 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinarized Diffusion Model for Image Super-Resolution
Jun 09, 2024



Advanced diffusion models (DMs) perform impressively in image super-resolution (SR), but the high memory and computational costs hinder their deployment. Binarization, an ultra-compression algorithm, offers the potential for effectively accelerating DMs. Nonetheless, due to the model structure and the multi-step iterative attribute of DMs, existing binarization methods result in significant performance degradation. In this paper, we introduce a novel binarized diffusion model, BI-DiffSR, for image SR. First, for the model structure, we design a UNet architecture optimized for binarization. We propose the consistent-pixel-downsample (CP-Down) and consistent-pixel-upsample (CP-Up) to maintain dimension consistent and facilitate the full-precision information transfer. Meanwhile, we design the channel-shuffle-fusion (CS-Fusion) to enhance feature fusion in skip connection. Second, for the activation difference across timestep, we design the timestep-aware redistribution (TaR) and activation function (TaA). The TaR and TaA dynamically adjust the distribution of activations based on different timesteps, improving the flexibility and representation alability of the binarized module. Comprehensive experiments demonstrate that our BI-DiffSR outperforms existing binarization methods. Code is available at https://github.com/zhengchen1999/BI-DiffSR.
Benchmarking the Robustness of Temporal Action Detection Models Against Temporal Corruptions
Mar 29, 2024Temporal action detection (TAD) aims to locate action positions and recognize action categories in long-term untrimmed videos. Although many methods have achieved promising results, their robustness has not been thoroughly studied. In practice, we observe that temporal information in videos can be occasionally corrupted, such as missing or blurred frames. Interestingly, existing methods often incur a significant performance drop even if only one frame is affected. To formally evaluate the robustness, we establish two temporal corruption robustness benchmarks, namely THUMOS14-C and ActivityNet-v1.3-C. In this paper, we extensively analyze the robustness of seven leading TAD methods and obtain some interesting findings: 1) Existing methods are particularly vulnerable to temporal corruptions, and end-to-end methods are often more susceptible than those with a pre-trained feature extractor; 2) Vulnerability mainly comes from localization error rather than classification error; 3) When corruptions occur in the middle of an action instance, TAD models tend to yield the largest performance drop. Besides building a benchmark, we further develop a simple but effective robust training method to defend against temporal corruptions, through the FrameDrop augmentation and Temporal-Robust Consistency loss. Remarkably, our approach not only improves robustness but also yields promising improvements on clean data. We believe that this study will serve as a benchmark for future research in robust video analysis. Source code and models are available at https://github.com/Alvin-Zeng/temporal-robustness-benchmark.
CustomVideo: Customizing Text-to-Video Generation with Multiple Subjects
Jan 18, 2024



Customized text-to-video generation aims to generate high-quality videos guided by text prompts and subject references. Current approaches designed for single subjects suffer from tackling multiple subjects, which is a more challenging and practical scenario. In this work, we aim to promote multi-subject guided text-to-video customization. We propose CustomVideo, a novel framework that can generate identity-preserving videos with the guidance of multiple subjects. To be specific, firstly, we encourage the co-occurrence of multiple subjects via composing them in a single image. Further, upon a basic text-to-video diffusion model, we design a simple yet effective attention control strategy to disentangle different subjects in the latent space of diffusion model. Moreover, to help the model focus on the specific object area, we segment the object from given reference images and provide a corresponding object mask for attention learning. Also, we collect a multi-subject text-to-video generation dataset as a comprehensive benchmark, with 69 individual subjects and 57 meaningful pairs. Extensive qualitative, quantitative, and user study results demonstrate the superiority of our method, compared with the previous state-of-the-art approaches.
