 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntenTest: Stress Testing for Intent Integrity in API-Calling LLM Agents
Jun 09, 2025LLM agents are increasingly deployed to automate real-world tasks by invoking APIs through natural language instructions. While powerful, they often suffer from misinterpretation of user intent, leading to the agent's actions that diverge from the user's intended goal, especially as external toolkits evolve. Traditional software testing assumes structured inputs and thus falls short in handling the ambiguity of natural language. We introduce IntenTest, an API-centric stress testing framework that systematically uncovers intent integrity violations in LLM agents. Unlike prior work focused on fixed benchmarks or adversarial inputs, IntenTest generates realistic tasks based on toolkits' documentation and applies targeted mutations to expose subtle agent errors while preserving user intent. To guide testing, we propose semantic partitioning, which organizes natural language tasks into meaningful categories based on toolkit API parameters and their equivalence classes. Within each partition, seed tasks are mutated and ranked by a lightweight predictor that estimates the likelihood of triggering agent errors. To enhance efficiency, IntenTest maintains a datatype-aware strategy memory that retrieves and adapts effective mutation patterns from past cases. Experiments on 80 toolkit APIs demonstrate that IntenTest effectively uncovers intent integrity violations, significantly outperforming baselines in both error-exposing rate and query efficiency. Moreover, IntenTest generalizes well to stronger target models using smaller LLMs for test generation, and adapts to evolving APIs across domains.
DIGIMON: Diagnosis and Mitigation of Sampling Skew for Reinforcement Learning based Meta-Planner in Robot Navigation
Sep 17, 2024



Robot navigation is increasingly crucial across applications like delivery services and warehouse management. The integration of Reinforcement Learning (RL) with classical planning has given rise to meta-planners that combine the adaptability of RL with the explainable decision-making of classical planners. However, the exploration capabilities of RL-based meta-planners during training are often constrained by the capabilities of the underlying classical planners. This constraint can result in limited exploration, thereby leading to sampling skew issues. To address these issues, our paper introduces a novel framework, DIGIMON, which begins with behavior-guided diagnosis for exploration bottlenecks within the meta-planner and follows up with a mitigation strategy that conducts up-sampling from diagnosed bottleneck data. Our evaluation shows 13.5%+ improvement in navigation performance, greater robustness in out-of-distribution environments, and a 4x boost in training efficiency. DIGIMON is designed as a versatile, plug-and-play solution, allowing seamless integration into various RL-based meta-planners.
ROCAS: Root Cause Analysis of Autonomous Driving Accidents via Cyber-Physical Co-mutation
Sep 12, 2024



As Autonomous driving systems (ADS) have transformed our daily life, safety of ADS is of growing significance. While various testing approaches have emerged to enhance the ADS reliability, a crucial gap remains in understanding the accidents causes. Such post-accident analysis is paramount and beneficial for enhancing ADS safety and reliability. Existing cyber-physical system (CPS) root cause analysis techniques are mainly designed for drones and cannot handle the unique challenges introduced by more complex physical environments and deep learning models deployed in ADS. In this paper, we address the gap by offering a formal definition of ADS root cause analysis problem and introducing ROCAS, a novel ADS root cause analysis framework featuring cyber-physical co-mutation. Our technique uniquely leverages both physical and cyber mutation that can precisely identify the accident-trigger entity and pinpoint the misconfiguration of the target ADS responsible for an accident. We further design a differential analysis to identify the responsible module to reduce search space for the misconfiguration. We study 12 categories of ADS accidents and demonstrate the effectiveness and efficiency of ROCAS in narrowing down search space and pinpointing the misconfiguration. We also show detailed case studies on how the identified misconfiguration helps understand rationale behind accidents.
BadPart: Unified Black-box Adversarial Patch Attacks against Pixel-wise Regression Tasks
Apr 01, 2024



