 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemoTuner: Efficient DBMS Knobs Tuning via LLM-Assisted Demonstration Reinforcement Learning
Nov 13, 2025The performance of modern DBMSs such as MySQL and PostgreSQL heavily depends on the configuration of performance-critical knobs. Manual tuning these knobs is laborious and inefficient due to the complex and high-dimensional nature of the configuration space. Among the automated tuning methods, reinforcement learning (RL)-based methods have recently sought to improve the DBMS knobs tuning process from several different perspectives. However, they still encounter challenges with slow convergence speed during offline training. In this paper, we mainly focus on how to leverage the valuable tuning hints contained in various textual documents such as DBMS manuals and web forums to improve the offline training of RL-based methods. To this end, we propose an efficient DBMS knobs tuning framework named DemoTuner via a novel LLM-assisted demonstration reinforcement learning method. Specifically, to comprehensively and accurately mine tuning hints from documents, we design a structured chain of thought prompt to employ LLMs to conduct a condition-aware tuning hints extraction task. To effectively integrate the mined tuning hints into RL agent training, we propose a hint-aware demonstration reinforcement learning algorithm HA-DDPGfD in DemoTuner. As far as we know, DemoTuner is the first work to introduce the demonstration reinforcement learning algorithm for DBMS knobs tuning. Experimental evaluations conducted on MySQL and PostgreSQL across various workloads demonstrate the significant advantages of DemoTuner in both performance improvement and online tuning cost reduction over three representative baselines including DB-BERT, GPTuner and CDBTune. Additionally, DemoTuner also exhibits superior adaptability to application scenarios with unknown workloads.
Breaking the Modality Barrier: Generative Modeling for Accurate Molecule Retrieval from Mass Spectra
Nov 09, 2025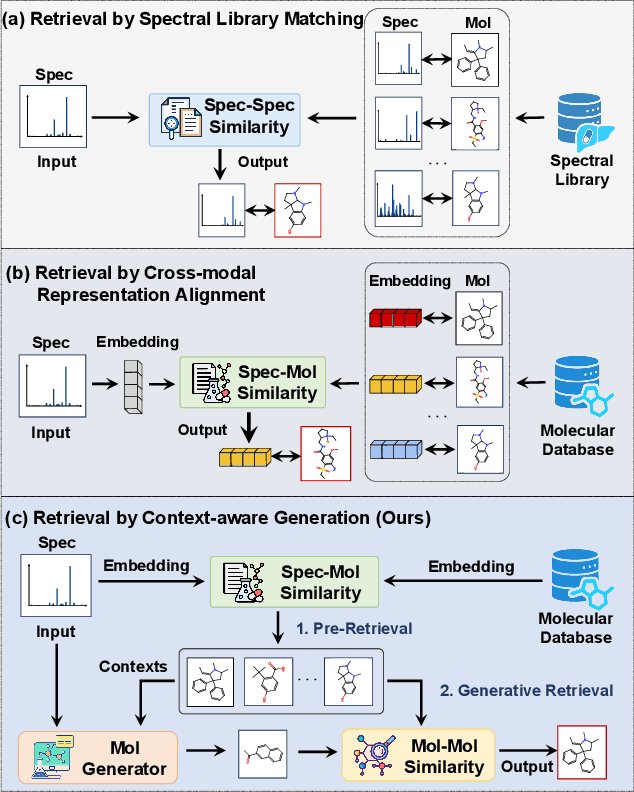



Retrieving molecular structures from tandem mass spectra is a crucial step in rapid compound identification. Existing retrieval methods, such as traditional mass spectral library matching, suffer from limited spectral library coverage, while recent cross-modal representation learning frameworks often encounter modality misalignment, resulting in suboptimal retrieval accuracy and generalization. To address these limitations, we propose GLMR, a Generative Language Model-based Retrieval framework that mitigates the cross-modal misalignment through a two-stage process. In the pre-retrieval stage, a contrastive learning-based model identifies top candidate molecules as contextual priors for the input mass spectrum. In the generative retrieval stage, these candidate molecules are integrated with the input mass spectrum to guide a generative model in producing refined molecular structures, which are then used to re-rank the candidates based on molecular similarity. Experiments on both MassSpecGym and the proposed MassRET-20k dataset demonstrate that GLMR significantly outperforms existing methods, achieving over 40% improvement in top-1 accuracy and exhibiting strong generalizability.
