 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training Co-evolutionary Protein Representation via A Pairwise Masked Language Model
Oct 29, 2021

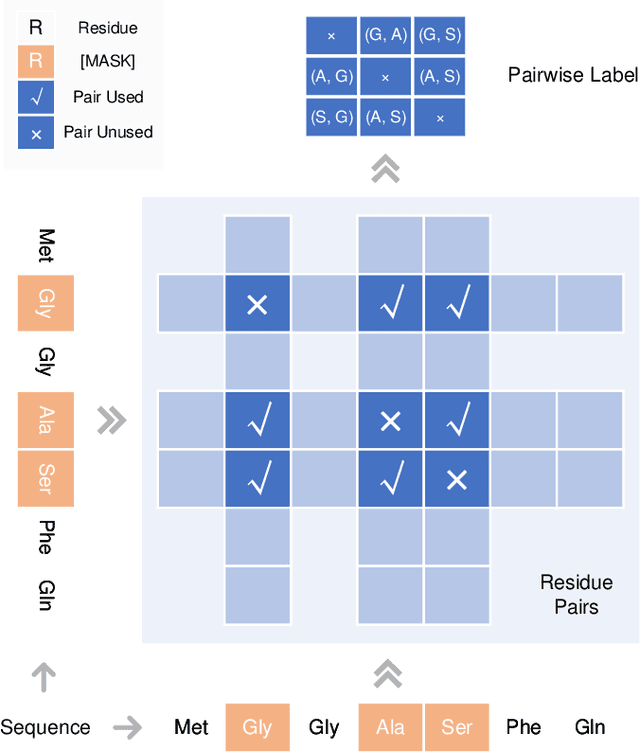

Understanding protein sequences is vital and urgent for biology, healthcare, and medicine. Labeling approaches are expensive yet time-consuming, while the amount of unlabeled data is increasing quite faster than that of the labeled data due to low-cost, high-throughput sequencing methods. In order to extract knowledge from these unlabeled data, representation learning is of significant value for protein-related tasks and has great potential for helping us learn more about protein functions and structures. The key problem in the protein sequence representation learning is to capture the co-evolutionary information reflected by the inter-residue co-variation in the sequences. Instead of leveraging multiple sequence alignment as is usually done, we propose a novel method to capture this information directly by pre-training via a dedicated language model, i.e., Pairwise Masked Language Model (PMLM). In a conventional masked language model, the masked tokens are modeled by conditioning on the unmasked tokens only, but processed independently to each other. However, our proposed PMLM takes the dependency among masked tokens into consideration, i.e., the probability of a token pair is not equal to the product of the probability of the two tokens. By applying this model, the pre-trained encoder is able to generate a better representation for protein sequences. Our result shows that the proposed method can effectively capture the inter-residue correlations and improves the performance of contact prediction by up to 9% compared to the MLM baseline under the same setting. The proposed model also significantly outperforms the MSA baseline by more than 7% on the TAPE contact prediction benchmark when pre-trained on a subset of the sequence database which the MSA is generated from, revealing the potential of the sequence pre-training method to surpass MSA based methods in general.
