 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAGLE: Forensics of Deep Learning Backdoor Attack for Better Defense
Jan 16, 2023



Deep Learning backdoor attacks have a threat model similar to traditional cyber attacks. Attack forensics, a critical counter-measure for traditional cyber attacks, is hence of importance for defending model backdoor attacks. In this paper, we propose a novel model backdoor forensics technique. Given a few attack samples such as inputs with backdoor triggers, which may represent different types of backdoors, our technique automatically decomposes them to clean inputs and the corresponding triggers. It then clusters the triggers based on their properties to allow automatic attack categorization and summarization. Backdoor scanners can then be automatically synthesized to find other instances of the same type of backdoor in other models. Our evaluation on 2,532 pre-trained models, 10 popular attacks, and comparison with 9 baselines show that our technique is highly effective. The decomposed clean inputs and triggers closely resemble the ground truth. The synthesized scanners substantially outperform the vanilla versions of existing scanners that can hardly generalize to different kinds of attacks.
Backdoor Vulnerabilities in Normally Trained Deep Learning Models
Nov 29, 2022



We conduct a systematic study of backdoor vulnerabilities in normally trained Deep Learning models. They are as dangerous as backdoors injected by data poisoning because both can be equally exploited. We leverage 20 different types of injected backdoor attacks in the literature as the guidance and study their correspondences in normally trained models, which we call natural backdoor vulnerabilities. We find that natural backdoors are widely existing, with most injected backdoor attacks having natural correspondences. We categorize these natural backdoors and propose a general detection framework. It finds 315 natural backdoors in the 56 normally trained models downloaded from the Internet, covering all the different categories, while existing scanners designed for injected backdoors can at most detect 65 backdoors. We also study the root causes and defense of natural backdoors.
FLIP: A Provable Defense Framework for Backdoor Mitigation in Federated Learning
Oct 23, 2022



