state-of-the-art accuracy over 16 image- and video-language datasets. Additionally, DivPrune reduces both the end-to-end latency and GPU memory usage for the tested models. The code is available $\href{https://github.com/vbdi/divprune}{\text{here}}$.
Mobius: Text to Seamless Looping Video Generation via Latent Shift
Feb 27, 2025We present Mobius, a novel method to generate seamlessly looping videos from text descriptions directly without any user annotations, thereby creating new visual materials for the multi-media presentation. Our method repurposes the pre-trained video latent diffusion model for generating looping videos from text prompts without any training. During inference, we first construct a latent cycle by connecting the starting and ending noise of the videos. Given that the temporal consistency can be maintained by the context of the video diffusion model, we perform multi-frame latent denoising by gradually shifting the first-frame latent to the end in each step. As a result, the denoising context varies in each step while maintaining consistency throughout the inference process. Moreover, the latent cycle in our method can be of any length. This extends our latent-shifting approach to generate seamless looping videos beyond the scope of the video diffusion model's context. Unlike previous cinemagraphs, the proposed method does not require an image as appearance, which will restrict the motions of the generated results. Instead, our method can produce more dynamic motion and better visual quality. We conduct multiple experiments and comparisons to verify the effectiveness of the proposed method, demonstrating its efficacy in different scenarios. All the code will be made available.
PhenoProfiler: Advancing Phenotypic Learning for Image-based Drug Discovery
Feb 26, 2025In the field of image-based drug discovery, capturing the phenotypic response of cells to various drug treatments and perturbations is a crucial step. However, existing methods require computationally extensive and complex multi-step procedures, which can introduce inefficiencies, limit generalizability, and increase potential errors. To address these challenges, we present PhenoProfiler, an innovative model designed to efficiently and effectively extract morphological representations, enabling the elucidation of phenotypic changes induced by treatments. PhenoProfiler is designed as an end-to-end tool that processes whole-slide multi-channel images directly into low-dimensional quantitative representations, eliminating the extensive computational steps required by existing methods. It also includes a multi-objective learning module to enhance robustness, accuracy, and generalization in morphological representation learning. PhenoProfiler is rigorously evaluated on large-scale publicly available datasets, including over 230,000 whole-slide multi-channel images in end-to-end scenarios and more than 8.42 million single-cell images in non-end-to-end settings. Across these benchmarks, PhenoProfiler consistently outperforms state-of-the-art methods by up to 20%, demonstrating substantial improvements in both accuracy and robustness. Furthermore, PhenoProfiler uses a tailored phenotype correction strategy to emphasize relative phenotypic changes under treatments, facilitating the detection of biologically meaningful signals. UMAP visualizations of treatment profiles demonstrate PhenoProfiler ability to effectively cluster treatments with similar biological annotations, thereby enhancing interpretability. These findings establish PhenoProfiler as a scalable, generalizable, and robust tool for phenotypic learning.
Self-Enhanced Reasoning Training: Activating Latent Reasoning in Small Models for Enhanced Reasoning Distillation
Feb 18, 2025



The rapid advancement of large language models (LLMs) has significantly enhanced their reasoning abilities, enabling increasingly complex tasks. However, these capabilities often diminish in smaller, more computationally efficient models like GPT-2. Recent research shows that reasoning distillation can help small models acquire reasoning capabilities, but most existing methods focus primarily on improving teacher-generated reasoning paths. Our observations reveal that small models can generate high-quality reasoning paths during sampling, even without chain-of-thought prompting, though these paths are often latent due to their low probability under standard decoding strategies. To address this, we propose Self-Enhanced Reasoning Training (SERT), which activates and leverages latent reasoning capabilities in small models through self-training on filtered, self-generated reasoning paths under zero-shot conditions. Experiments using OpenAI's GPT-3.5 as the teacher model and GPT-2 models as the student models demonstrate that SERT enhances the reasoning abilities of small models, improving their performance in reasoning distillation.
An Analysis Framework for Understanding Deep Neural Networks Based on Network Dynamics
Jan 05, 2025



Advancing artificial intelligence demands a deeper understanding of the mechanisms underlying deep learning. Here, we propose a straightforward analysis framework based on the dynamics of learning models. Neurons are categorized into two modes based on whether their transformation functions preserve order. This categorization reveals how deep neural networks (DNNs) maximize information extraction by rationally allocating the proportion of neurons in different modes across deep layers. We further introduce the attraction basins of the training samples in both the sample vector space and the weight vector space to characterize the generalization ability of DNNs. This framework allows us to identify optimal depth and width configurations, providing a unified explanation for fundamental DNN behaviors such as the "flat minima effect," "grokking," and double descent phenomena. Our analysis extends to networks with depths up to 100 layers.
Dynamic Attention-Guided Context Decoding for Mitigating Context Faithfulness Hallucinations in Large Language Models
Jan 02, 2025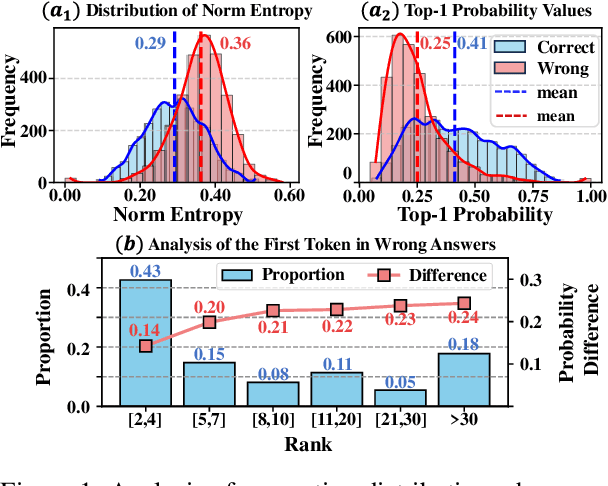
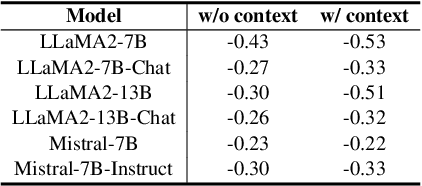
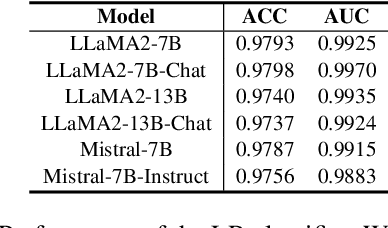
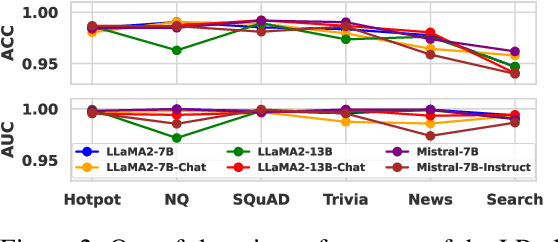
Large language models (LLMs) often suffer from context faithfulness hallucinations, where outputs deviate from retrieved information due to insufficient context utilization and high output uncertainty. Our uncertainty evaluation experiments reveal a strong correlation between high uncertainty and hallucinations. We hypothesize that attention mechanisms encode signals indicative of contextual utilization, validated through probing analysis. Based on these insights, we propose Dynamic Attention-Guided Context Decoding (DAGCD), a lightweight framework that integrates attention distributions and uncertainty signals in a single-pass decoding process. Experiments across QA datasets demonstrate DAGCD's effectiveness, achieving significant improvements in faithfulness and robustness while maintaining computational efficiency.