HIST: A Graph-based Framework for Stock Trend Forecasting via Mining Concept-Oriented Shared Information
Oct 26, 2021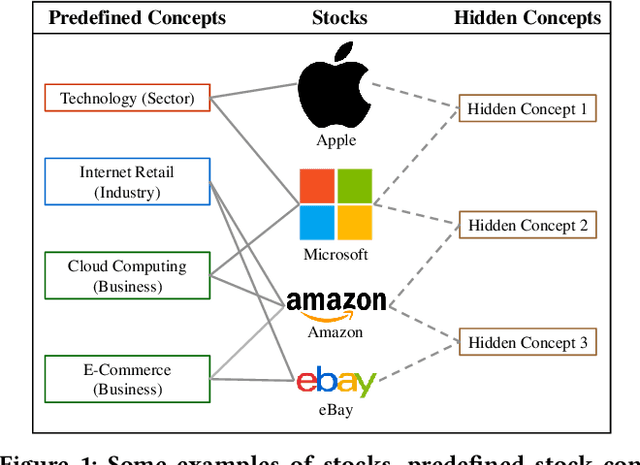
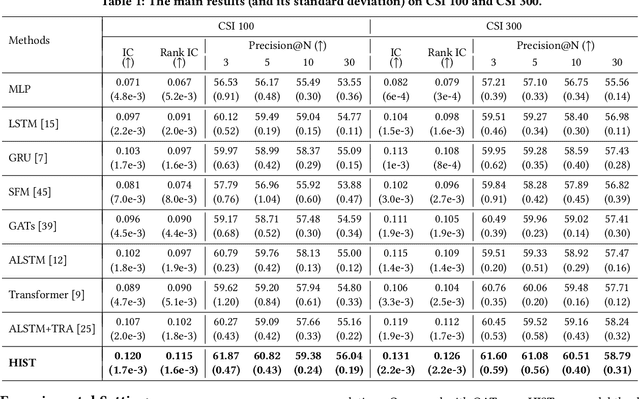
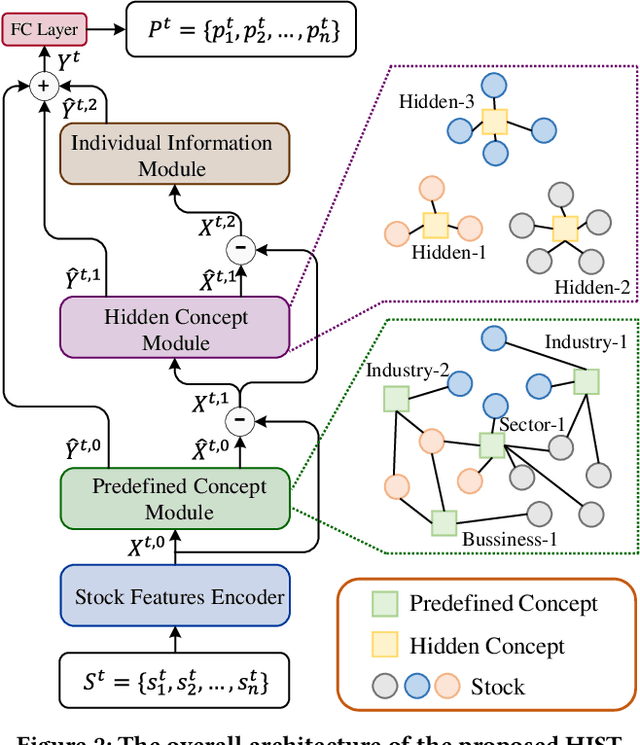
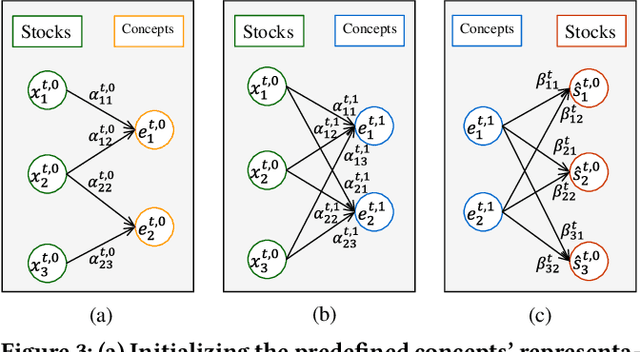
Stock trend forecasting, which forecasts stock prices' future trends, plays an essential role in investment. The stocks in a market can share information so that their stock prices are highly correlated. Several methods were recently proposed to mine the shared information through stock concepts (e.g., technology, Internet Retail) extracted from the Web to improve the forecasting results. However, previous work assumes the connections between stocks and concepts are stationary, and neglects the dynamic relevance between stocks and concepts, limiting the forecasting results. Moreover, existing methods overlook the invaluable shared information carried by hidden concepts, which measure stocks' commonness beyond the manually defined stock concepts. To overcome the shortcomings of previous work, we proposed a novel stock trend forecasting framework that can adequately mine the concept-oriented shared information from predefined concepts and hidden concepts. The proposed framework simultaneously utilize the stock's shared information and individual information to improve the stock trend forecasting performance. Experimental results on the real-world tasks demonstrate the efficiency of our framework on stock trend forecasting. The investment simulation shows that our framework can achieve a higher investment return than the baselines.