Federated Learning (FL) is a distributed learning paradigm that enables different parties to train a model together for high quality and strong privacy protection. In this scenario, individual participants may get compromised and perform backdoor attacks by poisoning the data (or gradients). Existing work on robust aggregation and certified FL robustness does not study how hardening benign clients can affect the global model (and the malicious clients). In this work, we theoretically analyze the connection among cross-entropy loss, attack success rate, and clean accuracy in this setting. Moreover, we propose a trigger reverse engineering based defense and show that our method can achieve robustness improvement with guarantee (i.e., reducing the attack success rate) without affecting benign accuracy. We conduct comprehensive experiments across different datasets and attack settings. Our results on eight competing SOTA defense methods show the empirical superiority of our method on both single-shot and continuous FL backdoor attacks.
Efficient Image Super-Resolution using Vast-Receptive-Field Attention
Oct 12, 2022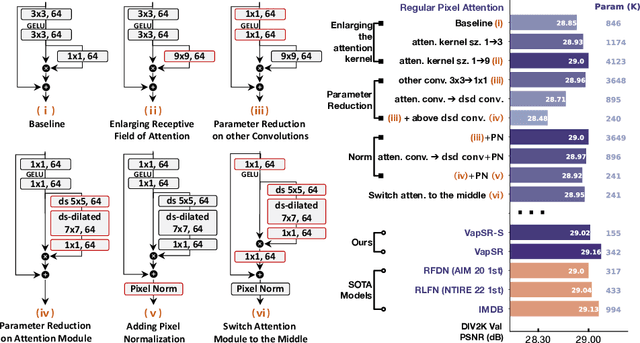
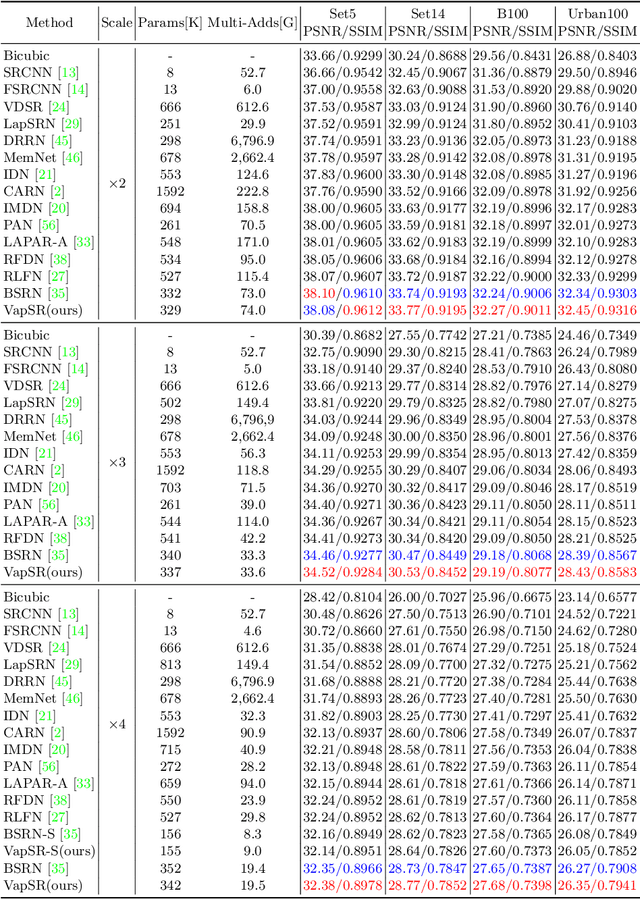
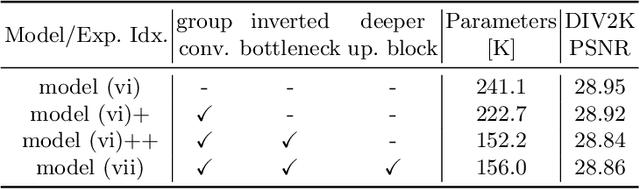
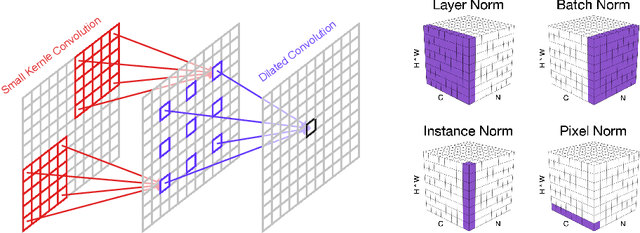
The attention mechanism plays a pivotal role in designing advanced super-resolution (SR) networks. In this work, we design an efficient SR network by improving the attention mechanism. We start from a simple pixel attention module and gradually modify it to achieve better super-resolution performance with reduced parameters. The specific approaches include: (1) increasing the receptive field of the attention branch, (2) replacing large dense convolution kernels with depth-wise separable convolutions, and (3) introducing pixel normalization. These approaches paint a clear evolutionary roadmap for the design of attention mechanisms. Based on these observations, we propose VapSR, the VAst-receptive-field Pixel attention network. Experiments demonstrate the superior performance of VapSR. VapSR outperforms the present lightweight networks with even fewer parameters. And the light version of VapSR can use only 21.68% and 28.18% parameters of IMDB and RFDN to achieve similar performances to those networks. The code and models are available at url{https://github.com/zhoumumu/VapSR.
