 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReGLA: Efficient Receptive-Field Modeling with Gated Linear Attention Network
Feb 05, 2026Balancing accuracy and latency on high-resolution images is a critical challenge for lightweight models, particularly for Transformer-based architectures that often suffer from excessive latency. To address this issue, we introduce \textbf{ReGLA}, a series of lightweight hybrid networks, which integrates efficient convolutions for local feature extraction with ReLU-based gated linear attention for global modeling. The design incorporates three key innovations: the Efficient Large Receptive Field (ELRF) module for enhancing convolutional efficiency while preserving a large receptive field; the ReLU Gated Modulated Attention (RGMA) module for maintaining linear complexity while enhancing local feature representation; and a multi-teacher distillation strategy to boost performance on downstream tasks. Extensive experiments validate the superiority of ReGLA; particularly the ReGLA-M achieves \textbf{80.85\%} Top-1 accuracy on ImageNet-1K at $224px$, with only \textbf{4.98 ms} latency at $512px$. Furthermore, ReGLA outperforms similarly scaled iFormer models in downstream tasks, achieving gains of \textbf{3.1\%} AP on COCO object detection and \textbf{3.6\%} mIoU on ADE20K semantic segmentation, establishing it as a state-of-the-art solution for high-resolution visual applications.
SAM2MOT: A Novel Paradigm of Multi-Object Tracking by Segmentation
Apr 06, 2025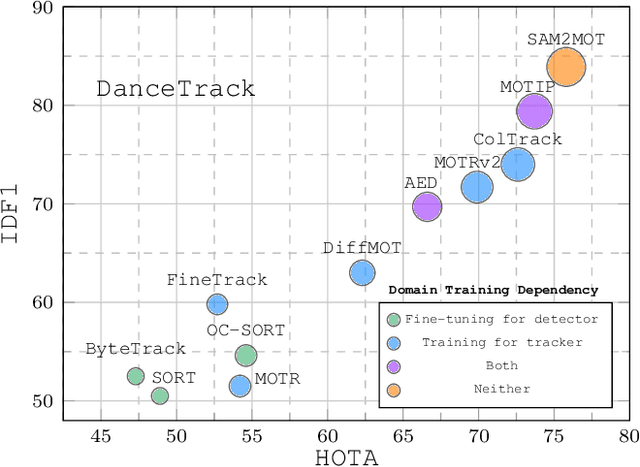
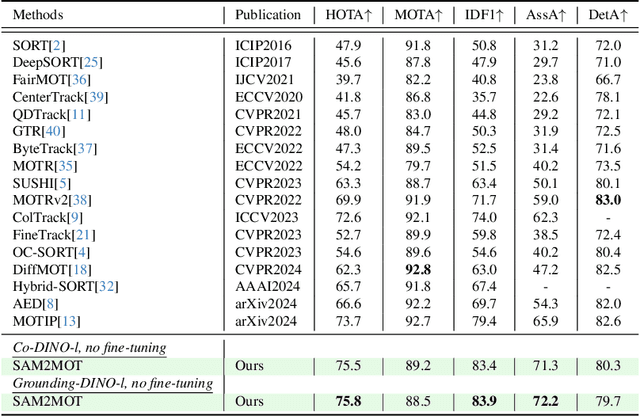
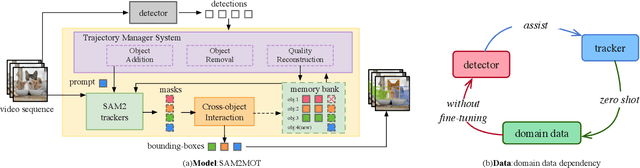
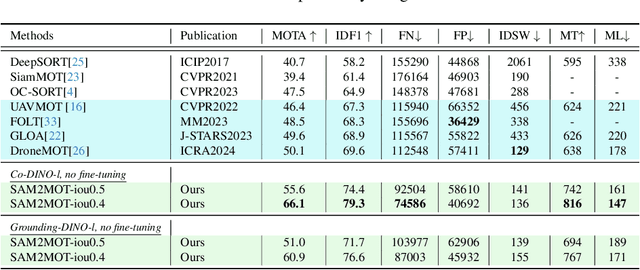
Segment Anything 2 (SAM2) enables robust single-object tracking using segmentation. To extend this to multi-object tracking (MOT), we propose SAM2MOT, introducing a novel Tracking by Segmentation paradigm. Unlike Tracking by Detection or Tracking by Query, SAM2MOT directly generates tracking boxes from segmentation masks, reducing reliance on detection accuracy. SAM2MOT has two key advantages: zero-shot generalization, allowing it to work across datasets without fine-tuning, and strong object association, inherited from SAM2. To further improve performance, we integrate a trajectory manager system for precise object addition and removal, and a cross-object interaction module to handle occlusions. Experiments on DanceTrack, UAVDT, and BDD100K show state-of-the-art results. Notably, SAM2MOT outperforms existing methods on DanceTrack by +2.1 HOTA and +4.5 IDF1, highlighting its effectiveness in MOT.