Discovering Drug-Target Interaction Knowledge from Biomedical Literature
Sep 27, 2021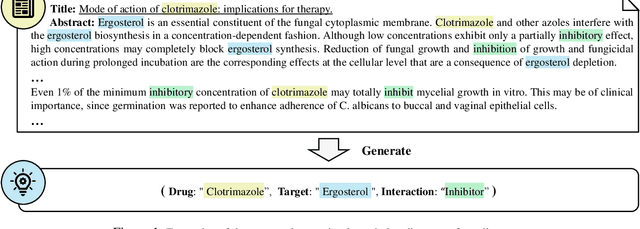

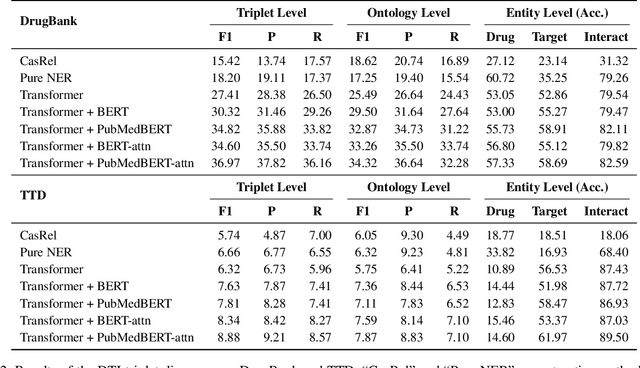
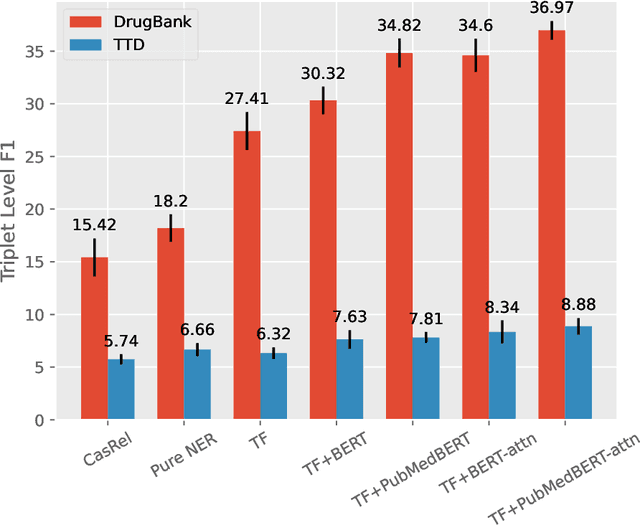
The Interaction between Drugs and Targets (DTI) in human body plays a crucial role in biomedical science and applications. As millions of papers come out every year in the biomedical domain, automatically discovering DTI knowledge from biomedical literature, which are usually triplets about drugs, targets and their interaction, becomes an urgent demand in the industry. Existing methods of discovering biological knowledge are mainly extractive approaches that often require detailed annotations (e.g., all mentions of biological entities, relations between every two entity mentions, etc.). However, it is difficult and costly to obtain sufficient annotations due to the requirement of expert knowledge from biomedical domains. To overcome these difficulties, we explore the first end-to-end solution for this task by using generative approaches. We regard the DTI triplets as a sequence and use a Transformer-based model to directly generate them without using the detailed annotations of entities and relations. Further, we propose a semi-supervised method, which leverages the aforementioned end-to-end model to filter unlabeled literature and label them. Experimental results show that our method significantly outperforms extractive baselines on DTI discovery. We also create a dataset, KD-DTI, to advance this task and will release it to the community.
