 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZegCLIP: Towards Adapting CLIP for Zero-shot Semantic Segmentation
Dec 12, 2022



Recently, CLIP has been applied to pixel-level zero-shot learning tasks via a two-stage scheme. The general idea is to first generate class-agnostic region proposals and then feed the cropped proposal regions to CLIP to utilize its image-level zero-shot classification capability. While effective, such a scheme requires two image encoders, one for proposal generation and one for CLIP, leading to a complicated pipeline and high computational cost. In this work, we pursue a simpler-and-efficient one-stage solution that directly extends CLIP's zero-shot prediction capability from image to pixel level. Our investigation starts with a straightforward extension as our baseline that generates semantic masks by comparing the similarity between text and patch embeddings extracted from CLIP. However, such a paradigm could heavily overfit the seen classes and fail to generalize to unseen classes. To handle this issue, we propose three simple-but-effective designs and figure out that they can significantly retain the inherent zero-shot capacity of CLIP and improve pixel-level generalization ability. Incorporating those modifications leads to an efficient zero-shot semantic segmentation system called ZegCLIP. Through extensive experiments on three public benchmarks, ZegCLIP demonstrates superior performance, outperforming the state-of-the-art methods by a large margin under both "inductive" and "transductive" zero-shot settings. In addition, compared with the two-stage method, our one-stage ZegCLIP achieves a speedup of about 5 times faster during inference. We release the code at https://github.com/ZiqinZhou66/ZegCLIP.git.
Pretrained Language Encoders are Natural Tagging Frameworks for Aspect Sentiment Triplet Extraction
Aug 20, 2022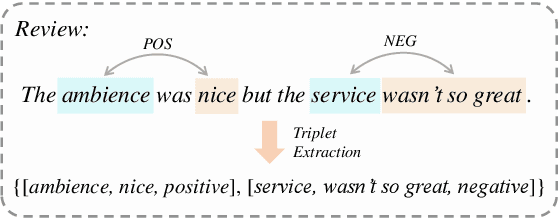
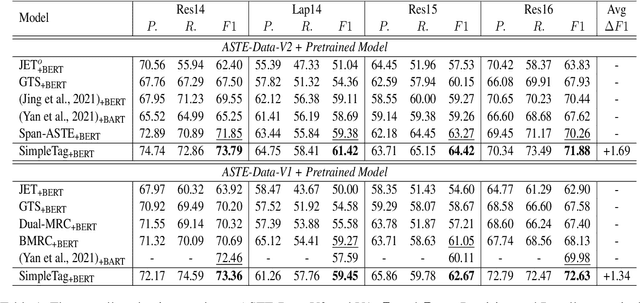
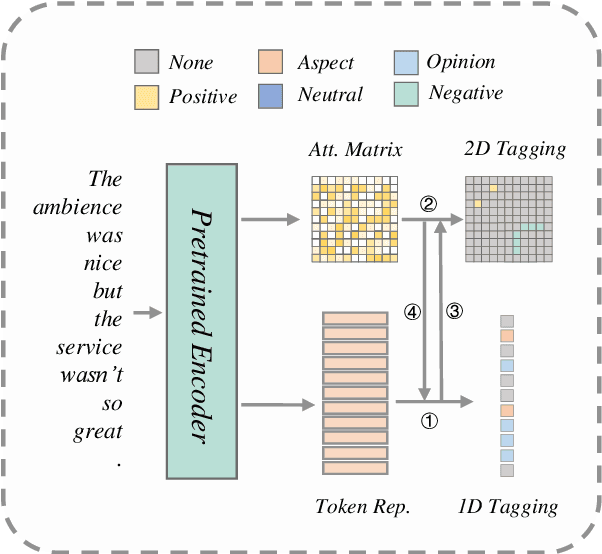
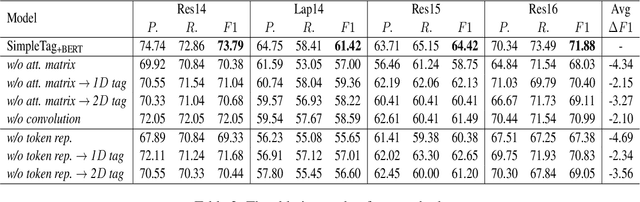
Aspect Sentiment Triplet Extraction (ASTE) aims to extract the spans of aspect, opinion, and their sentiment relations as sentiment triplets. Existing works usually formulate the span detection as a 1D token tagging problem, and model the sentiment recognition with a 2D tagging matrix of token pairs. Moreover, by leveraging the token representation of Pretrained Language Encoders (PLEs) like BERT, they can achieve better performance. However, they simply leverage PLEs as feature extractors to build their modules but never have a deep look at what specific knowledge does PLEs contain. In this paper, we argue that instead of further designing modules to capture the inductive bias of ASTE, PLEs themselves contain "enough" features for 1D and 2D tagging: (1) The token representation contains the contextualized meaning of token itself, so this level feature carries necessary information for 1D tagging. (2) The attention matrix of different PLE layers can further capture multi-level linguistic knowledge existing in token pairs, which benefits 2D tagging. (3) Furthermore, with simple transformations, these two features can also be easily converted to the 2D tagging matrix and 1D tagging sequence, respectively. That will further boost the tagging results. By doing so, PLEs can be natural tagging frameworks and achieve a new state of the art, which is verified by extensive experiments and deep analyses.