Traffic Analytics Development Kits (TADK): Enable Real-Time AI Inference in Networking Apps
Aug 16, 2022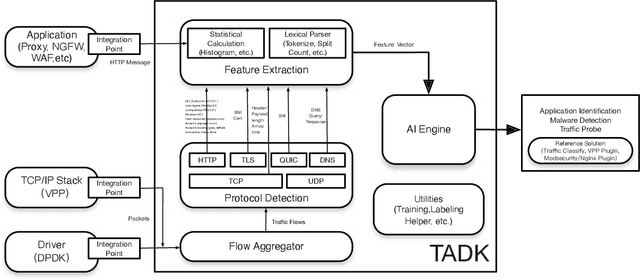
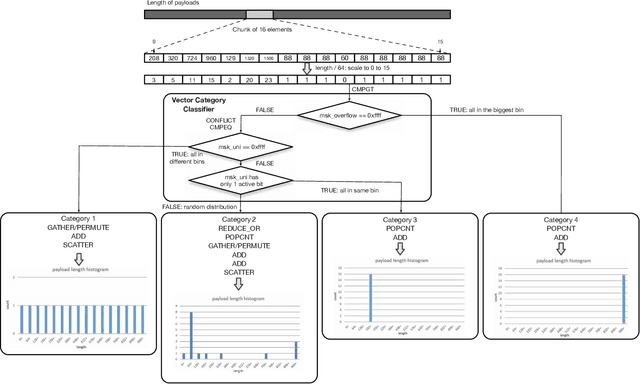
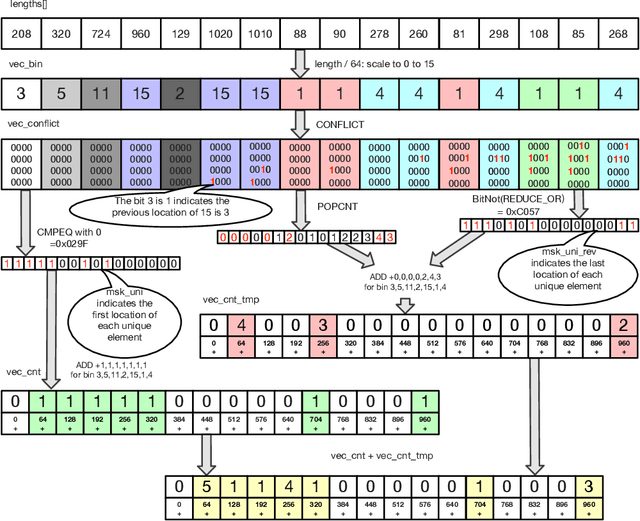
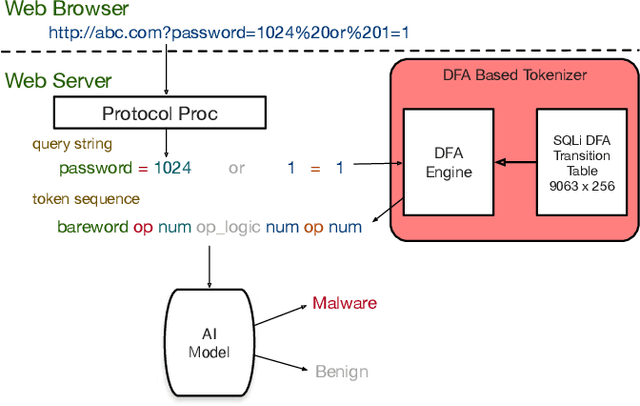
Sophisticated traffic analytics, such as the encrypted traffic analytics and unknown malware detection, emphasizes the need for advanced methods to analyze the network traffic. Traditional methods of using fixed patterns, signature matching, and rules to detect known patterns in network traffic are being replaced with AI (Artificial Intelligence) driven algorithms. However, the absence of a high-performance AI networking-specific framework makes deploying real-time AI-based processing within networking workloads impossible. In this paper, we describe the design of Traffic Analytics Development Kits (TADK), an industry-standard framework specific for AI-based networking workloads processing. TADK can provide real-time AI-based networking workload processing in networking equipment from the data center out to the edge without the need for specialized hardware (e.g., GPUs, Neural Processing Unit, and so on). We have deployed TADK in commodity WAF and 5G UPF, and the evaluation result shows that TADK can achieve a throughput up to 35.3Gbps per core on traffic feature extraction, 6.5Gbps per core on traffic classification, and can decrease SQLi/XSS detection down to 4.5us per request with higher accuracy than fixed pattern solution.