Dual-view Molecule Pre-training
Jun 17, 2021
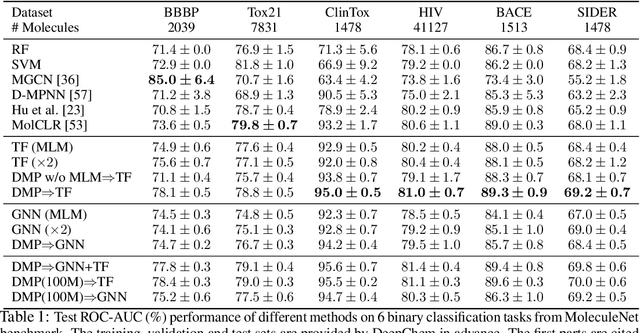
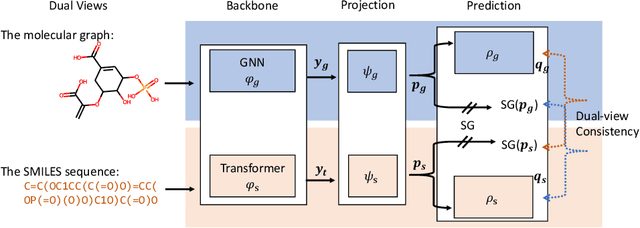
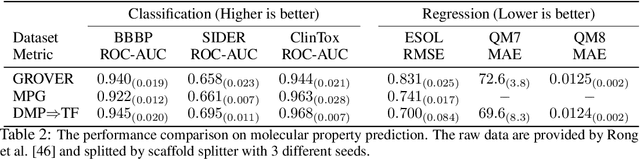
Inspired by its success in natural language processing and computer vision, pre-training has attracted substantial attention in cheminformatics and bioinformatics, especially for molecule based tasks. A molecule can be represented by either a graph (where atoms are connected by bonds) or a SMILES sequence (where depth-first-search is applied to the molecular graph with specific rules). Existing works on molecule pre-training use either graph representations only or SMILES representations only. In this work, we propose to leverage both the representations and design a new pre-training algorithm, dual-view molecule pre-training (briefly, DMP), that can effectively combine the strengths of both types of molecule representations. The model of DMP consists of two branches: a Transformer branch that takes the SMILES sequence of a molecule as input, and a GNN branch that takes a molecular graph as input. The training of DMP contains three tasks: (1) predicting masked tokens in a SMILES sequence by the Transformer branch, (2) predicting masked atoms in a molecular graph by the GNN branch, and (3) maximizing the consistency between the two high-level representations output by the Transformer and GNN branches separately. After pre-training, we can use either the Transformer branch (this one is recommended according to empirical results), the GNN branch, or both for downstream tasks. DMP is tested on nine molecular property prediction tasks and achieves state-of-the-art performances on seven of them. Furthermore, we test DMP on three retrosynthesis tasks and achieve state-of-the-result on the USPTO-full dataset. Our code will be released soon.
UniDrop: A Simple yet Effective Technique to Improve Transformer without Extra Cost
Apr 11, 2021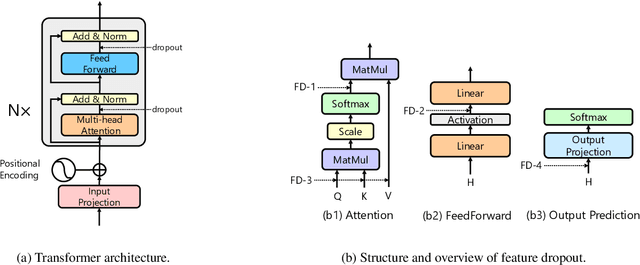

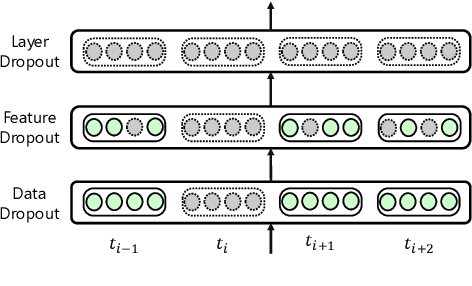

Transformer architecture achieves great success in abundant natural language processing tasks. The over-parameterization of the Transformer model has motivated plenty of works to alleviate its overfitting for superior performances. With some explorations, we find simple techniques such as dropout, can greatly boost model performance with a careful design. Therefore, in this paper, we integrate different dropout techniques into the training of Transformer models. Specifically, we propose an approach named UniDrop to unites three different dropout techniques from fine-grain to coarse-grain, i.e., feature dropout, structure dropout, and data dropout. Theoretically, we demonstrate that these three dropouts play different roles from regularization perspectives. Empirically, we conduct experiments on both neural machine translation and text classification benchmark datasets. Extensive results indicate that Transformer with UniDrop can achieve around 1.5 BLEU improvement on IWSLT14 translation tasks, and better accuracy for the classification even using strong pre-trained RoBERTa as backbone.
