 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLETS Forecast: Learning Embedology for Time Series Forecasting
Jun 06, 2025



Real-world time series are often governed by complex nonlinear dynamics. Understanding these underlying dynamics is crucial for precise future prediction. While deep learning has achieved major success in time series forecasting, many existing approaches do not explicitly model the dynamics. To bridge this gap, we introduce DeepEDM, a framework that integrates nonlinear dynamical systems modeling with deep neural networks. Inspired by empirical dynamic modeling (EDM) and rooted in Takens' theorem, DeepEDM presents a novel deep model that learns a latent space from time-delayed embeddings, and employs kernel regression to approximate the underlying dynamics, while leveraging efficient implementation of softmax attention and allowing for accurate prediction of future time steps. To evaluate our method, we conduct comprehensive experiments on synthetic data of nonlinear dynamical systems as well as real-world time series across domains. Our results show that DeepEDM is robust to input noise, and outperforms state-of-the-art methods in forecasting accuracy. Our code is available at: https://abrarmajeedi.github.io/deep_edm.
R&B: Domain Regrouping and Data Mixture Balancing for Efficient Foundation Model Training
May 01, 2025



Data mixing strategies have successfully reduced the costs involved in training language models. While promising, such methods suffer from two flaws. First, they rely on predetermined data domains (e.g., data sources, task types), which may fail to capture critical semantic nuances, leaving performance on the table. Second, these methods scale with the number of domains in a computationally prohibitive way. We address these challenges via R&B, a framework that re-partitions training data based on semantic similarity (Regroup) to create finer-grained domains, and efficiently optimizes the data composition (Balance) by leveraging a Gram matrix induced by domain gradients obtained throughout training. Unlike prior works, it removes the need for additional compute to obtain evaluation information such as losses or gradients. We analyze this technique under standard regularity conditions and provide theoretical insights that justify R&B's effectiveness compared to non-adaptive mixing approaches. Empirically, we demonstrate the effectiveness of R&B on five diverse datasets ranging from natural language to reasoning and multimodal tasks. With as little as 0.01% additional compute overhead, R&B matches or exceeds the performance of state-of-the-art data mixing strategies.
Tabby: Tabular Data Synthesis with Language Models
Mar 04, 2025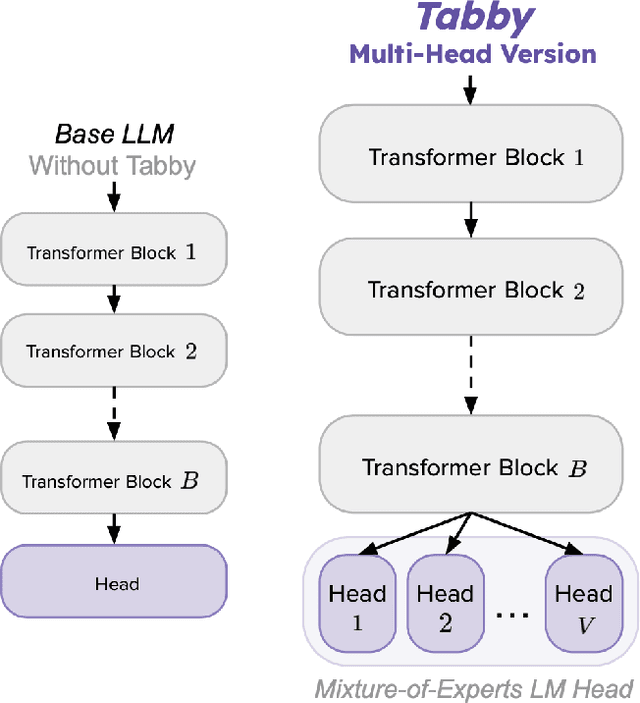
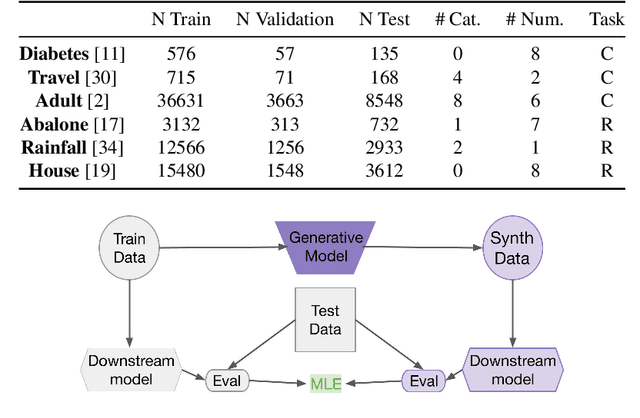
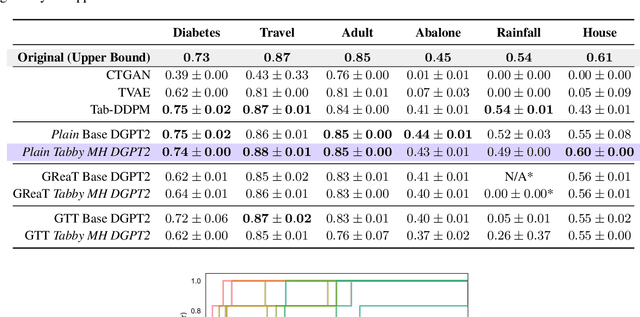
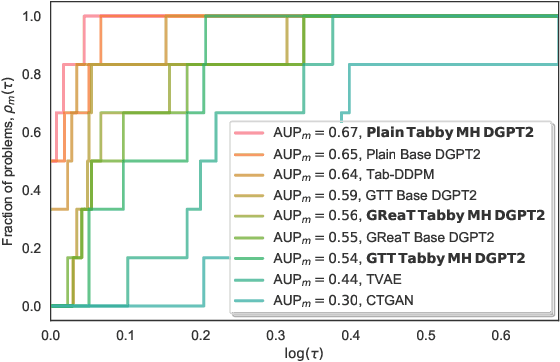
While advances in large language models (LLMs) have greatly improved the quality of synthetic text data in recent years, synthesizing tabular data has received relatively less attention. We address this disparity with Tabby, a simple but powerful post-training modification to the standard Transformer language model architecture, enabling its use for tabular dataset synthesis. Tabby enables the representation of differences across columns using Gated Mixture-of-Experts, with column-specific sets of parameters. Empirically, Tabby results in data quality near or equal to that of real data. By pairing our novel LLM table training technique, Plain, with Tabby, we observe up to a 44% improvement in quality over previous methods. We also show that Tabby extends beyond tables to more general structured data, reaching parity with real data on a nested JSON dataset as well.
RICA2: Rubric-Informed, Calibrated Assessment of Actions
Aug 06, 2024



