 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAir Quality Prediction with A Meteorology-Guided Modality-Decoupled Spatio-Temporal Network
Apr 14, 2025Air quality prediction plays a crucial role in public health and environmental protection. Accurate air quality prediction is a complex multivariate spatiotemporal problem, that involves interactions across temporal patterns, pollutant correlations, spatial station dependencies, and particularly meteorological influences that govern pollutant dispersion and chemical transformations. Existing works underestimate the critical role of atmospheric conditions in air quality prediction and neglect comprehensive meteorological data utilization, thereby impairing the modeling of dynamic interdependencies between air quality and meteorological data. To overcome this, we propose MDSTNet, an encoder-decoder framework that explicitly models air quality observations and atmospheric conditions as distinct modalities, integrating multi-pressure-level meteorological data and weather forecasts to capture atmosphere-pollution dependencies for prediction. Meantime, we construct ChinaAirNet, the first nationwide dataset combining air quality records with multi-pressure-level meteorological observations. Experimental results on ChinaAirNet demonstrate MDSTNet's superiority, substantially reducing 48-hour prediction errors by 17.54\% compared to the state-of-the-art model. The source code and dataset will be available on github.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
SAM2MOT: A Novel Paradigm of Multi-Object Tracking by Segmentation
Apr 06, 2025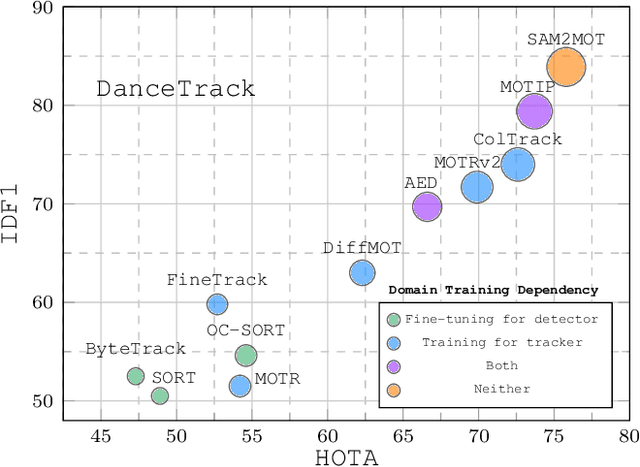
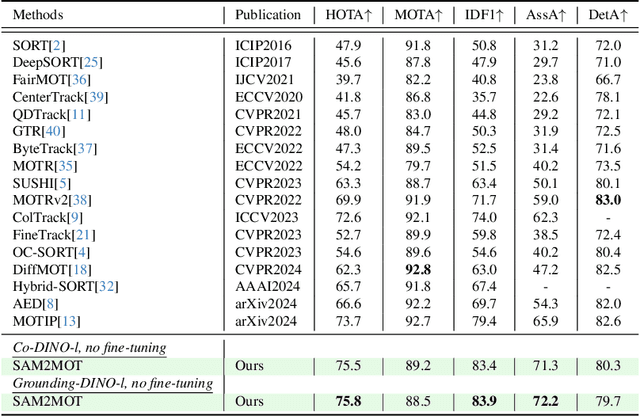
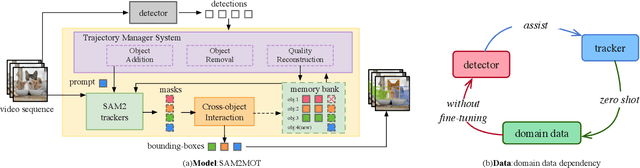
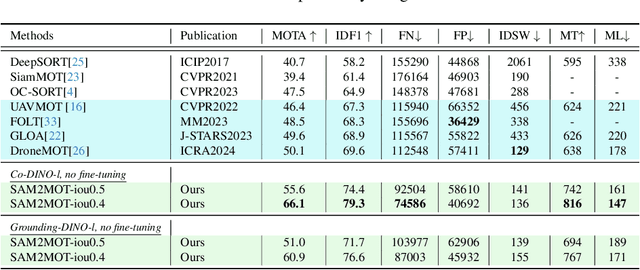
Segment Anything 2 (SAM2) enables robust single-object tracking using segmentation. To extend this to multi-object tracking (MOT), we propose SAM2MOT, introducing a novel Tracking by Segmentation paradigm. Unlike Tracking by Detection or Tracking by Query, SAM2MOT directly generates tracking boxes from segmentation masks, reducing reliance on detection accuracy. SAM2MOT has two key advantages: zero-shot generalization, allowing it to work across datasets without fine-tuning, and strong object association, inherited from SAM2. To further improve performance, we integrate a trajectory manager system for precise object addition and removal, and a cross-object interaction module to handle occlusions. Experiments on DanceTrack, UAVDT, and BDD100K show state-of-the-art results. Notably, SAM2MOT outperforms existing methods on DanceTrack by +2.1 HOTA and +4.5 IDF1, highlighting its effectiveness in MOT.