Bridging Code Semantic and LLMs: Semantic Chain-of-Thought Prompting for Code Generation
Oct 22, 2023



Large language models (LLMs) have showcased remarkable prowess in code generation. However, automated code generation is still challenging since it requires a high-level semantic mapping between natural language requirements and codes. Most existing LLMs-based approaches for code generation rely on decoder-only causal language models often treate codes merely as plain text tokens, i.e., feeding the requirements as a prompt input, and outputing code as flat sequence of tokens, potentially missing the rich semantic features inherent in source code. To bridge this gap, this paper proposes the "Semantic Chain-of-Thought" approach to intruduce semantic information of code, named SeCoT. Our motivation is that the semantic information of the source code (\eg data flow and control flow) describes more precise program execution behavior, intention and function. By guiding LLM consider and integrate semantic information, we can achieve a more granular understanding and representation of code, enhancing code generation accuracy. Meanwhile, while traditional techniques leveraging such semantic information require complex static or dynamic code analysis to obtain features such as data flow and control flow, SeCoT demonstrates that this process can be fully automated via the intrinsic capabilities of LLMs (i.e., in-context learning), while being generalizable and applicable to challenging domains. While SeCoT can be applied with different LLMs, this paper focuses on the powerful GPT-style models: ChatGPT(close-source model) and WizardCoder(open-source model). The experimental study on three popular DL benchmarks (i.e., HumanEval, HumanEval-ET and MBPP) shows that SeCoT can achieves state-of-the-art performance, greatly improving the potential for large models and code generation.
DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model
Oct 08, 2023In the past decade, autonomous driving has experienced rapid development in both academia and industry. However, its limited interpretability remains a significant unsolved problem, severely hindering autonomous vehicle commercialization and further development. Previous approaches utilizing small language models have failed to address this issue due to their lack of flexibility, generalization ability, and robustness. Recently, multimodal large language models (LLMs) have gained considerable attention from the research community for their capability to process and reason non-text data (e.g., images and videos) by text. In this paper, we present DriveGPT4, an interpretable end-to-end autonomous driving system utilizing LLMs. DriveGPT4 is capable of interpreting vehicle actions and providing corresponding reasoning, as well as answering diverse questions posed by human users for enhanced interaction. Additionally, DriveGPT4 predicts vehicle low-level control signals in an end-to-end fashion. These capabilities stem from a customized visual instruction tuning dataset specifically designed for autonomous driving. To the best of our knowledge, DriveGPT4 is the first work focusing on interpretable end-to-end autonomous driving. When evaluated on multiple tasks alongside conventional methods and video understanding LLMs, DriveGPT4 demonstrates superior qualitative and quantitative performance. Additionally, DriveGPT4 can be generalized in a zero-shot fashion to accommodate more unseen scenarios. The project page is available at https://tonyxuqaq.github.io/projects/DriveGPT4/ .
Robustifying Token Attention for Vision Transformers
Apr 04, 2023Despite the success of vision transformers (ViTs), they still suffer from significant drops in accuracy in the presence of common corruptions, such as noise or blur. Interestingly, we observe that the attention mechanism of ViTs tends to rely on few important tokens, a phenomenon we call token overfocusing. More critically, these tokens are not robust to corruptions, often leading to highly diverging attention patterns. In this paper, we intend to alleviate this overfocusing issue and make attention more stable through two general techniques: First, our Token-aware Average Pooling (TAP) module encourages the local neighborhood of each token to take part in the attention mechanism. Specifically, TAP learns average pooling schemes for each token such that the information of potentially important tokens in the neighborhood can adaptively be taken into account. Second, we force the output tokens to aggregate information from a diverse set of input tokens rather than focusing on just a few by using our Attention Diversification Loss (ADL). We achieve this by penalizing high cosine similarity between the attention vectors of different tokens. In experiments, we apply our methods to a wide range of transformer architectures and improve robustness significantly. For example, we improve corruption robustness on ImageNet-C by 2.4% while simultaneously improving accuracy by 0.4% based on state-of-the-art robust architecture FAN. Also, when finetuning on semantic segmentation tasks, we improve robustness on CityScapes-C by 2.4% and ACDC by 3.1%.