DECK: Model Hardening for Defending Pervasive Backdoors
Jun 18, 2022
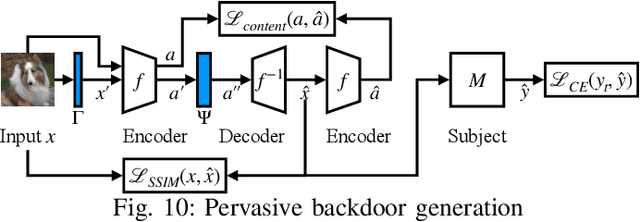

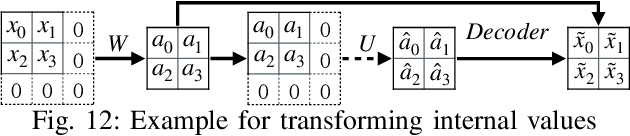
Pervasive backdoors are triggered by dynamic and pervasive input perturbations. They can be intentionally injected by attackers or naturally exist in normally trained models. They have a different nature from the traditional static and localized backdoors that can be triggered by perturbing a small input area with some fixed pattern, e.g., a patch with solid color. Existing defense techniques are highly effective for traditional backdoors. However, they may not work well for pervasive backdoors, especially regarding backdoor removal and model hardening. In this paper, we propose a novel model hardening technique against pervasive backdoors, including both natural and injected backdoors. We develop a general pervasive attack based on an encoder-decoder architecture enhanced with a special transformation layer. The attack can model a wide range of existing pervasive backdoor attacks and quantify them by class distances. As such, using the samples derived from our attack in adversarial training can harden a model against these backdoor vulnerabilities. Our evaluation on 9 datasets with 15 model structures shows that our technique can enlarge class distances by 59.65% on average with less than 1% accuracy degradation and no robustness loss, outperforming five hardening techniques such as adversarial training, universal adversarial training, MOTH, etc. It can reduce the attack success rate of six pervasive backdoor attacks from 99.06% to 1.94%, surpassing seven state-of-the-art backdoor removal techniques.
Blueprint Separable Residual Network for Efficient Image Super-Resolution
May 12, 2022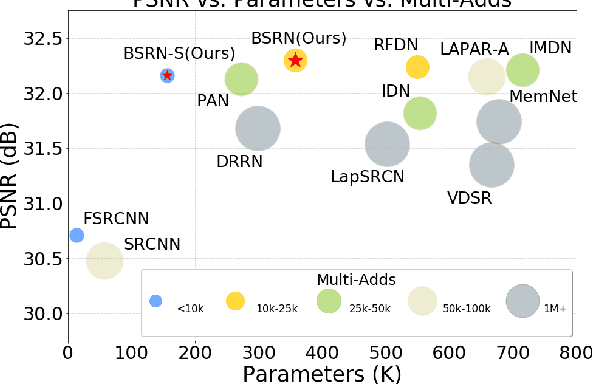



Recent advances in single image super-resolution (SISR) have achieved extraordinary performance, but the computational cost is too heavy to apply in edge devices. To alleviate this problem, many novel and effective solutions have been proposed. Convolutional neural network (CNN) with the attention mechanism has attracted increasing attention due to its efficiency and effectiveness. However, there is still redundancy in the convolution operation. In this paper, we propose Blueprint Separable Residual Network (BSRN) containing two efficient designs. One is the usage of blueprint separable convolution (BSConv), which takes place of the redundant convolution operation. The other is to enhance the model ability by introducing more effective attention modules. The experimental results show that BSRN achieves state-of-the-art performance among existing efficient SR methods. Moreover, a smaller variant of our model BSRN-S won the first place in model complexity track of NTIRE 2022 Efficient SR Challenge. The code is available at https://github.com/xiaom233/BSRN.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Constrained Optimization with Dynamic Bound-scaling for Effective NLPBackdoor Defense
