 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolynomial Expansion Rank Adaptation: Enhancing Low-Rank Fine-Tuning with High-Order Interactions
Apr 12, 2026Low-rank adaptation (LoRA) is a widely used strategy for efficient fine-tuning of large language models (LLMs), but its strictly linear structure fundamentally limits expressive capacity. The bilinear formulation of weight updates captures only first-order dependencies between low-rank factors, restricting the modeling of nonlinear and higher-order parameter interactions. In this paper, we propose Polynomial Expansion Rank Adaptation (PERA), a novel method that introduces structured polynomial expansion directly into the low-rank factor space. By expanding each low-rank factor to synthesize high-order interaction terms before composition, PERA transforms the adaptation space into a polynomial manifold capable of modeling richer nonlinear coupling without increasing rank or inference cost. We provide theoretical analysis demonstrating that PERA offers enhanced expressive capacity and more effective feature utilization compare to existing linear adaptation approaches. Empirically, PERA consistently outperforms state-of-the-art methods across diverse benchmarks. Notably, our experiments show that incorporating high-order nonlinear components particularly square terms is crucial for enhancing expressive capacity and maintaining strong and robust performance under various rank settings. Our code is available at https://github.com/zhangwenhao6/PERA
TalkLoRA: Communication-Aware Mixture of Low-Rank Adaptation for Large Language Models
Apr 07, 2026Low-Rank Adaptation (LoRA) enables parameter-efficient fine-tuning of Large Language Models (LLMs), and recent Mixture-of-Experts (MoE) extensions further enhance flexibility by dynamically combining multiple LoRA experts. However, existing MoE-augmented LoRA methods assume that experts operate independently, often leading to unstable routing, expert dominance. In this paper, we propose \textbf{TalkLoRA}, a communication-aware MoELoRA framework that relaxes this independence assumption by introducing expert-level communication prior to routing. TalkLoRA equips low-rank experts with a lightweight Talking Module that enables controlled information exchange across expert subspaces, producing a more robust global signal for routing. Theoretically, we show that expert communication smooths routing dynamics by mitigating perturbation amplification while strictly generalizing existing MoELoRA architectures. Empirically, TalkLoRA consistently outperforms vanilla LoRA and MoELoRA across diverse language understanding and generation tasks, achieving higher parameter efficiency and more balanced expert routing under comparable parameter budgets. These results highlight structured expert communication as a principled and effective enhancement for MoE-based parameter-efficient adaptation. Code is available at https://github.com/why0129/TalkLoRA.
From Representation to Clusters: A Contrastive Learning Approach for Attributed Hypergraph Clustering
Mar 10, 2026Contrastive learning has demonstrated strong performance in attributed hypergraph clustering. Typically, existing methods based on contrastive learning first learn node embeddings and then apply clustering algorithms, such as k-means, to these embeddings to obtain the clustering results.However, these methods lack direct clustering supervision, risking the inclusion of clustering-irrelevant information in the learned graph.To this end, we propose a Contrastive learning approach for Attributed Hypergraph Clustering (CAHC), an end-to-end method that simultaneously learns node embeddings and obtains clustering results. CAHC consists of two main steps: representation learning and cluster assignment learning. The former employs a novel contrastive learning approach that incorporates both node-level and hyperedge-level objectives to generate node embeddings.The latter joint embedding and clustering optimization to refine these embeddings by clustering-oriented guidance and obtains clustering results simultaneously.Extensive experimental results demonstrate that CAHC outperforms baselines on eight datasets.
DenseLoRA: Dense Low-Rank Adaptation of Large Language Models
May 27, 2025



Low-rank adaptation (LoRA) has been developed as an efficient approach for adapting large language models (LLMs) by fine-tuning two low-rank matrices, thereby reducing the number of trainable parameters. However, prior research indicates that many of the weights in these matrices are redundant, leading to inefficiencies in parameter utilization. To address this limitation, we introduce Dense Low-Rank Adaptation (DenseLoRA), a novel approach that enhances parameter efficiency while achieving superior performance compared to LoRA. DenseLoRA builds upon the concept of representation fine-tuning, incorporating a single Encoder-Decoder to refine and compress hidden representations across all adaptation layers before applying adaptation. Instead of relying on two redundant low-rank matrices as in LoRA, DenseLoRA adapts LLMs through a dense low-rank matrix, improving parameter utilization and adaptation efficiency. We evaluate DenseLoRA on various benchmarks, showing that it achieves 83.8% accuracy with only 0.01% of trainable parameters, compared to LoRA's 80.8% accuracy with 0.70% of trainable parameters on LLaMA3-8B. Additionally, we conduct extensive experiments to systematically assess the impact of DenseLoRA's components on overall model performance. Code is available at https://github.com/mulin-ahu/DenseLoRA.