Semantic-Aware Domain Generalized Segmentation
Apr 02, 2022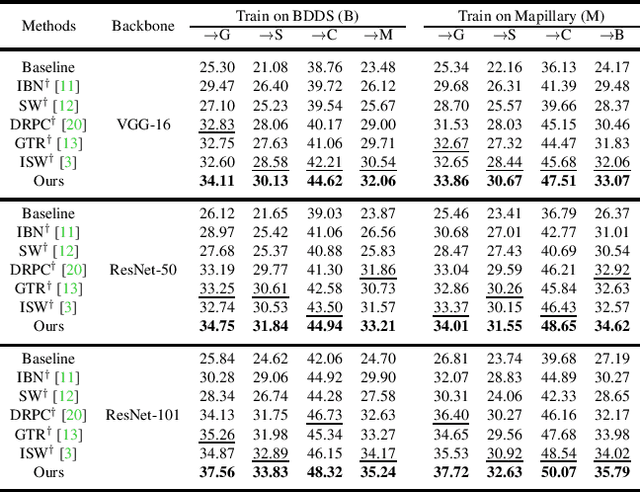
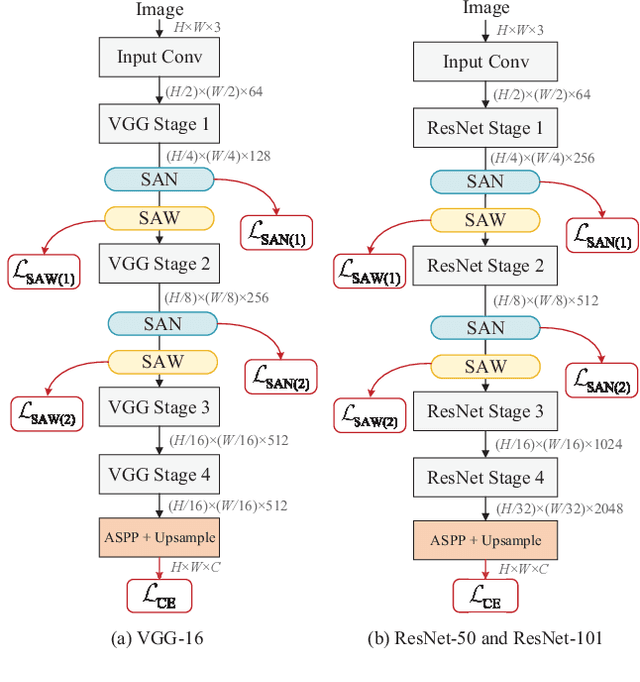
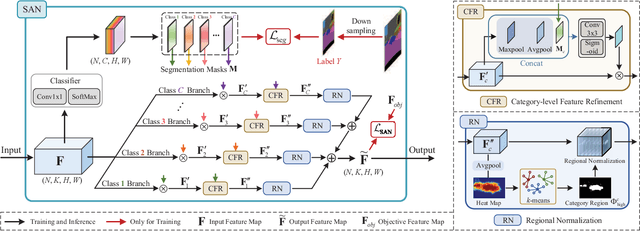

Deep models trained on source domain lack generalization when evaluated on unseen target domains with different data distributions. The problem becomes even more pronounced when we have no access to target domain samples for adaptation. In this paper, we address domain generalized semantic segmentation, where a segmentation model is trained to be domain-invariant without using any target domain data. Existing approaches to tackle this problem standardize data into a unified distribution. We argue that while such a standardization promotes global normalization, the resulting features are not discriminative enough to get clear segmentation boundaries. To enhance separation between categories while simultaneously promoting domain invariance, we propose a framework including two novel modules: Semantic-Aware Normalization (SAN) and Semantic-Aware Whitening (SAW). Specifically, SAN focuses on category-level center alignment between features from different image styles, while SAW enforces distributed alignment for the already center-aligned features. With the help of SAN and SAW, we encourage both intra-category compactness and inter-category separability. We validate our approach through extensive experiments on widely-used datasets (i.e. GTAV, SYNTHIA, Cityscapes, Mapillary and BDDS). Our approach shows significant improvements over existing state-of-the-art on various backbone networks. Code is available at https://github.com/leolyj/SAN-SAW
Deformation and Correspondence Aware Unsupervised Synthetic-to-Real Scene Flow Estimation for Point Clouds
Mar 31, 2022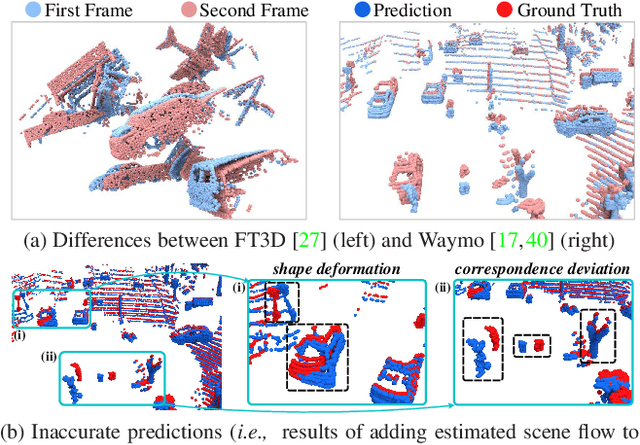
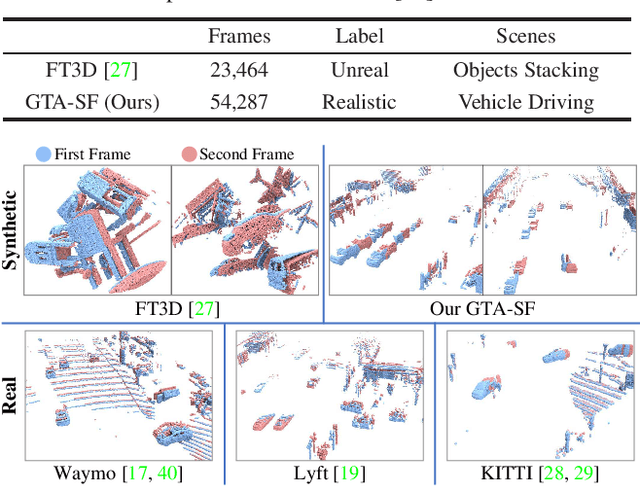
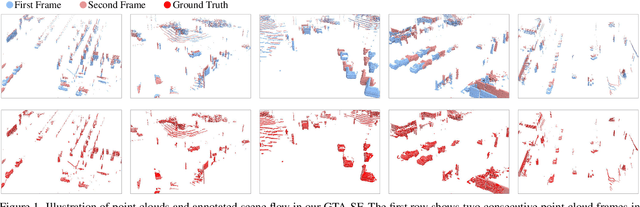
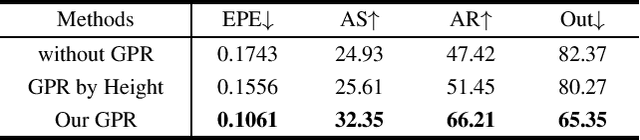
Point cloud scene flow estimation is of practical importance for dynamic scene navigation in autonomous driving. Since scene flow labels are hard to obtain, current methods train their models on synthetic data and transfer them to real scenes. However, large disparities between existing synthetic datasets and real scenes lead to poor model transfer. We make two major contributions to address that. First, we develop a point cloud