Feb 11, 2022
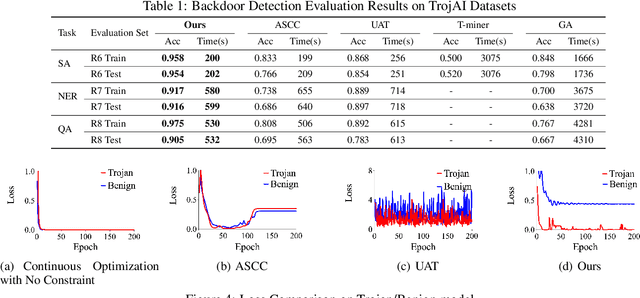
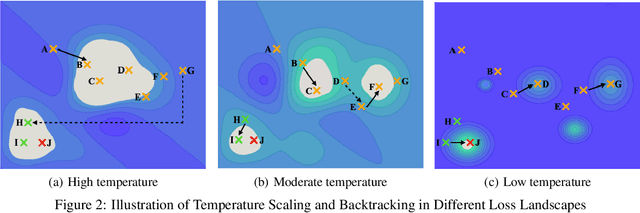
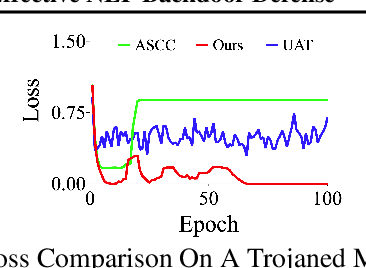
We develop a novel optimization method for NLPbackdoor inversion. We leverage a dynamically reducing temperature coefficient in the softmax function to provide changing loss landscapes to the optimizer such that the process gradually focuses on the ground truth trigger, which is denoted as a one-hot value in a convex hull. Our method also features a temperature rollback mechanism to step away from local optimals, exploiting the observation that local optimals can be easily deter-mined in NLP trigger inversion (while not in general optimization). We evaluate the technique on over 1600 models (with roughly half of them having injected backdoors) on 3 prevailing NLP tasks, with 4 different backdoor attacks and 7 architectures. Our results show that the technique is able to effectively and efficiently detect and remove backdoors, outperforming 4 baseline methods.
EX-RAY: Distinguishing Injected Backdoor from Natural Features in Neural Networks by Examining Differential Feature Symmetry
Mar 17, 2021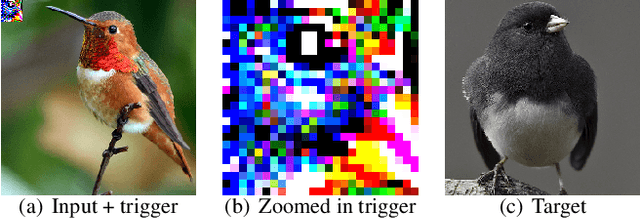
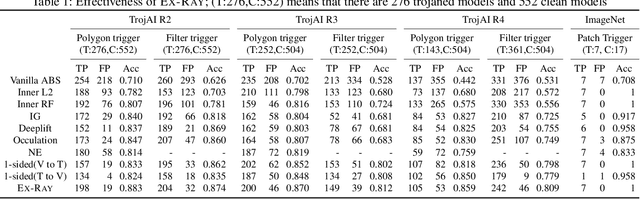

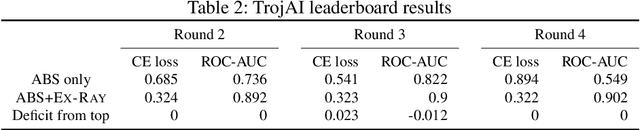
Backdoor attack injects malicious behavior to models such that inputs embedded with triggers are misclassified to a target label desired by the attacker. However, natural features may behave like triggers, causing misclassification once embedded. While they are inevitable, mis-recognizing them as injected triggers causes false warnings in backdoor scanning. A prominent challenge is hence to distinguish natural features and injected backdoors. We develop a novel symmetric feature differencing method that identifies a smallest set of features separating two classes. A backdoor is considered injected if the corresponding trigger consists of features different from the set of features distinguishing the victim and target classes. We evaluate the technique on thousands of models, including both clean and trojaned models, from the TrojAI rounds 2-4 competitions and a number of models on ImageNet. Existing backdoor scanning techniques may produce hundreds of false positives (i.e., clean models recognized as trojaned). Our technique removes 78-100% of the false positives (by a state-of-the-art scanner ABS) with a small increase of false negatives by 0-30%, achieving 17-41% overall accuracy improvement, and facilitates achieving top performance on the leaderboard. It also boosts performance of other scanners. It outperforms false positive removal methods using L2 distance and attribution techniques. We also demonstrate its potential in detecting a number of semantic backdoor attacks.