Heterogeneous Graph Masked Contrastive Learning for Robust Recommendation
May 30, 2025Heterogeneous graph neural networks (HGNNs) have demonstrated their superiority in exploiting auxiliary information for recommendation tasks. However, graphs constructed using meta-paths in HGNNs are usually too dense and contain a large number of noise edges. The propagation mechanism of HGNNs propagates even small amounts of noise in a graph to distant neighboring nodes, thereby affecting numerous node embeddings. To address this limitation, we introduce a novel model, named Masked Contrastive Learning (MCL), to enhance recommendation robustness to noise. MCL employs a random masking strategy to augment the graph via meta-paths, reducing node sensitivity to specific neighbors and bolstering embedding robustness. Furthermore, MCL employs contrastive cross-view on a Heterogeneous Information Network (HIN) from two perspectives: one-hop neighbors and meta-path neighbors. This approach acquires embeddings capturing both local and high-order structures simultaneously for recommendation. Empirical evaluations on three real-world datasets confirm the superiority of our approach over existing recommendation methods.
DenseLoRA: Dense Low-Rank Adaptation of Large Language Models
May 27, 2025



Low-rank adaptation (LoRA) has been developed as an efficient approach for adapting large language models (LLMs) by fine-tuning two low-rank matrices, thereby reducing the number of trainable parameters. However, prior research indicates that many of the weights in these matrices are redundant, leading to inefficiencies in parameter utilization. To address this limitation, we introduce Dense Low-Rank Adaptation (DenseLoRA), a novel approach that enhances parameter efficiency while achieving superior performance compared to LoRA. DenseLoRA builds upon the concept of representation fine-tuning, incorporating a single Encoder-Decoder to refine and compress hidden representations across all adaptation layers before applying adaptation. Instead of relying on two redundant low-rank matrices as in LoRA, DenseLoRA adapts LLMs through a dense low-rank matrix, improving parameter utilization and adaptation efficiency. We evaluate DenseLoRA on various benchmarks, showing that it achieves 83.8% accuracy with only 0.01% of trainable parameters, compared to LoRA's 80.8% accuracy with 0.70% of trainable parameters on LLaMA3-8B. Additionally, we conduct extensive experiments to systematically assess the impact of DenseLoRA's components on overall model performance. Code is available at https://github.com/mulin-ahu/DenseLoRA.
Revisiting Feature Interactions from the Perspective of Quadratic Neural Networks for Click-through Rate Prediction
May 23, 2025Hadamard Product (HP) has long been a cornerstone in click-through rate (CTR) prediction tasks due to its simplicity, effectiveness, and ability to capture feature interactions without additional parameters. However, the underlying reasons for its effectiveness remain unclear. In this paper, we revisit HP from the perspective of Quadratic Neural Networks (QNN), which leverage quadratic interaction terms to model complex feature relationships. We further reveal QNN's ability to expand the feature space and provide smooth nonlinear approximations without relying on activation functions. Meanwhile, we find that traditional post-activation does not further improve the performance of the QNN. Instead, mid-activation is a more suitable alternative. Through theoretical analysis and empirical evaluation of 25 QNN neuron formats, we identify a good-performing variant and make further enhancements on it. Specifically, we propose the Multi-Head Khatri-Rao Product as a superior alternative to HP and a Self-Ensemble Loss with dynamic ensemble capability within the same network to enhance computational efficiency and performance. Ultimately, we propose a novel neuron format, QNN-alpha, which is tailored for CTR prediction tasks. Experimental results show that QNN-alpha achieves new state-of-the-art performance on six public datasets while maintaining low inference latency, good scalability, and excellent compatibility. The code, running logs, and detailed hyperparameter configurations are available at: https://github.com/salmon1802/QNN.
Community Search in Time-dependent Road-social Attributed Networks
May 18, 2025Real-world networks often involve both keywords and locations, along with travel time variations between locations due to traffic conditions. However, most existing cohesive subgraph-based community search studies utilize a single attribute, either keywords or locations, to identify communities. They do not simultaneously consider both keywords and locations, which results in low semantic or spatial cohesiveness of the detected communities, and they fail to account for variations in travel time. Additionally, these studies traverse the entire network to build efficient indexes, but the detected community only involves nodes around the query node, leading to the traversal of nodes that are not relevant to the community. Therefore, we propose the problem of discovering semantic-spatial aware k-core, which refers to a k-core with high semantic and time-dependent spatial cohesiveness containing the query node. To address this problem, we propose an exact and a greedy algorithm, both of which gradually expand outward from the query node. They are local methods that only access the local part of the attributed network near the query node rather than the entire network. Moreover, we design a method to calculate the semantic similarity between two keywords using large language models. This method alleviates the disadvantages of keyword-matching methods used in existing community search studies, such as mismatches caused by differently expressed synonyms and the presence of irrelevant words. Experimental results show that the greedy algorithm outperforms baselines in terms of structural, semantic, and time-dependent spatial cohesiveness.