collector and scene flow annotator for GTA-V engine to automatically obtain diverse realistic training samples without human intervention. With that, we develop a large-scale synthetic scene flow dataset GTA-SF. Second, we propose a mean-teacher-based domain adaptation framework that leverages self-generated pseudo-labels of the target domain. It also explicitly incorporates shape deformation regularization and surface correspondence refinement to address distortions and misalignments in domain transfer. Through extensive experiments, we show that our GTA-SF dataset leads to a consistent boost in model generalization to three real datasets (i.e., Waymo, Lyft and KITTI) as compared to the most widely used FT3D dataset. Moreover, our framework achieves superior adaptation performance on six source-target dataset pairs, remarkably closing the average domain gap by 60%. Data and codes are available at https://github.com/leolyj/DCA-SRSFE
Box2Seg: Learning Semantics of 3D Point Clouds with Box-Level Supervision
Jan 09, 2022
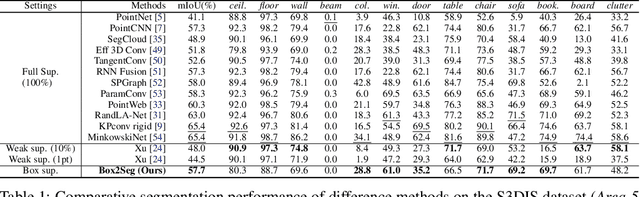
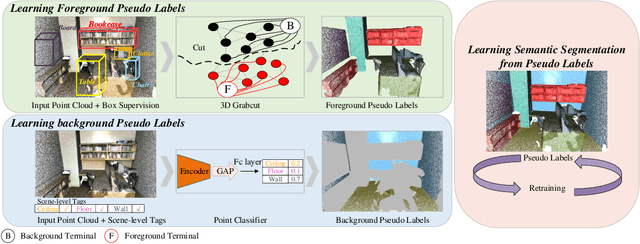
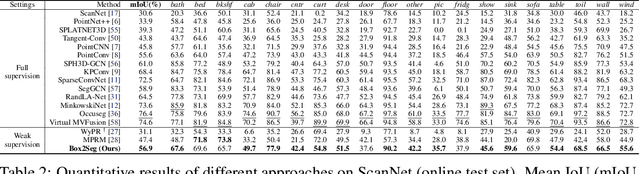
Learning dense point-wise semantics from unstructured 3D point clouds with fewer labels, although a realistic problem, has been under-explored in literature. While existing weakly supervised methods can effectively learn semantics with only a small fraction of point-level annotations, we find that the vanilla bounding box-level annotation is also informative for semantic segmentation of large-scale 3D point clouds. In this paper, we introduce a neural architecture, termed Box2Seg, to learn point-level semantics of 3D point clouds with bounding box-level supervision. The key to our approach is to generate accurate pseudo labels by exploring the geometric and topological structure inside and outside each bounding box. Specifically, an attention-based self-training (AST) technique and Point Class Activation Mapping (PCAM) are utilized to estimate pseudo-labels. The network is further trained and refined with pseudo labels. Experiments on two large-scale benchmarks including S3DIS and ScanNet demonstrate the competitive performance of the proposed method. In particular, the proposed network can be trained with cheap, or even off-the-shelf bounding box-level annotations and subcloud-level tags.