IOT: Instance-wise Layer Reordering for Transformer Structures
Mar 05, 2021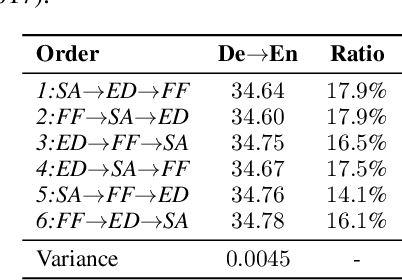
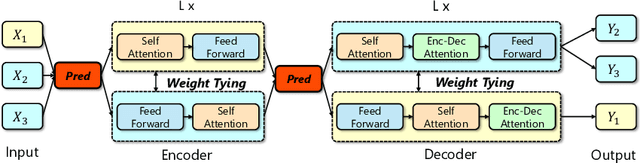

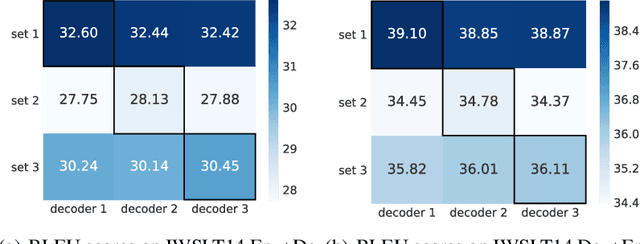
With sequentially stacked self-attention, (optional) encoder-decoder attention, and feed-forward layers, Transformer achieves big success in natural language processing (NLP), and many variants have been proposed. Currently, almost all these models assume that the layer order is fixed and kept the same across data samples. We observe that different data samples actually favor different orders of the layers. Based on this observation, in this work, we break the assumption of the fixed layer order in the Transformer and introduce instance-wise layer reordering into the model structure. Our Instance-wise Ordered Transformer (IOT) can model variant functions by reordered layers, which enables each sample to select the better one to improve the model performance under the constraint of almost the same number of parameters. To achieve this, we introduce a light predictor with negligible parameter and inference cost to decide the most capable and favorable layer order for any input sequence. Experiments on 3 tasks (neural machine translation, abstractive summarization, and code generation) and 9 datasets demonstrate consistent improvements of our method. We further show that our method can also be applied to other architectures beyond Transformer. Our code is released at Github.
COSEA: Convolutional Code Search with Layer-wise Attention
Oct 19, 2020