Pixel-wise regression tasks (e.g., monocular depth estimation (MDE) and optical flow estimation (OFE)) have been widely involved in our daily life in applications like autonomous driving, augmented reality and video composition. Although certain applications are security-critical or bear societal significance, the adversarial robustness of such models are not sufficiently studied, especially in the black-box scenario. In this work, we introduce the first unified black-box adversarial patch attack framework against pixel-wise regression tasks, aiming to identify the vulnerabilities of these models under query-based black-box attacks. We propose a novel square-based adversarial patch optimization framework and employ probabilistic square sampling and score-based gradient estimation techniques to generate the patch effectively and efficiently, overcoming the scalability problem of previous black-box patch attacks. Our attack prototype, named BadPart, is evaluated on both MDE and OFE tasks, utilizing a total of 7 models. BadPart surpasses 3 baseline methods in terms of both attack performance and efficiency. We also apply BadPart on the Google online service for portrait depth estimation, causing 43.5% relative distance error with 50K queries. State-of-the-art (SOTA) countermeasures cannot defend our attack effectively.
LOTUS: Evasive and Resilient Backdoor Attacks through Sub-Partitioning
Mar 25, 2024



Backdoor attack poses a significant security threat to Deep Learning applications. Existing attacks are often not evasive to established backdoor detection techniques. This susceptibility primarily stems from the fact that these attacks typically leverage a universal trigger pattern or transformation function, such that the trigger can cause misclassification for any input. In response to this, recent papers have introduced attacks using sample-specific invisible triggers crafted through special transformation functions. While these approaches manage to evade detection to some extent, they reveal vulnerability to existing backdoor mitigation techniques. To address and enhance both evasiveness and resilience, we introduce a novel backdoor attack LOTUS. Specifically, it leverages a secret function to separate samples in the victim class into a set of partitions and applies unique triggers to different partitions. Furthermore, LOTUS incorporates an effective trigger focusing mechanism, ensuring only the trigger corresponding to the partition can induce the backdoor behavior. Extensive experimental results show that LOTUS can achieve high attack success rate across 4 datasets and 7 model structures, and effectively evading 13 backdoor detection and mitigation techniques. The code is available at https://github.com/Megum1/LOTUS.
Fusion is Not Enough: Single-Modal Attacks to Compromise Fusion Models in Autonomous Driving
Apr 28, 2023



Multi-sensor fusion (MSF) is widely adopted for perception in autonomous vehicles (AVs), particularly for the task of 3D object detection with camera and LiDAR sensors. The rationale behind fusion is to capitalize on the strengths of each modality while mitigating their limitations. The exceptional and leading performance of fusion models has been demonstrated by advanced deep neural network (DNN)-based fusion techniques. Fusion models are also perceived as more robust to attacks compared to single-modal ones due to the redundant information in multiple modalities. In this work, we challenge this perspective with single-modal attacks that targets the camera modality, which is considered less significant in fusion but more affordable for attackers. We argue that the weakest link of fusion models depends on their most vulnerable modality, and propose an attack framework that targets advanced camera-LiDAR fusion models with adversarial patches. Our approach employs a two-stage optimization-based strategy that first comprehensively assesses vulnerable image areas under adversarial attacks, and then applies customized attack strategies to different fusion models, generating deployable patches. Evaluations with five state-of-the-art camera-LiDAR fusion models on a real-world dataset show that our attacks successfully compromise all models. Our approach can either reduce the mean average precision (mAP) of detection performance from 0.824 to 0.353 or degrade the detection score of the target object from 0.727 to 0.151 on average, demonstrating the effectiveness and practicality of our proposed attack framework.
Detecting Backdoors in Pre-trained Encoders
Mar 23, 2023



Self-supervised learning in computer vision trains on unlabeled data, such as images or (image, text) pairs, to obtain an image encoder that learns high-quality embeddings for input data. Emerging backdoor attacks towards encoders expose crucial vulnerabilities of self-supervised learning, since downstream classifiers (even further trained on clean data) may inherit backdoor behaviors from encoders. Existing backdoor detection methods mainly focus on supervised learning settings and cannot handle pre-trained encoders especially when input labels are not available. In this paper, we propose DECREE, the first backdoor detection approach for pre-trained encoders, requiring neither classifier headers nor input labels. We evaluate DECREE on over 400 encoders trojaned under 3 paradigms. We show the effectiveness of our method on image encoders pre-trained on ImageNet and OpenAI's CLIP 400 million image-text pairs. Our method consistently has a high detection accuracy even if we have only limited or no access to the pre-training dataset.
BEAGLE: Forensics of Deep Learning Backdoor Attack for Better Defense
Jan 16, 2023



