 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoCloth: Reconstruction and Animation of Cloth-Decoupled Human Avatars from Monocular Videos
Aug 06, 2025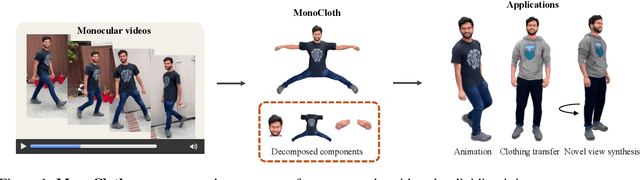
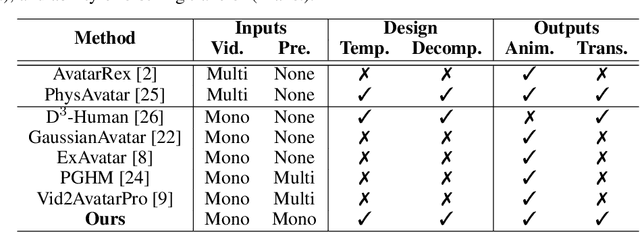
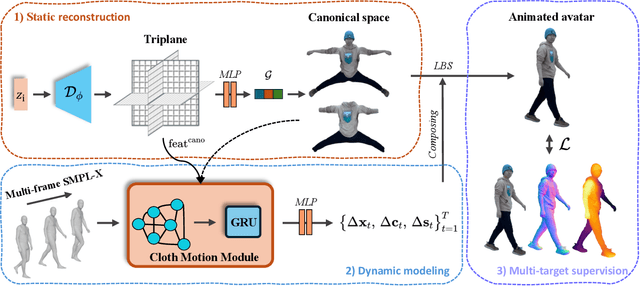
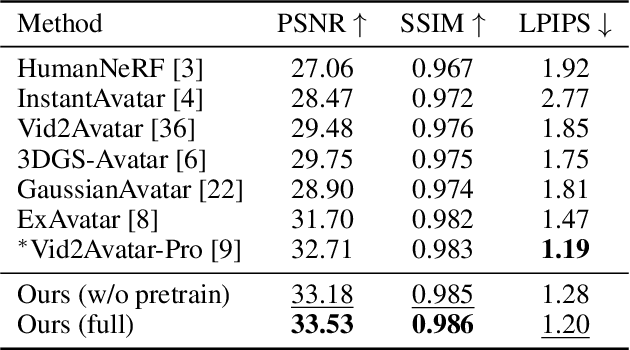
Reconstructing realistic 3D human avatars from monocular videos is a challenging task due to the limited geometric information and complex non-rigid motion involved. We present MonoCloth, a new method for reconstructing and animating clothed human avatars from monocular videos. To overcome the limitations of monocular input, we introduce a part-based decomposition strategy that separates the avatar into body, face, hands, and clothing. This design reflects the varying levels of reconstruction difficulty and deformation complexity across these components. Specifically, we focus on detailed geometry recovery for the face and hands. For clothing, we propose a dedicated cloth simulation module that captures garment deformation using temporal motion cues and geometric constraints. Experimental results demonstrate that MonoCloth improves both visual reconstruction quality and animation realism compared to existing methods. Furthermore, thanks to its part-based design, MonoCloth also supports additional tasks such as clothing transfer, underscoring its versatility and practical utility.
JAM: Keypoint-Guided Joint Prediction after Classification-Aware Marginal Proposal for Multi-Agent Interaction
Jul 23, 2025Predicting the future motion of road participants is a critical task in autonomous driving. In this work, we address the challenge of low-quality generation of low-probability modes in multi-agent joint prediction. To tackle this issue, we propose a two-stage multi-agent interactive prediction framework named \textit{keypoint-guided joint prediction after classification-aware marginal proposal} (JAM). The first stage is modeled as a marginal prediction process, which classifies queries by trajectory type to encourage the model to learn all categories of trajectories, providing comprehensive mode information for the joint prediction module. The second stage is modeled as a joint prediction process, which takes the scene context and the marginal proposals from the first stage as inputs to learn the final joint distribution. We explicitly introduce key waypoints to guide the joint prediction module in better capturing and leveraging the critical information from the initial predicted trajectories. We conduct extensive experiments on the real-world Waymo Open Motion Dataset interactive prediction benchmark. The results show that our approach achieves competitive performance. In particular, in the framework comparison experiments, the proposed JAM outperforms other prediction frameworks and achieves state-of-the-art performance in interactive trajectory prediction. The code is available at https://github.com/LinFunster/JAM to facilitate future research.