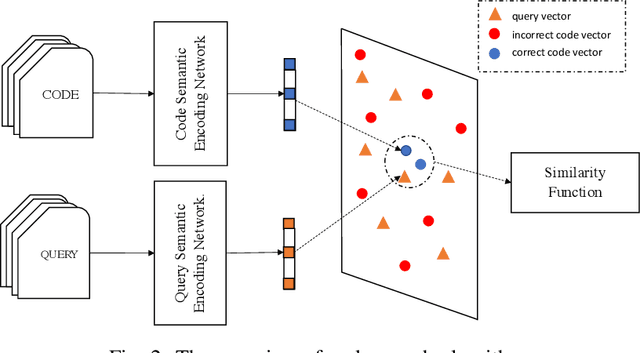
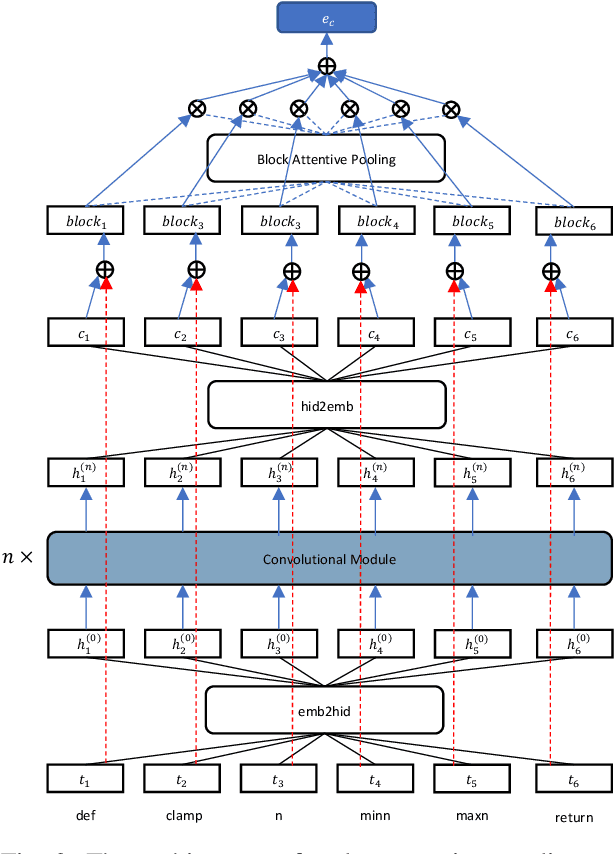
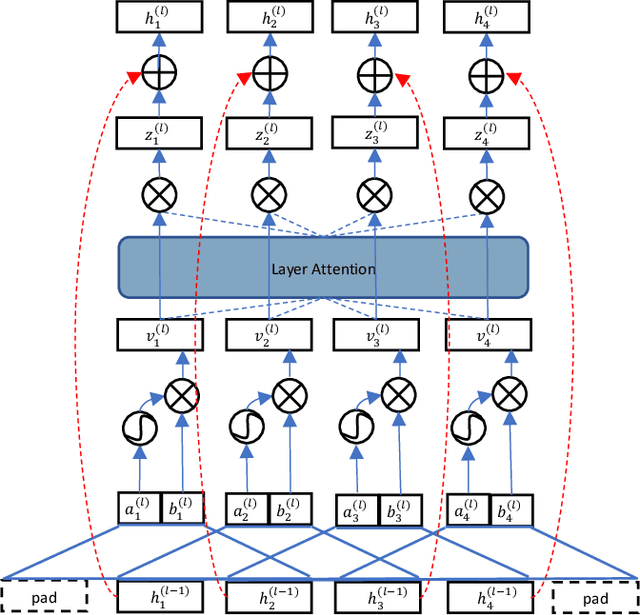
Semantic code search, which aims to retrieve code snippets relevant to a given natural language query, has attracted many research efforts with the purpose of accelerating software development. The huge amount of online publicly available code repositories has prompted the employment of deep learning techniques to build state-of-the-art code search models. Particularly, they leverage deep neural networks to embed codes and queries into a unified semantic vector space and then use the similarity between code's and query's vectors to approximate the semantic correlation between code and the query. However, most existing studies overlook the code's intrinsic structural logic, which indeed contains a wealth of semantic information, and fails to capture intrinsic features of codes. In this paper, we propose a new deep learning architecture, COSEA, which leverages convolutional neural networks with layer-wise attention to capture the valuable code's intrinsic structural logic. To further increase the learning efficiency of COSEA, we propose a variant of contrastive loss for training the code search model, where the ground-truth code should be distinguished from the most similar negative sample. We have implemented a prototype of COSEA. Extensive experiments over existing public datasets of Python and SQL have demonstrated that COSEA can achieve significant improvements over state-of-the-art methods on code search tasks.