Pre-trained Prompt-driven Community Search
May 18, 2025



The "pre-train, prompt" paradigm is widely adopted in various graph-based tasks and has shown promising performance in community detection. Most existing semi-supervised community detection algorithms detect communities based on known ones, and the detected communities typically do not contain the given query node. Therefore, they are not suitable for searching the community of a given node. Motivated by this, we adopt this paradigm into the semi-supervised community search for the first time and propose Pre-trained Prompt-driven Community Search (PPCS), a novel model designed to enhance search accuracy and efficiency. PPCS consists of three main components: node encoding, sample generation, and prompt-driven fine-tuning. Specifically, the node encoding component employs graph neural networks to learn local structural patterns of nodes in a graph, thereby obtaining representations for nodes and communities. Next, the sample generation component identifies an initial community for a given node and selects known communities that are structurally similar to the initial one as training samples. Finally, the prompt-driven fine-tuning component leverages these samples as prompts to guide the final community prediction. Experimental results on five real-world datasets demonstrate that PPCS performs better than baseline algorithms. It also achieves higher community search efficiency than semi-supervised community search baseline methods, with ablation studies verifying the effectiveness of each component of PPCS.
Community Search in Time-dependent Road-social Attributed Networks
May 18, 2025Real-world networks often involve both keywords and locations, along with travel time variations between locations due to traffic conditions. However, most existing cohesive subgraph-based community search studies utilize a single attribute, either keywords or locations, to identify communities. They do not simultaneously consider both keywords and locations, which results in low semantic or spatial cohesiveness of the detected communities, and they fail to account for variations in travel time. Additionally, these studies traverse the entire network to build efficient indexes, but the detected community only involves nodes around the query node, leading to the traversal of nodes that are not relevant to the community. Therefore, we propose the problem of discovering semantic-spatial aware k-core, which refers to a k-core with high semantic and time-dependent spatial cohesiveness containing the query node. To address this problem, we propose an exact and a greedy algorithm, both of which gradually expand outward from the query node. They are local methods that only access the local part of the attributed network near the query node rather than the entire network. Moreover, we design a method to calculate the semantic similarity between two keywords using large language models. This method alleviates the disadvantages of keyword-matching methods used in existing community search studies, such as mismatches caused by differently expressed synonyms and the presence of irrelevant words. Experimental results show that the greedy algorithm outperforms baselines in terms of structural, semantic, and time-dependent spatial cohesiveness.
Community and hyperedge inference in multiple hypergraphs
May 08, 2025Hypergraphs, capable of representing high-order interactions via hyperedges, have become a powerful tool for modeling real-world biological and social systems. Inherent relationships within these real-world systems, such as the encoding relationship between genes and their protein products, drive the establishment of interconnections between multiple hypergraphs. Here, we demonstrate how to utilize those interconnections between multiple hypergraphs to synthesize integrated information from multiple higher-order systems, thereby enhancing understanding of underlying structures. We propose a model based on the stochastic block model, which integrates information from multiple hypergraphs to reveal latent high-order structures. Real-world hyperedges exhibit preferential attachment, where certain nodes dominate hyperedge formation. To characterize this phenomenon, our model introduces hyperedge internal degree to quantify nodes' contributions to hyperedge formation. This model is capable of mining communities, predicting missing hyperedges of arbitrary sizes within hypergraphs, and inferring inter-hypergraph edges between hypergraphs. We apply our model to high-order datasets to evaluate its performance. Experimental results demonstrate strong performance of our model in community detection, hyperedge prediction, and inter-hypergraph edge prediction tasks. Moreover, we show that our model enables analysis of multiple hypergraphs of different types and supports the analysis of a single hypergraph in the absence of inter-hypergraph edges. Our work provides a practical and flexible tool for analyzing multiple hypergraphs, greatly advancing the understanding of the organization in real-world high-order systems.
Rethinking Few-Shot Medical Image Segmentation by SAM2: A Training-Free Framework with Augmentative Prompting and Dynamic Matching
Mar 05, 2025



The reliance on large labeled datasets presents a significant challenge in medical image segmentation. Few-shot learning offers a potential solution, but existing methods often still require substantial training data. This paper proposes a novel approach that leverages the Segment Anything Model 2 (SAM2), a vision foundation model with strong video segmentation capabilities. We conceptualize 3D medical image volumes as video sequences, departing from the traditional slice-by-slice paradigm. Our core innovation is a support-query matching strategy: we perform extensive data augmentation on a single labeled support image and, for each frame in the query volume, algorithmically select the most analogous augmented support image. This selected image, along with its corresponding mask, is used as a mask prompt, driving SAM2's video segmentation. This approach entirely avoids model retraining or parameter updates. We demonstrate state-of-the-art performance on benchmark few-shot medical image segmentation datasets, achieving significant improvements in accuracy and annotation efficiency. This plug-and-play method offers a powerful and generalizable solution for 3D medical image segmentation.