Boosting Semi-Supervised Learning with Contrastive Complementary Labeling
Dec 13, 2022



Semi-supervised learning (SSL) has achieved great success in leveraging a large amount of unlabeled data to learn a promising classifier. A popular approach is pseudo-labeling that generates pseudo labels only for those unlabeled data with high-confidence predictions. As for the low-confidence ones, existing methods often simply discard them because these unreliable pseudo labels may mislead the model. Nevertheless, we highlight that these data with low-confidence pseudo labels can be still beneficial to the training process. Specifically, although the class with the highest probability in the prediction is unreliable, we can assume that this sample is very unlikely to belong to the classes with the lowest probabilities. In this way, these data can be also very informative if we can effectively exploit these complementary labels, i.e., the classes that a sample does not belong to. Inspired by this, we propose a novel Contrastive Complementary Labeling (CCL) method that constructs a large number of reliable negative pairs based on the complementary labels and adopts contrastive learning to make use of all the unlabeled data. Extensive experiments demonstrate that CCL significantly improves the performance on top of existing methods. More critically, our CCL is particularly effective under the label-scarce settings. For example, we yield an improvement of 2.43% over FixMatch on CIFAR-10 only with 40 labeled data.
Downscaled Representation Matters: Improving Image Rescaling with Collaborative Downscaled Images
Nov 19, 2022



Deep networks have achieved great success in image rescaling (IR) task that seeks to learn the optimal downscaled representations, i.e., low-resolution (LR) images, to reconstruct the original high-resolution (HR) images. Compared with super-resolution methods that consider a fixed downscaling scheme, e.g., bicubic, IR often achieves significantly better reconstruction performance thanks to the learned downscaled representations. This highlights the importance of a good downscaled representation in image reconstruction tasks. Existing IR methods mainly learn the downscaled representation by jointly optimizing the downscaling and upscaling models. Unlike them, we seek to improve the downscaled representation through a different and more direct way: optimizing the downscaled image itself instead of the down-/upscaling models. Specifically, we propose a collaborative downscaling scheme that directly generates the collaborative LR examples by descending the gradient w.r.t. the reconstruction loss on them to benefit the IR process. Furthermore, since LR images are downscaled from the corresponding HR images, one can also improve the downscaled representation if we have a better representation in the HR domain. Inspired by this, we propose a Hierarchical Collaborative Downscaling (HCD) method that performs gradient descent in both HR and LR domains to improve the downscaled representations. Extensive experiments show that our HCD significantly improves the reconstruction performance both quantitatively and qualitatively. Moreover, we also highlight the flexibility of our HCD since it can generalize well across diverse IR models.
Automatic Subspace Evoking for Efficient Neural Architecture Search
Oct 31, 2022



Neural Architecture Search (NAS) aims to automatically find effective architectures from a predefined search space. However, the search space is often extremely large. As a result, directly searching in such a large search space is non-trivial and also very time-consuming. To address the above issues, in each search step, we seek to limit the search space to a small but effective subspace to boost both the search performance and search efficiency. To this end, we propose a novel Neural Architecture Search method via Automatic Subspace Evoking (ASE-NAS) that finds promising architectures in automatically evoked subspaces. Specifically, we first perform a global search, i.e., automatic subspace evoking, to evoke/find a good subspace from a set of candidates. Then, we perform a local search within the evoked subspace to find an effective architecture. More critically, we further boost search performance by taking well-designed/searched architectures as the initial candidate subspaces. Extensive experiments show that our ASE-NAS not only greatly reduces the search cost but also finds better architectures than state-of-the-art methods in various benchmark search spaces.