Masked Contrastive Representation Learning for Reinforcement Learning
Oct 15, 2020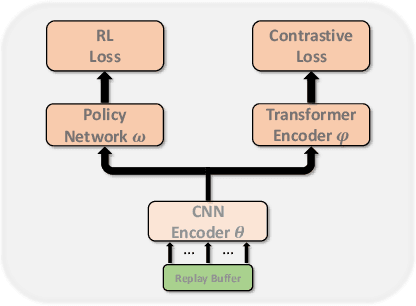
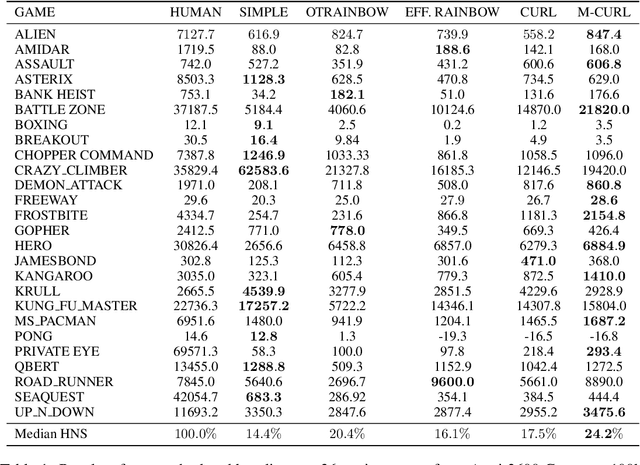
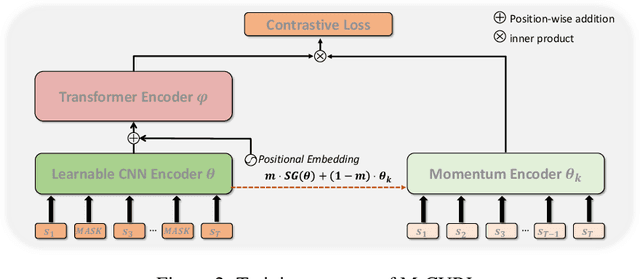
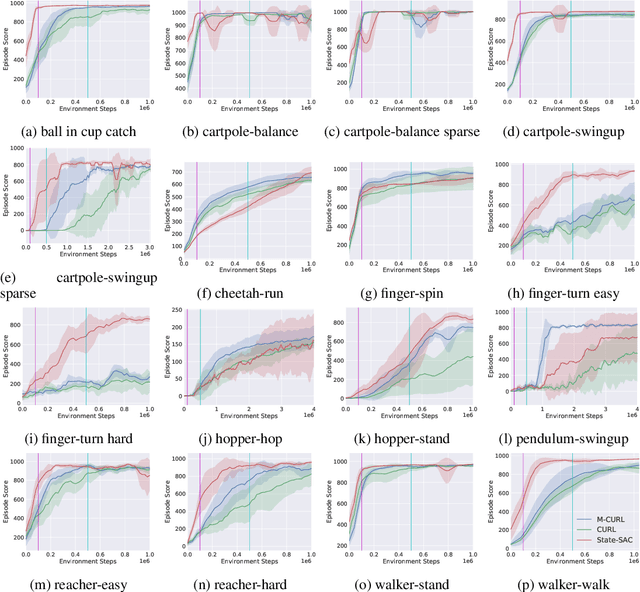
Improving sample efficiency is a key research problem in reinforcement learning (RL), and CURL, which uses contrastive learning to extract high-level features from raw pixels of individual video frames, is an efficient algorithm~\citep{srinivas2020curl}. We observe that consecutive video frames in a game are highly correlated but CURL deals with them independently. To further improve data efficiency, we propose a new algorithm, masked contrastive representation learning for RL, that takes the correlation among consecutive inputs into consideration. In addition to the CNN encoder and the policy network in CURL, our method introduces an auxiliary Transformer module to leverage the correlations among video frames. During training, we randomly mask the features of several frames, and use the CNN encoder and Transformer to reconstruct them based on the context frames. The CNN encoder and Transformer are jointly trained via contrastive learning where the reconstructed features should be similar to the ground-truth ones while dissimilar to others. During inference, the CNN encoder and the policy network are used to take actions, and the Transformer module is discarded. Our method achieves consistent improvements over CURL on $14$ out of $16$ environments from DMControl suite and $21$ out of $26$ environments from Atari 2600 Games. The code is available at https://github.com/teslacool/m-curl.