Reflections Unlock: Geometry-Aware Reflection Disentanglement in 3D Gaussian Splatting for Photorealistic Scenes Rendering
Jul 08, 2025Accurately rendering scenes with reflective surfaces remains a significant challenge in novel view synthesis, as existing methods like Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) often misinterpret reflections as physical geometry, resulting in degraded reconstructions. Previous methods rely on incomplete and non-generalizable geometric constraints, leading to misalignment between the positions of Gaussian splats and the actual scene geometry. When dealing with real-world scenes containing complex geometry, the accumulation of Gaussians further exacerbates surface artifacts and results in blurred reconstructions. To address these limitations, in this work, we propose Ref-Unlock, a novel geometry-aware reflection modeling framework based on 3D Gaussian Splatting, which explicitly disentangles transmitted and reflected components to better capture complex reflections and enhance geometric consistency in real-world scenes. Our approach employs a dual-branch representation with high-order spherical harmonics to capture high-frequency reflective details, alongside a reflection removal module providing pseudo reflection-free supervision to guide clean decomposition. Additionally, we incorporate pseudo-depth maps and a geometry-aware bilateral smoothness constraint to enhance 3D geometric consistency and stability in decomposition. Extensive experiments demonstrate that Ref-Unlock significantly outperforms classical GS-based reflection methods and achieves competitive results with NeRF-based models, while enabling flexible vision foundation models (VFMs) driven reflection editing. Our method thus offers an efficient and generalizable solution for realistic rendering of reflective scenes. Our code is available at https://ref-unlock.github.io/.
Gaussian2Scene: 3D Scene Representation Learning via Self-supervised Learning with 3D Gaussian Splatting
Jun 11, 2025



Self-supervised learning (SSL) for point cloud pre-training has become a cornerstone for many 3D vision tasks, enabling effective learning from large-scale unannotated data. At the scene level, existing SSL methods often incorporate volume rendering into the pre-training framework, using RGB-D images as reconstruction signals to facilitate cross-modal learning. This strategy promotes alignment between 2D and 3D modalities and enables the model to benefit from rich visual cues in the RGB-D inputs. However, these approaches are limited by their reliance on implicit scene representations and high memory demands. Furthermore, since their reconstruction objectives are applied only in 2D space, they often fail to capture underlying 3D geometric structures. To address these challenges, we propose Gaussian2Scene, a novel scene-level SSL framework that leverages the efficiency and explicit nature of 3D Gaussian Splatting (3DGS) for pre-training. The use of 3DGS not only alleviates the computational burden associated with volume rendering but also supports direct 3D scene reconstruction, thereby enhancing the geometric understanding of the backbone network. Our approach follows a progressive two-stage training strategy. In the first stage, a dual-branch masked autoencoder learns both 2D and 3D scene representations. In the second stage, we initialize training with reconstructed point clouds and further supervise learning using the geometric locations of Gaussian primitives and rendered RGB images. This process reinforces both geometric and cross-modal learning. We demonstrate the effectiveness of Gaussian2Scene across several downstream 3D object detection tasks, showing consistent improvements over existing pre-training methods.