PAVE: Patching and Adapting Video Large Language Models
Mar 25, 2025Pre-trained video large language models (Video LLMs) exhibit remarkable reasoning capabilities, yet adapting these models to new tasks involving additional modalities or data types (e.g., audio or 3D information) remains challenging. In this paper, we present PAVE, a flexible framework for adapting pre-trained Video LLMs to downstream tasks with side-channel signals, such as audio, 3D cues, or multi-view videos. PAVE introduces lightweight adapters, referred to as "patches," which add a small number of parameters and operations to a base model without modifying its architecture or pre-trained weights. In doing so, PAVE can effectively adapt the pre-trained base model to support diverse downstream tasks, including audio-visual question answering, 3D reasoning, multi-view video recognition, and high frame rate video understanding. Across these tasks, PAVE significantly enhances the performance of the base model, surpassing state-of-the-art task-specific models while incurring a minor cost of ~0.1% additional FLOPs and parameters. Further, PAVE supports multi-task learning and generalizes well across different Video LLMs. Our code is available at https://github.com/dragonlzm/PAVE.
Learning to Inference Adaptively for Multimodal Large Language Models
Mar 13, 2025
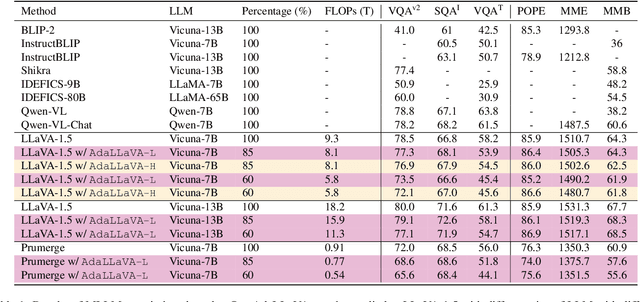
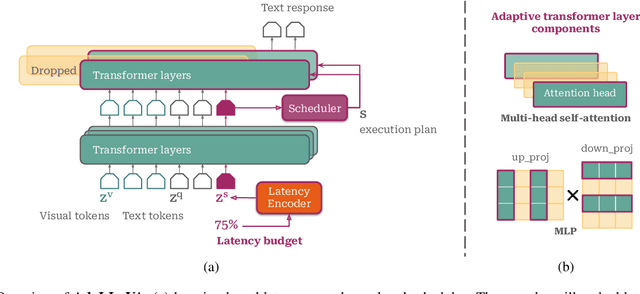
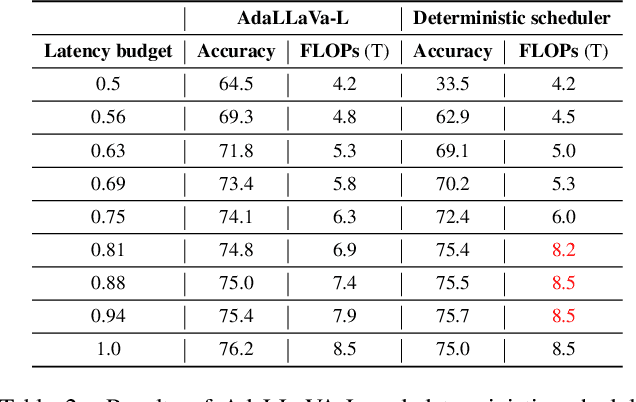
Multimodal Large Language Models (MLLMs) have shown impressive capabilities in reasoning, yet come with substantial computational cost, limiting their deployment in resource-constrained settings. Despite recent efforts on improving the efficiency of MLLMs, prior solutions fall short in responding to varying runtime conditions, in particular changing resource availability (e.g., contention due to the execution of other programs on the device). To bridge this gap, we introduce AdaLLaVA, an adaptive inference framework that learns to dynamically reconfigure operations in an MLLM during inference, accounting for the input data and a latency budget. We conduct extensive experiments across benchmarks involving question-answering, reasoning, and hallucination. Our results show that AdaLLaVA effectively adheres to input latency budget, achieving varying accuracy and latency tradeoffs at runtime. Further, we demonstrate that AdaLLaVA adapts to both input latency and content, can be integrated with token selection for enhanced efficiency, and generalizes across MLLMs.Our project webpage with code release is at https://zhuoyan-xu.github.io/ada-llava/.