Mind Your Clever Neighbours: Unsupervised Person Re-identification via Adaptive Clustering Relationship Modeling
Dec 08, 2021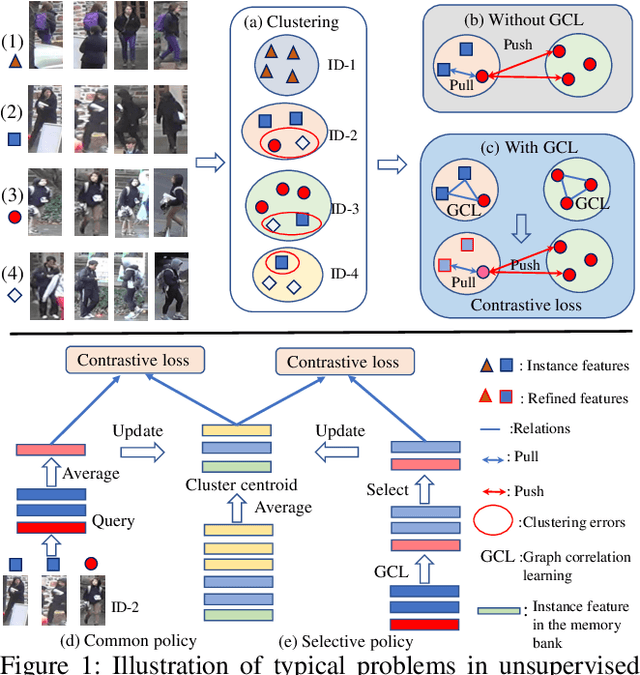
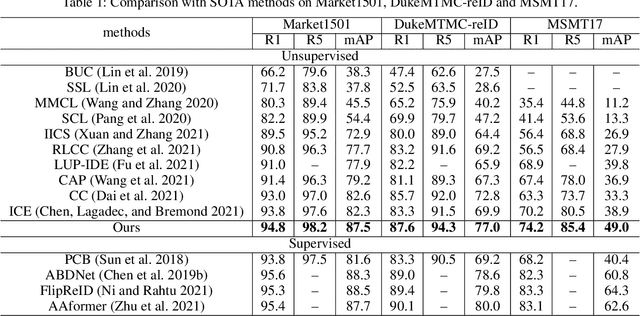
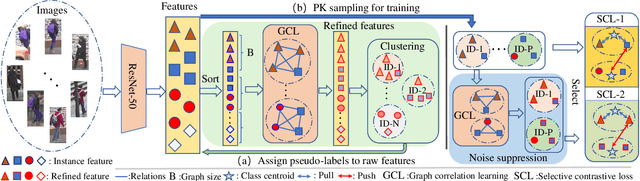
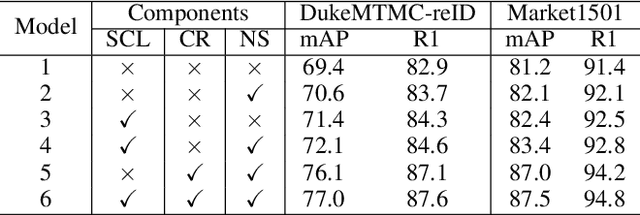
Unsupervised person re-identification (Re-ID) attracts increasing attention due to its potential to resolve the scalability problem of supervised Re-ID models. Most existing unsupervised methods adopt an iterative clustering mechanism, where the network was trained based on pseudo labels generated by unsupervised clustering. However, clustering errors are inevitable. To generate high-quality pseudo-labels and mitigate the impact of clustering errors, we propose a novel clustering relationship modeling framework for unsupervised person Re-ID. Specifically, before clustering, the relation between unlabeled images is explored based on a graph correlation learning (GCL) module and the refined features are then used for clustering to generate high-quality pseudo-labels.Thus, GCL adaptively mines the relationship between samples in a mini-batch to reduce the impact of abnormal clustering when training. To train the network more effectively, we further propose a selective contrastive learning (SCL) method with a selective memory bank update policy. Extensive experiments demonstrate that our method shows much better results than most state-of-the-art unsupervised methods on Market1501, DukeMTMC-reID and MSMT17 datasets. We will release the code for model reproduction.