A Divide-and-Conquer Approach for Global Orientation of Non-Watertight Scene-Level Point Clouds Using 0-1 Integer Optimization
May 29, 2025Orienting point clouds is a fundamental problem in computer graphics and 3D vision, with applications in reconstruction, segmentation, and analysis. While significant progress has been made, existing approaches mainly focus on watertight, object-level 3D models. The orientation of large-scale, non-watertight 3D scenes remains an underexplored challenge. To address this gap, we propose DACPO (Divide-And-Conquer Point Orientation), a novel framework that leverages a divide-and-conquer strategy for scalable and robust point cloud orientation. Rather than attempting to orient an unbounded scene at once, DACPO segments the input point cloud into smaller, manageable blocks, processes each block independently, and integrates the results through a global optimization stage. For each block, we introduce a two-step process: estimating initial normal orientations by a randomized greedy method and refining them by an adapted iterative Poisson surface reconstruction. To achieve consistency across blocks, we model inter-block relationships using an an undirected graph, where nodes represent blocks and edges connect spatially adjacent blocks. To reliably evaluate orientation consistency between adjacent blocks, we introduce the concept of the visible connected region, which defines the region over which visibility-based assessments are performed. The global integration is then formulated as a 0-1 integer-constrained optimization problem, with block flip states as binary variables. Despite the combinatorial nature of the problem, DACPO remains scalable by limiting the number of blocks (typically a few hundred for 3D scenes) involved in the optimization. Experiments on benchmark datasets demonstrate DACPO's strong performance, particularly in challenging large-scale, non-watertight scenarios where existing methods often fail. The source code is available at https://github.com/zd-lee/DACPO.
SplatCo: Structure-View Collaborative Gaussian Splatting for Detail-Preserving Rendering of Large-Scale Unbounded Scenes
May 23, 2025We present SplatCo, a structure-view collaborative Gaussian splatting framework for high-fidelity rendering of complex outdoor environments. SplatCo builds upon two novel components: (1) a cross-structure collaboration module that combines global tri-plane representations, which capture coarse scene layouts, with local context grid features that represent fine surface details. This fusion is achieved through a novel hierarchical compensation strategy, ensuring both global consistency and local detail preservation; and (2) a cross-view assisted training strategy that enhances multi-view consistency by synchronizing gradient updates across viewpoints, applying visibility-aware densification, and pruning overfitted or inaccurate Gaussians based on structural consistency. Through joint optimization of structural representation and multi-view coherence, SplatCo effectively reconstructs fine-grained geometric structures and complex textures in large-scale scenes. Comprehensive evaluations on 13 diverse large-scale scenes, including Mill19, MatrixCity, Tanks & Temples, WHU, and custom aerial captures, demonstrate that SplatCo consistently achieves higher reconstruction quality than state-of-the-art methods, with PSNR improvements of 1-2 dB and SSIM gains of 0.1 to 0.2. These results establish a new benchmark for high-fidelity rendering of large-scale unbounded scenes. Code and additional information are available at https://github.com/SCUT-BIP-Lab/SplatCo.
Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures
May 14, 2025



The rapid scaling of large language models (LLMs) has unveiled critical limitations in current hardware architectures, including constraints in memory capacity, computational efficiency, and interconnection bandwidth. DeepSeek-V3, trained on 2,048 NVIDIA H800 GPUs, demonstrates how hardware-aware model co-design can effectively address these challenges, enabling cost-efficient training and inference at scale. This paper presents an in-depth analysis of the DeepSeek-V3/R1 model architecture and its AI infrastructure, highlighting key innovations such as Multi-head Latent Attention (MLA) for enhanced memory efficiency, Mixture of Experts (MoE) architectures for optimized computation-communication trade-offs, FP8 mixed-precision training to unlock the full potential of hardware capabilities, and a Multi-Plane Network Topology to minimize cluster-level network overhead. Building on the hardware bottlenecks encountered during DeepSeek-V3's development, we engage in a broader discussion with academic and industry peers on potential future hardware directions, including precise low-precision computation units, scale-up and scale-out convergence, and innovations in low-latency communication fabrics. These insights underscore the critical role of hardware and model co-design in meeting the escalating demands of AI workloads, offering a practical blueprint for innovation in next-generation AI systems.