Deep-Unrolling Multidimensional Harmonic Retrieval Algorithms on Neuromorphic Hardware
Dec 05, 2024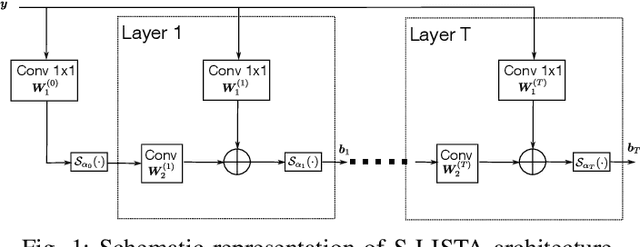
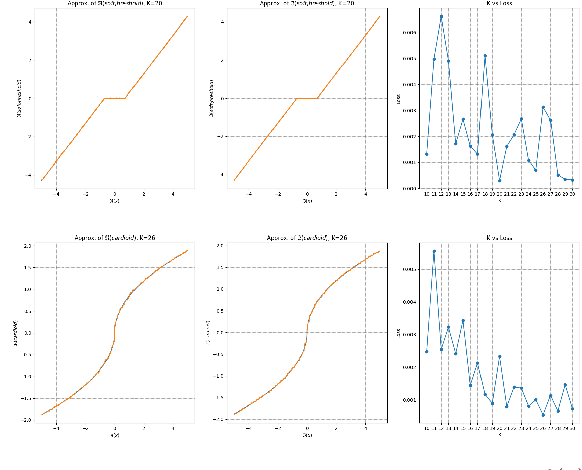
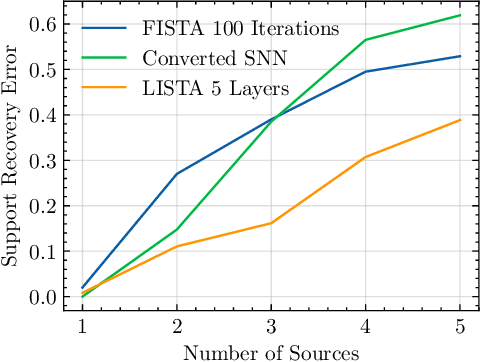
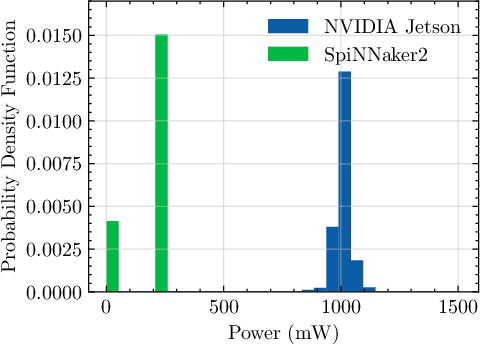
This paper explores the potential of conversion-based neuromorphic algorithms for highly accurate and energy-efficient single-snapshot multidimensional harmonic retrieval (MHR). By casting the MHR problem as a sparse recovery problem, we devise the currently proposed, deep-unrolling-based Structured Learned Iterative Shrinkage and Thresholding (S-LISTA) algorithm to solve it efficiently using complex-valued convolutional neural networks with complex-valued activations, which are trained using a supervised regression objective. Afterward, a novel method for converting the complex-valued convolutional layers and activations into spiking neural networks (SNNs) is developed. At the heart of this method lies the recently proposed Few Spikes (FS) conversion, which is extended by modifying the neuron model's parameters and internal dynamics to account for the inherent coupling between real and imaginary parts in complex-valued computations. Finally, the converted SNNs are mapped onto the SpiNNaker2 neuromorphic board, and a comparison in terms of estimation accuracy and power efficiency between the original CNNs deployed on an NVIDIA Jetson Xavier and the SNNs is being conducted. The measurement results show that the converted SNNs achieve almost five-fold power efficiency at moderate performance loss compared to the original CNNs.