Pre-trained Prompt-driven Community Search
May 18, 2025



The "pre-train, prompt" paradigm is widely adopted in various graph-based tasks and has shown promising performance in community detection. Most existing semi-supervised community detection algorithms detect communities based on known ones, and the detected communities typically do not contain the given query node. Therefore, they are not suitable for searching the community of a given node. Motivated by this, we adopt this paradigm into the semi-supervised community search for the first time and propose Pre-trained Prompt-driven Community Search (PPCS), a novel model designed to enhance search accuracy and efficiency. PPCS consists of three main components: node encoding, sample generation, and prompt-driven fine-tuning. Specifically, the node encoding component employs graph neural networks to learn local structural patterns of nodes in a graph, thereby obtaining representations for nodes and communities. Next, the sample generation component identifies an initial community for a given node and selects known communities that are structurally similar to the initial one as training samples. Finally, the prompt-driven fine-tuning component leverages these samples as prompts to guide the final community prediction. Experimental results on five real-world datasets demonstrate that PPCS performs better than baseline algorithms. It also achieves higher community search efficiency than semi-supervised community search baseline methods, with ablation studies verifying the effectiveness of each component of PPCS.
Community and hyperedge inference in multiple hypergraphs
May 08, 2025Hypergraphs, capable of representing high-order interactions via hyperedges, have become a powerful tool for modeling real-world biological and social systems. Inherent relationships within these real-world systems, such as the encoding relationship between genes and their protein products, drive the establishment of interconnections between multiple hypergraphs. Here, we demonstrate how to utilize those interconnections between multiple hypergraphs to synthesize integrated information from multiple higher-order systems, thereby enhancing understanding of underlying structures. We propose a model based on the stochastic block model, which integrates information from multiple hypergraphs to reveal latent high-order structures. Real-world hyperedges exhibit preferential attachment, where certain nodes dominate hyperedge formation. To characterize this phenomenon, our model introduces hyperedge internal degree to quantify nodes' contributions to hyperedge formation. This model is capable of mining communities, predicting missing hyperedges of arbitrary sizes within hypergraphs, and inferring inter-hypergraph edges between hypergraphs. We apply our model to high-order datasets to evaluate its performance. Experimental results demonstrate strong performance of our model in community detection, hyperedge prediction, and inter-hypergraph edge prediction tasks. Moreover, we show that our model enables analysis of multiple hypergraphs of different types and supports the analysis of a single hypergraph in the absence of inter-hypergraph edges. Our work provides a practical and flexible tool for analyzing multiple hypergraphs, greatly advancing the understanding of the organization in real-world high-order systems.
Facilitating Video Story Interaction with Multi-Agent Collaborative System
May 02, 2025Video story interaction enables viewers to engage with and explore narrative content for personalized experiences. However, existing methods are limited to user selection, specially designed narratives, and lack customization. To address this, we propose an interactive system based on user intent. Our system uses a Vision Language Model (VLM) to enable machines to understand video stories, combining Retrieval-Augmented Generation (RAG) and a Multi-Agent System (MAS) to create evolving characters and scene experiences. It includes three stages: 1) Video story processing, utilizing VLM and prior knowledge to simulate human understanding of stories across three modalities. 2) Multi-space chat, creating growth-oriented characters through MAS interactions based on user queries and story stages. 3) Scene customization, expanding and visualizing various story scenes mentioned in dialogue. Applied to the Harry Potter series, our study shows the system effectively portrays emergent character social behavior and growth, enhancing the interactive experience in the video story world.
Quadratic Interest Network for Multimodal Click-Through Rate Prediction
Apr 24, 2025Multimodal click-through rate (CTR) prediction is a key technique in industrial recommender systems. It leverages heterogeneous modalities such as text, images, and behavioral logs to capture high-order feature interactions between users and items, thereby enhancing the system's understanding of user interests and its ability to predict click behavior. The primary challenge in this field lies in effectively utilizing the rich semantic information from multiple modalities while satisfying the low-latency requirements of online inference in real-world applications. To foster progress in this area, the Multimodal CTR Prediction Challenge Track of the WWW 2025 EReL@MIR Workshop formulates the problem into two tasks: (1) Task 1 of Multimodal Item Embedding: this task aims to explore multimodal information extraction and item representation learning methods that enhance recommendation tasks; and (2) Task 2 of Multimodal CTR Prediction: this task aims to explore what multimodal recommendation model can effectively leverage multimodal embedding features and achieve better performance. In this paper, we propose a novel model for Task 2, named Quadratic Interest Network (QIN) for Multimodal CTR Prediction. Specifically, QIN employs adaptive sparse target attention to extract multimodal user behavior features, and leverages Quadratic Neural Networks to capture high-order feature interactions. As a result, QIN achieved an AUC of 0.9798 on the leaderboard and ranked second in the competition. The model code, training logs, hyperparameter configurations, and checkpoints are available at https://github.com/salmon1802/QIN.