Random Directional Attack for Fooling Deep Neural Networks
Aug 06, 2019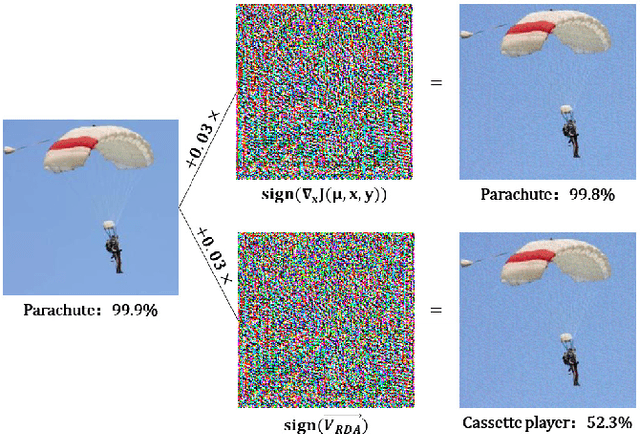
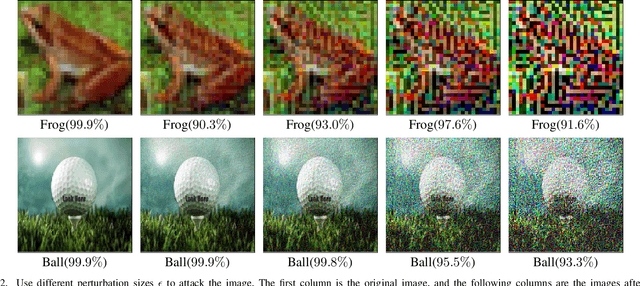
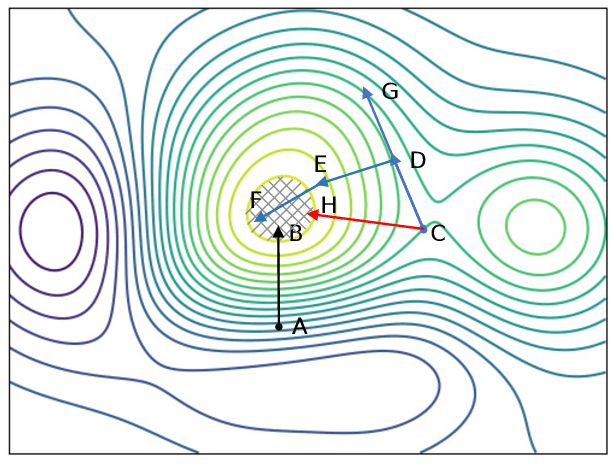
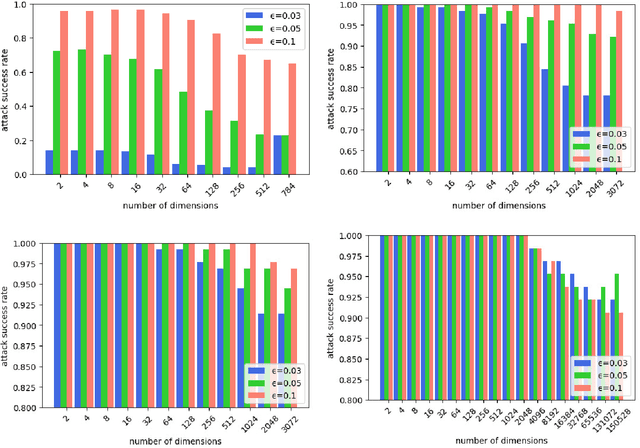
Deep neural networks (DNNs) have been widely used in many fields such as images processing, speech recognition; however, they are vulnerable to adversarial examples, and this is a security issue worthy of attention. Because the training process of DNNs converge the loss by updating the weights along the gradient descent direction, many gradient-based methods attempt to destroy the DNN model by adding perturbations in the gradient direction. Unfortunately, as the model is nonlinear in most cases, the addition of perturbations in the gradient direction does not necessarily increase loss. Thus, we propose a random directed attack (RDA) for generating adversarial examples in this paper. Rather than limiting the gradient direction to generate an attack, RDA searches the attack direction based on hill climbing and uses multiple strategies to avoid local optima that cause attack failure. Compared with state-of-the-art gradient-based methods, the attack performance of RDA is very competitive. Moreover, RDA can attack without any internal knowledge of the model, and its performance under black-box attack is similar to that of the white-box attack in most cases, which is difficult to achieve using existing gradient-based attack methods.