Pareto-aware Neural Architecture Generation for Diverse Computational Budgets
Oct 14, 2022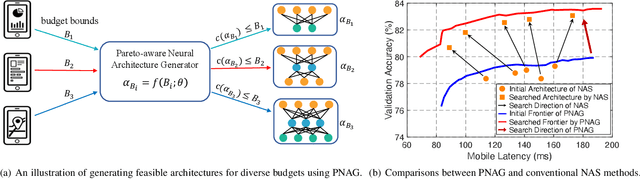
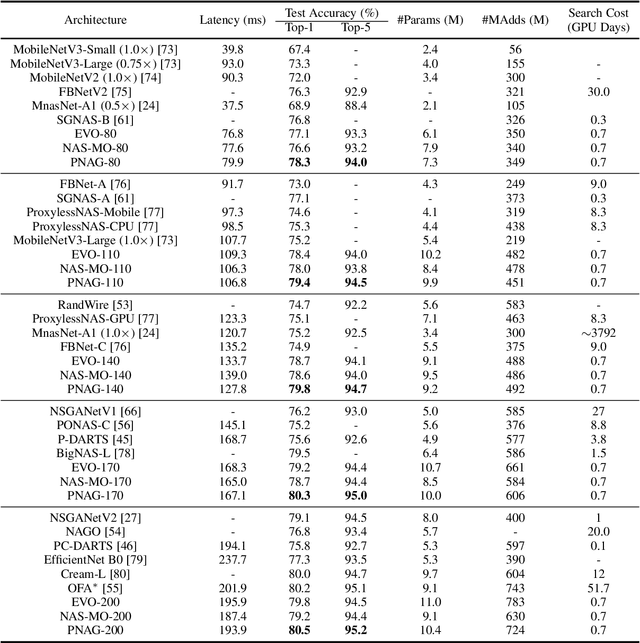
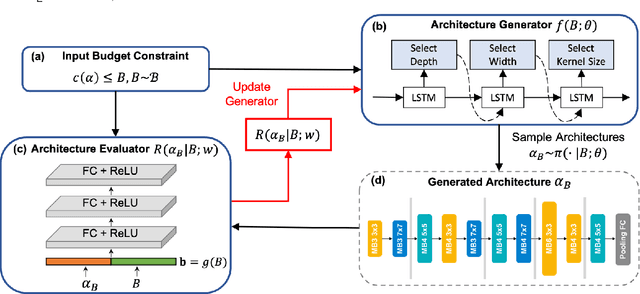
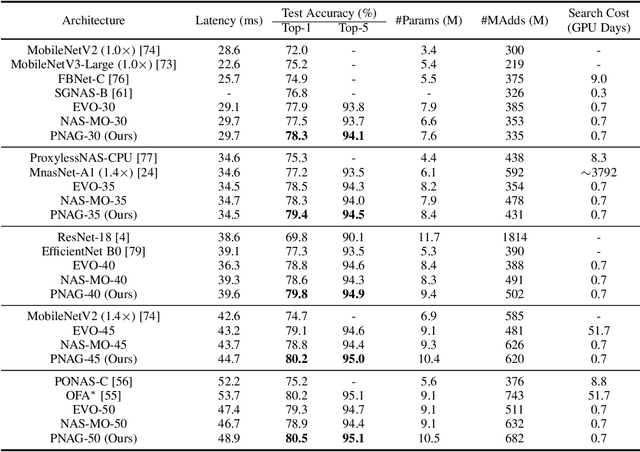
Designing feasible and effective architectures under diverse computational budgets, incurred by different applications/devices, is essential for deploying deep models in real-world applications. To achieve this goal, existing methods often perform an independent architecture search process for each target budget, which is very inefficient yet unnecessary. More critically, these independent search processes cannot share their learned knowledge (i.e., the distribution of good architectures) with each other and thus often result in limited search results. To address these issues, we propose a Pareto-aware Neural Architecture Generator (PNAG) which only needs to be trained once and dynamically produces the Pareto optimal architecture for any given budget via inference. To train our PNAG, we learn the whole Pareto frontier by jointly finding multiple Pareto optimal architectures under diverse budgets. Such a joint search algorithm not only greatly reduces the overall search cost but also improves the search results. Extensive experiments on three hardware platforms (i.e., mobile device, CPU, and GPU) show the superiority of our method over existing methods.