Overcome Anterograde Forgetting with Cycled Memory Networks
Dec 04, 2021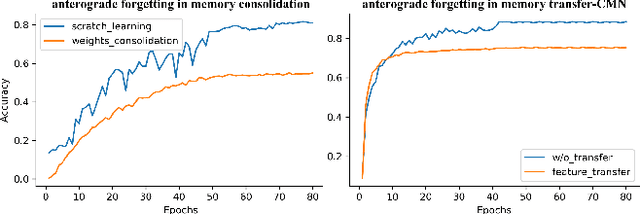
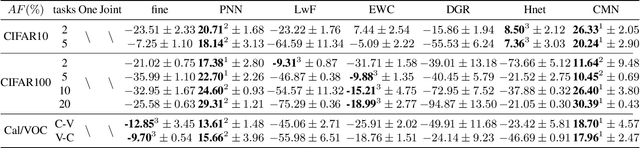
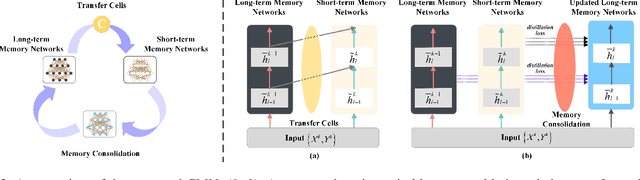
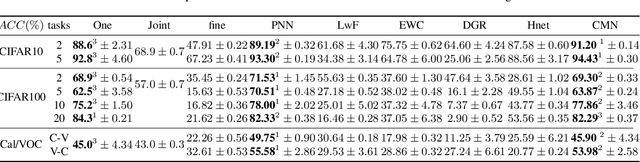
Learning from a sequence of tasks for a lifetime is essential for an agent towards artificial general intelligence. This requires the agent to continuously learn and memorize new knowledge without interference. This paper first demonstrates a fundamental issue of lifelong learning using neural networks, named anterograde forgetting, i.e., preserving and transferring memory may inhibit the learning of new knowledge. This is attributed to the fact that the learning capacity of a neural network will be reduced as it keeps memorizing historical knowledge, and the fact that conceptual confusion may occur as it transfers irrelevant old knowledge to the current task. This work proposes a general framework named Cycled Memory Networks (CMN) to address the anterograde forgetting in neural networks for lifelong learning. The CMN consists of two individual memory networks to store short-term and long-term memories to avoid capacity shrinkage. A transfer cell is designed to connect these two memory networks, enabling knowledge transfer from the long-term memory network to the short-term memory network to mitigate the conceptual confusion, and a memory consolidation mechanism is developed to integrate short-term knowledge into the long-term memory network for knowledge accumulation. Experimental results demonstrate that the CMN can effectively address the anterograde forgetting on several task-related, task-conflict, class-incremental and cross-domain benchmarks.