FlexPara: Flexible Neural Surface Parameterization
Apr 27, 2025Surface parameterization is a fundamental geometry processing task, laying the foundations for the visual presentation of 3D assets and numerous downstream shape analysis scenarios. Conventional parameterization approaches demand high-quality mesh triangulation and are restricted to certain simple topologies unless additional surface cutting and decomposition are provided. In practice, the optimal configurations (e.g., type of parameterization domains, distribution of cutting seams, number of mapping charts) may vary drastically with different surface structures and task characteristics, thus requiring more flexible and controllable processing pipelines. To this end, this paper introduces FlexPara, an unsupervised neural optimization framework to achieve both global and multi-chart surface parameterizations by establishing point-wise mappings between 3D surface points and adaptively-deformed 2D UV coordinates. We ingeniously design and combine a series of geometrically-interpretable sub-networks, with specific functionalities of cutting, deforming, unwrapping, and wrapping, to construct a bi-directional cycle mapping framework for global parameterization without the need for manually specified cutting seams. Furthermore, we construct a multi-chart parameterization framework with adaptively-learned chart assignment. Extensive experiments demonstrate the universality, superiority, and inspiring potential of our neural surface parameterization paradigm. The code will be publicly available at https://github.com/AidenZhao/FlexPara
MGSR: 2D/3D Mutual-boosted Gaussian Splatting for High-fidelity Surface Reconstruction under Various Light Conditions
Mar 07, 2025



Novel view synthesis (NVS) and surface reconstruction (SR) are essential tasks in 3D Gaussian Splatting (3D-GS). Despite recent progress, these tasks are often addressed independently, with GS-based rendering methods struggling under diverse light conditions and failing to produce accurate surfaces, while GS-based reconstruction methods frequently compromise rendering quality. This raises a central question: must rendering and reconstruction always involve a trade-off? To address this, we propose MGSR, a 2D/3D Mutual-boosted Gaussian splatting for Surface Reconstruction that enhances both rendering quality and 3D reconstruction accuracy. MGSR introduces two branches--one based on 2D-GS and the other on 3D-GS. The 2D-GS branch excels in surface reconstruction, providing precise geometry information to the 3D-GS branch. Leveraging this geometry, the 3D-GS branch employs a geometry-guided illumination decomposition module that captures reflected and transmitted components, enabling realistic rendering under varied light conditions. Using the transmitted component as supervision, the 2D-GS branch also achieves high-fidelity surface reconstruction. Throughout the optimization process, the 2D-GS and 3D-GS branches undergo alternating optimization, providing mutual supervision. Prior to this, each branch completes an independent warm-up phase, with an early stopping strategy implemented to reduce computational costs. We evaluate MGSR on a diverse set of synthetic and real-world datasets, at both object and scene levels, demonstrating strong performance in rendering and surface reconstruction.
Inter3D: A Benchmark and Strong Baseline for Human-Interactive 3D Object Reconstruction
Feb 19, 2025



Recent advancements in implicit 3D reconstruction methods, e.g., neural rendering fields and Gaussian splatting, have primarily focused on novel view synthesis of static or dynamic objects with continuous motion states. However, these approaches struggle to efficiently model a human-interactive object with n movable parts, requiring 2^n separate models to represent all discrete states. To overcome this limitation, we propose Inter3D, a new benchmark and approach for novel state synthesis of human-interactive objects. We introduce a self-collected dataset featuring commonly encountered interactive objects and a new evaluation pipeline, where only individual part states are observed during training, while part combination states remain unseen. We also propose a strong baseline approach that leverages Space Discrepancy Tensors to efficiently modelling all states of an object. To alleviate the impractical constraints on camera trajectories across training states, we propose a Mutual State Regularization mechanism to enhance the spatial density consistency of movable parts. In addition, we explore two occupancy grid sampling strategies to facilitate training efficiency. We conduct extensive experiments on the proposed benchmark, showcasing the challenges of the task and the superiority of our approach.