Learn to Use Future Information in Simultaneous Translation
Jul 10, 2020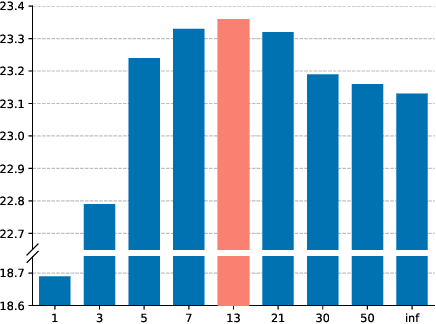
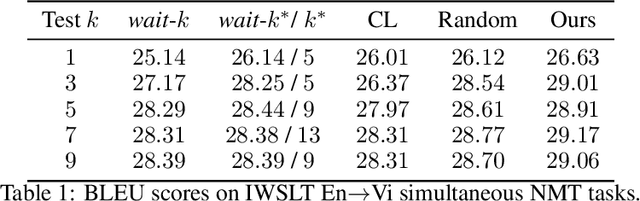
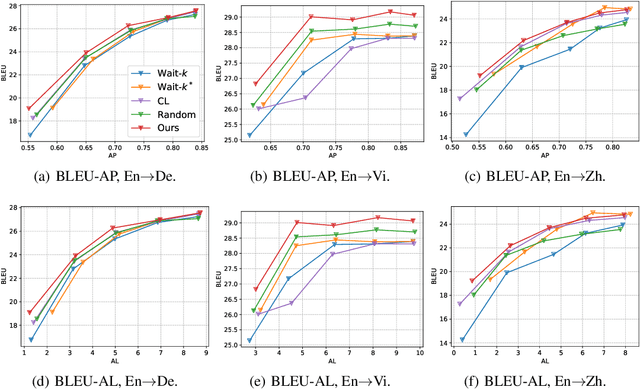

Simultaneous neural machine translation (briefly, NMT) has attracted much attention recently. In contrast to standard NMT, where the NMT system can utilize the full input sentence, simultaneous NMT is formulated as a prefix-to-prefix problem, where the system can only utilize the prefix of the input sentence and more uncertainty is introduced to decoding. Wait-$k$ is a simple yet effective strategy for simultaneous NMT, where the decoder generates the output sequence $k$ words behind the input words. We observed that training simultaneous NMT systems with future information (i.e., trained with a larger $k$) generally outperforms the standard ones (i.e., trained with the given $k$). Based on this observation, we propose a framework that automatically learns how much future information to use in training for simultaneous NMT. We first build a series of tasks where each one is associated with a different $k$, and then learn a model on these tasks guided by a controller. The controller is jointly trained with the translation model through bi-level optimization. We conduct experiments on four datasets to demonstrate the effectiveness of our method.
Learning to Teach with Deep Interactions
Jul 09, 2020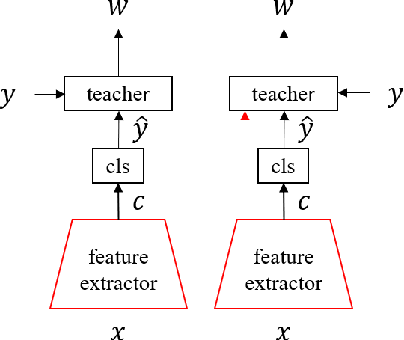
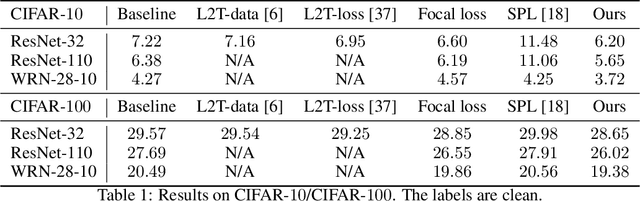

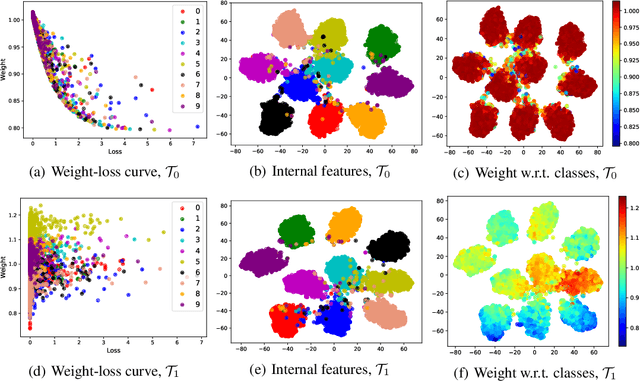
Machine teaching uses a meta/teacher model to guide the training of a student model (which will be used in real tasks) through training data selection, loss function design, etc. Previously, the teacher model only takes shallow/surface information as inputs (e.g., training iteration number, loss and accuracy from training/validation sets) while ignoring the internal states of the student model, which limits the potential of learning to teach. In this work, we propose an improved data teaching algorithm, where the teacher model deeply interacts with the student model by accessing its internal states. The teacher model is jointly trained with the student model using meta gradients propagated from a validation set. We conduct experiments on image classification with clean/noisy labels and empirically demonstrate that our algorithm makes significant improvement over previous data teaching methods.