Reviewing continual learning from the perspective of human-level intelligence
Nov 23, 2021
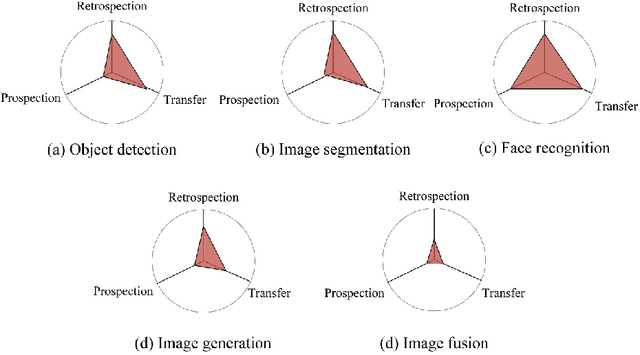
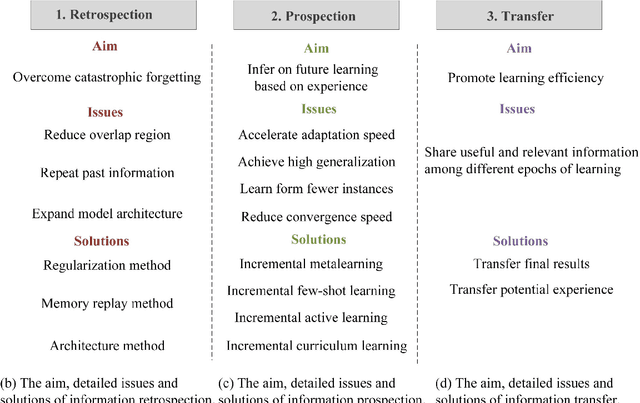
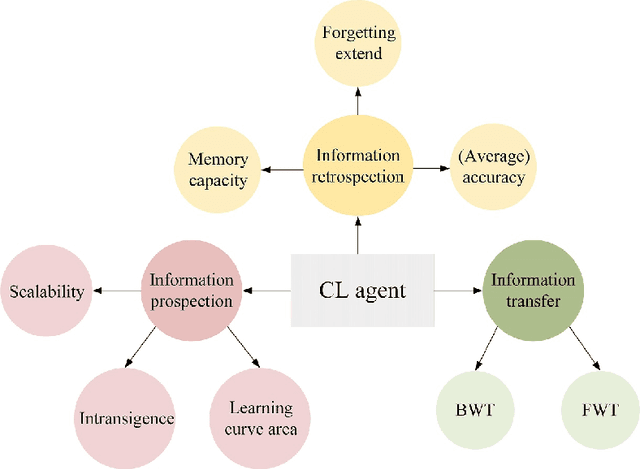
Humans' continual learning (CL) ability is closely related to Stability Versus Plasticity Dilemma that describes how humans achieve ongoing learning capacity and preservation for learned information. The notion of CL has always been present in artificial intelligence (AI) since its births. This paper proposes a comprehensive review of CL. Different from previous reviews that mainly focus on the catastrophic forgetting phenomenon in CL, this paper surveys CL from a more macroscopic perspective based on the Stability Versus Plasticity mechanism. Analogous to biological counterpart, "smart" AI agents are supposed to i) remember previously learned information (information retrospection); ii) infer on new information continuously (information prospection:); iii) transfer useful information (information transfer), to achieve high-level CL. According to the taxonomy, evaluation metrics, algorithms, applications as well as some open issues are then introduced. Our main contributions concern i) rechecking CL from the level of artificial general intelligence; ii) providing a detailed and extensive overview on CL topics; iii) presenting some novel ideas on the potential development of CL.