Deep Learning backdoor attacks have a threat model similar to traditional cyber attacks. Attack forensics, a critical counter-measure for traditional cyber attacks, is hence of importance for defending model backdoor attacks. In this paper, we propose a novel model backdoor forensics technique. Given a few attack samples such as inputs with backdoor triggers, which may represent different types of backdoors, our technique automatically decomposes them to clean inputs and the corresponding triggers. It then clusters the triggers based on their properties to allow automatic attack categorization and summarization. Backdoor scanners can then be automatically synthesized to find other instances of the same type of backdoor in other models. Our evaluation on 2,532 pre-trained models, 10 popular attacks, and comparison with 9 baselines show that our technique is highly effective. The decomposed clean inputs and triggers closely resemble the ground truth. The synthesized scanners substantially outperform the vanilla versions of existing scanners that can hardly generalize to different kinds of attacks.
FLIP: A Provable Defense Framework for Backdoor Mitigation in Federated Learning
Oct 23, 2022



Federated Learning (FL) is a distributed learning paradigm that enables different parties to train a model together for high quality and strong privacy protection. In this scenario, individual participants may get compromised and perform backdoor attacks by poisoning the data (or gradients). Existing work on robust aggregation and certified FL robustness does not study how hardening benign clients can affect the global model (and the malicious clients). In this work, we theoretically analyze the connection among cross-entropy loss, attack success rate, and clean accuracy in this setting. Moreover, we propose a trigger reverse engineering based defense and show that our method can achieve robustness improvement with guarantee (i.e., reducing the attack success rate) without affecting benign accuracy. We conduct comprehensive experiments across different datasets and attack settings. Our results on eight competing SOTA defense methods show the empirical superiority of our method on both single-shot and continuous FL backdoor attacks.
Graph-to-Tree Neural Networks for Learning Structured Input-Output Translation with Applications to Semantic Parsing and Math Word Problem
Apr 07, 2020
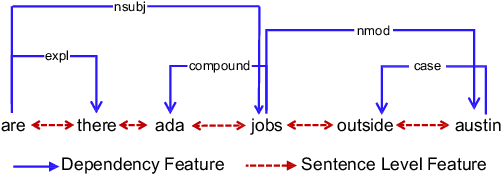
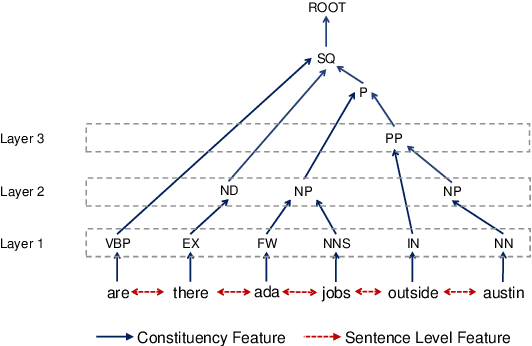
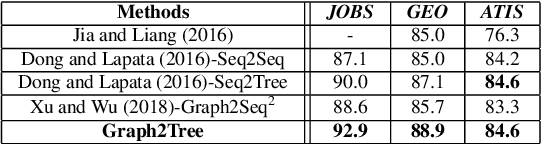
The celebrated Seq2Seq technique and its numerous variants achieve excellent performance on many tasks such as neural machine translation, semantic parsing, and math word problem solving. However, these models either only consider input objects as sequences while ignoring the important structural information for encoding, or they simply treat output objects as sequence outputs instead of structural objects for decoding. In this paper, we present a novel Graph-to-Tree Neural Networks, namely Graph2Tree consisting of a graph encoder and a hierarchical tree decoder, that encodes an augmented graph-structured input and decodes a tree-structured output. In particular, we investigated our model for solving two problems, neural semantic parsing and math word problem. Our extensive experiments demonstrate that our Graph2Tree model outperforms or matches the performance of other state-of-the-art models on these tasks.