The ability to quantify how well an action is carried out, also known as action quality assessment (AQA), has attracted recent interest in the vision community. Unfortunately, prior methods often ignore the score rubric used by human experts and fall short of quantifying the uncertainty of the model prediction. To bridge the gap, we present RICA^2 - a deep probabilistic model that integrates score rubric and accounts for prediction uncertainty for AQA. Central to our method lies in stochastic embeddings of action steps, defined on a graph structure that encodes the score rubric. The embeddings spread probabilistic density in the latent space and allow our method to represent model uncertainty. The graph encodes the scoring criteria, based on which the quality scores can be decoded. We demonstrate that our method establishes new state of the art on public benchmarks, including FineDiving, MTL-AQA, and JIGSAWS, with superior performance in score prediction and uncertainty calibration. Our code is available at https://abrarmajeedi.github.io/rica2_aqa/
Pretrained Hybrids with MAD Skills
Jun 02, 2024



While Transformers underpin modern large language models (LMs), there is a growing list of alternative architectures with new capabilities, promises, and tradeoffs. This makes choosing the right LM architecture challenging. Recently-proposed $\textit{hybrid architectures}$ seek a best-of-all-worlds approach that reaps the benefits of all architectures. Hybrid design is difficult for two reasons: it requires manual expert-driven search, and new hybrids must be trained from scratch. We propose $\textbf{Manticore}$, a framework that addresses these challenges. Manticore $\textit{automates the design of hybrid architectures}$ while reusing pretrained models to create $\textit{pretrained}$ hybrids. Our approach augments ideas from differentiable Neural Architecture Search (NAS) by incorporating simple projectors that translate features between pretrained blocks from different architectures. We then fine-tune hybrids that combine pretrained models from different architecture families -- such as the GPT series and Mamba -- end-to-end. With Manticore, we enable LM selection without training multiple models, the construction of pretrained hybrids from existing pretrained models, and the ability to $\textit{program}$ pretrained hybrids to have certain capabilities. Manticore hybrids outperform existing manually-designed hybrids, achieve strong performance on Long Range Arena (LRA) tasks, and can improve on pretrained transformers and state space models.