Sparse-to-dense Feature Matching: Intra and Inter domain Cross-modal Learning in Domain Adaptation for 3D Semantic Segmentation
Aug 08, 2021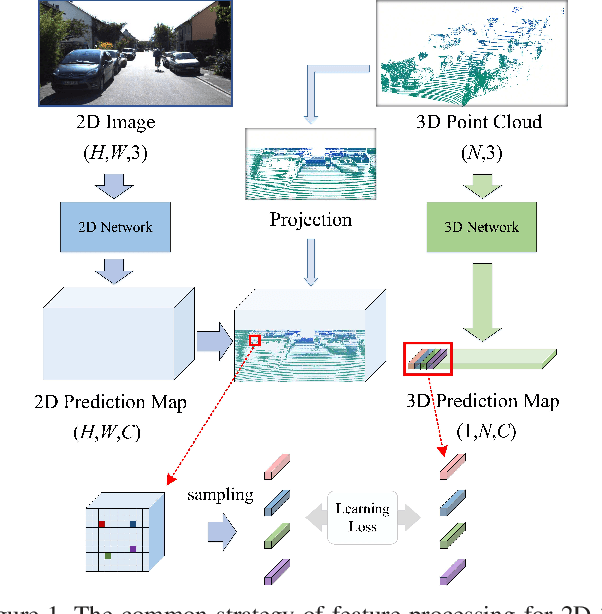
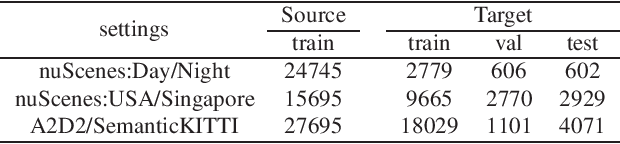
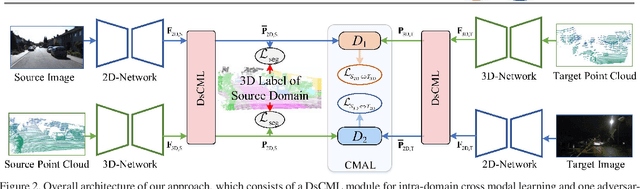
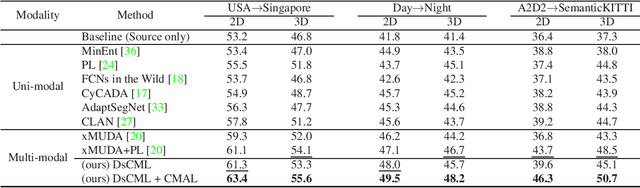
Domain adaptation is critical for success when confronting with the lack of annotations in a new domain. As the huge time consumption of labeling process on 3D point cloud, domain adaptation for 3D semantic segmentation is of great expectation. With the rise of multi-modal datasets, large amount of 2D images are accessible besides 3D point clouds. In light of this, we propose to further leverage 2D data for 3D domain adaptation by intra and inter domain cross modal learning. As for intra-domain cross modal learning, most existing works sample the dense 2D pixel-wise features into the same size with sparse 3D point-wise features, resulting in the abandon of numerous useful 2D features. To address this problem, we propose Dynamic sparse-to-dense Cross Modal Learning (DsCML) to increase the sufficiency of multi-modality information interaction for domain adaptation. For inter-domain cross modal learning, we further advance Cross Modal Adversarial Learning (CMAL) on 2D and 3D data which contains different semantic content aiming to promote high-level modal complementarity. We evaluate our model under various multi-modality domain adaptation settings including day-to-night, country-to-country and dataset-to-dataset, brings large improvements over both uni-modal and multi-modal domain adaptation methods on all settings.