AIM: Adaptive Inference of Multi-Modal LLMs via Token Merging and Pruning
Dec 04, 2024Large language models (LLMs) have enabled the creation of multi-modal LLMs that exhibit strong comprehension of visual data such as images and videos. However, these models usually rely on extensive visual tokens from visual encoders, leading to high computational demands, which limits their applicability in resource-constrained environments and for long-context tasks. In this work, we propose a training-free adaptive inference method for multi-modal LLMs that can accommodate a broad range of efficiency requirements with a minimum performance drop. Our method consists of a) iterative token merging based on embedding similarity before LLMs, and b) progressive token pruning within LLM layers based on multi-modal importance. With a minimalist design, our method can be applied to both video and image LLMs. Extensive experiments on diverse video and image benchmarks demonstrate that, our method substantially reduces computation load (e.g., a $\textbf{7-fold}$ reduction in FLOPs) while preserving the performance of video and image LLMs. Further, under a similar computational cost, our method outperforms the state-of-the-art methods in long video understanding (e.g., $\textbf{+4.6}$ on MLVU). Additionally, our in-depth analysis provides insights into token redundancy and LLM layer behaviors, offering guidance for future research in designing efficient multi-modal LLMs. Our code will be available at https://github.com/LaVi-Lab/AIM.
MCCoder: Streamlining Motion Control with LLM-Assisted Code Generation and Rigorous Verification
Oct 19, 2024



Large Language Models (LLMs) have shown considerable promise in code generation. However, the automation sector, especially in motion control, continues to rely heavily on manual programming due to the complexity of tasks and critical safety considerations. In this domain, incorrect code execution can pose risks to both machinery and personnel, necessitating specialized expertise. To address these challenges, we introduce MCCoder, an LLM-powered system designed to generate code that addresses complex motion control tasks, with integrated soft-motion data verification. MCCoder enhances code generation through multitask decomposition, hybrid retrieval-augmented generation (RAG), and self-correction with a private motion library. Moreover, it supports data verification by logging detailed trajectory data and providing simulations and plots, allowing users to assess the accuracy of the generated code and bolstering confidence in LLM-based programming. To ensure robust validation, we propose MCEVAL, an evaluation dataset with metrics tailored to motion control tasks of varying difficulties. Experiments indicate that MCCoder improves performance by 11.61% overall and by 66.12% on complex tasks in MCEVAL dataset compared with base models with naive RAG. This system and dataset aim to facilitate the application of code generation in automation settings with strict safety requirements. MCCoder is publicly available at https://github.com/MCCodeAI/MCCoder.
Boosting Open-Domain Continual Learning via Leveraging Intra-domain Category-aware Prototype
Aug 19, 2024Despite recent progress in enhancing the efficacy of Open-Domain Continual Learning (ODCL) in Vision-Language Models (VLM), failing to (1) correctly identify the Task-ID of a test image and (2) use only the category set corresponding to the Task-ID, while preserving the knowledge related to each domain, cannot address the two primary challenges of ODCL: forgetting old knowledge and maintaining zero-shot capabilities, as well as the confusions caused by category-relatedness between domains. In this paper, we propose a simple yet effective solution: leveraging intra-domain category-aware prototypes for ODCL in CLIP (DPeCLIP), where the prototype is the key to bridging the above two processes. Concretely, we propose a training-free Task-ID discriminator method, by utilizing prototypes as classifiers for identifying Task-IDs. Furthermore, to maintain the knowledge corresponding to each domain, we incorporate intra-domain category-aware prototypes as domain prior prompts into the training process. Extensive experiments conducted on 11 different datasets demonstrate the effectiveness of our approach, achieving 2.37% and 1.14% average improvement in class-incremental and task-incremental settings, respectively.
RICA2: Rubric-Informed, Calibrated Assessment of Actions
Aug 06, 2024



The ability to quantify how well an action is carried out, also known as action quality assessment (AQA), has attracted recent interest in the vision community. Unfortunately, prior methods often ignore the score rubric used by human experts and fall short of quantifying the uncertainty of the model prediction. To bridge the gap, we present RICA^2 - a deep probabilistic model that integrates score rubric and accounts for prediction uncertainty for AQA. Central to our method lies in stochastic embeddings of action steps, defined on a graph structure that encodes the score rubric. The embeddings spread probabilistic density in the latent space and allow our method to represent model uncertainty. The graph encodes the scoring criteria, based on which the quality scores can be decoded. We demonstrate that our method establishes new state of the art on public benchmarks, including FineDiving, MTL-AQA, and JIGSAWS, with superior performance in score prediction and uncertainty calibration. Our code is available at https://abrarmajeedi.github.io/rica2_aqa/