Global and Local Texture Randomization for Synthetic-to-Real Semantic Segmentation
Aug 06, 2021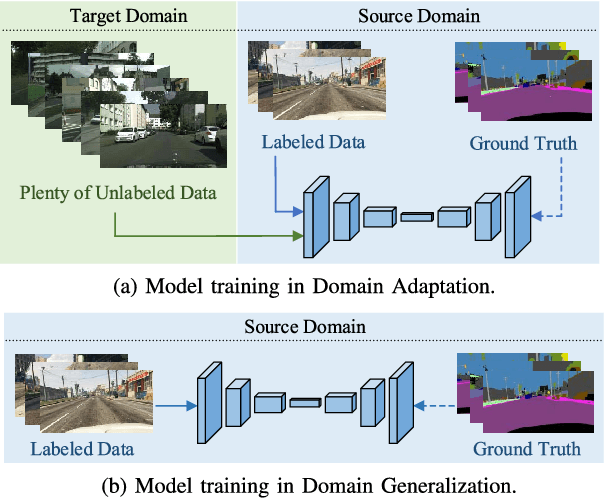
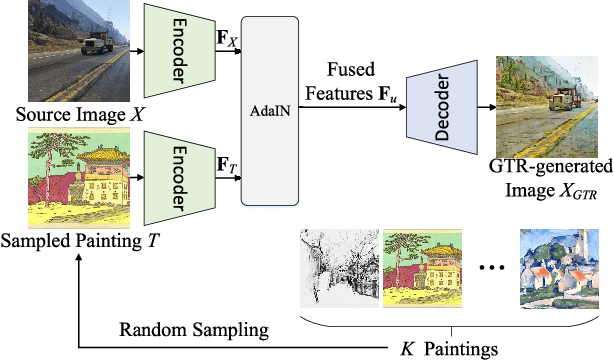
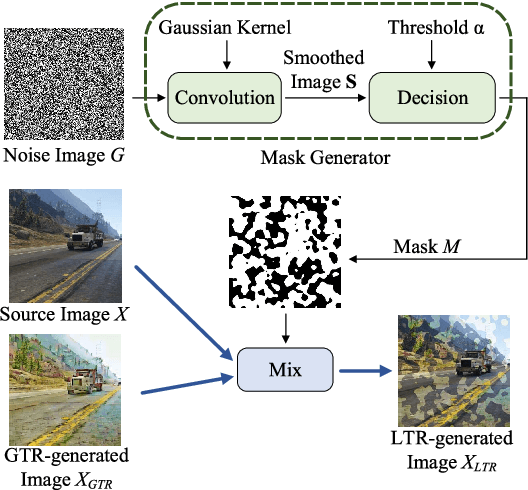
Semantic segmentation is a crucial image understanding task, where each pixel of image is categorized into a corresponding label. Since the pixel-wise labeling for ground-truth is tedious and labor intensive, in practical applications, many works exploit the synthetic images to train the model for real-word image semantic segmentation, i.e., Synthetic-to-Real Semantic Segmentation (SRSS). However, Deep Convolutional Neural Networks (CNNs) trained on the source synthetic data may not generalize well to the target real-world data. In this work, we propose two simple yet effective texture randomization mechanisms, Global Texture Randomization (GTR) and Local Texture Randomization (LTR), for Domain Generalization based SRSS. GTR is proposed to randomize the texture of source images into diverse unreal texture styles. It aims to alleviate the reliance of the network on texture while promoting the learning of the domain-invariant cues. In addition, we find the texture difference is not always occurred in entire image and may only appear in some local areas. Therefore, we further propose a LTR mechanism to generate diverse local regions for partially stylizing the source images. Finally, we implement a regularization of Consistency between GTR and LTR (CGL) aiming to harmonize the two proposed mechanisms during training. Extensive experiments on five publicly available datasets (i.e., GTA5, SYNTHIA, Cityscapes, BDDS and Mapillary) with various SRSS settings (i.e., GTA5/SYNTHIA to Cityscapes/BDDS/Mapillary) demonstrate that the proposed method is superior to the state-of-the-art methods for domain generalization based SRSS.