Graph-based Learning with Unbalanced Clusters
May 08, 2012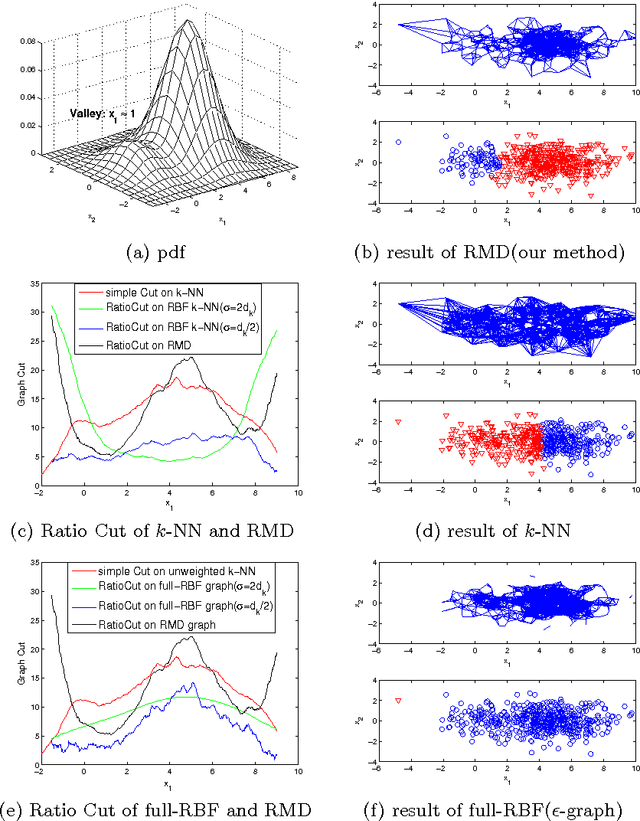
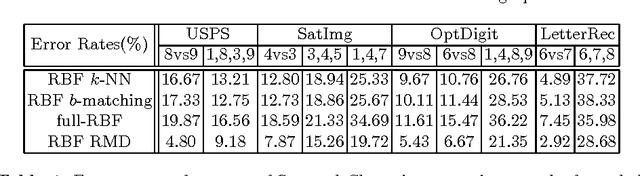
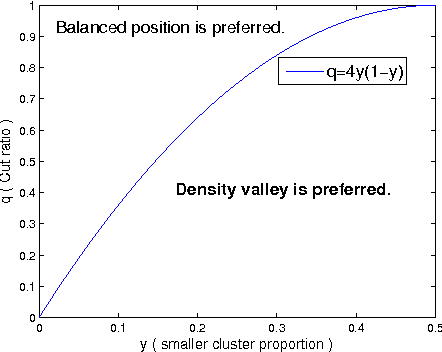
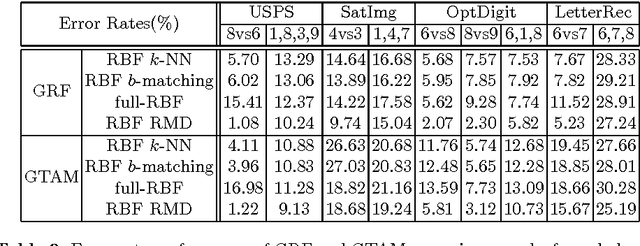
Graph construction is a crucial step in spectral clustering (SC) and graph-based semi-supervised learning (SSL). Spectral methods applied on standard graphs such as full-RBF, $\epsilon$-graphs and $k$-NN graphs can lead to poor performance in the presence of proximal and unbalanced data. This is because spectral methods based on minimizing RatioCut or normalized cut on these graphs tend to put more importance on balancing cluster sizes over reducing cut values. We propose a novel graph construction technique and show that the RatioCut solution on this new graph is able to handle proximal and unbalanced data. Our method is based on adaptively modulating the neighborhood degrees in a $k$-NN graph, which tends to sparsify neighborhoods in low density regions. Our method adapts to data with varying levels of unbalancedness and can be naturally used for small cluster detection. We justify our ideas through limit cut analysis. Unsupervised and semi-supervised experiments on synthetic and real data sets demonstrate the superiority of our method.
Graph Construction for Learning with Unbalanced Data
Dec 11, 2011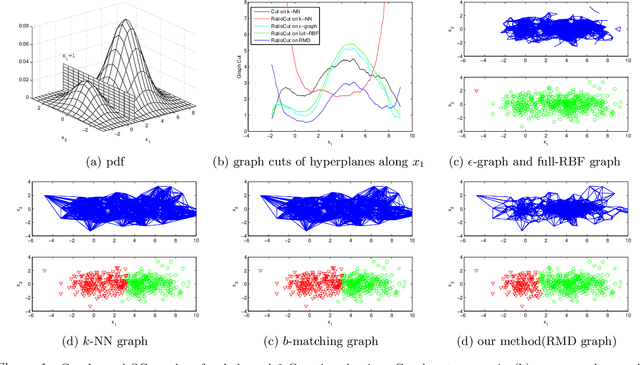
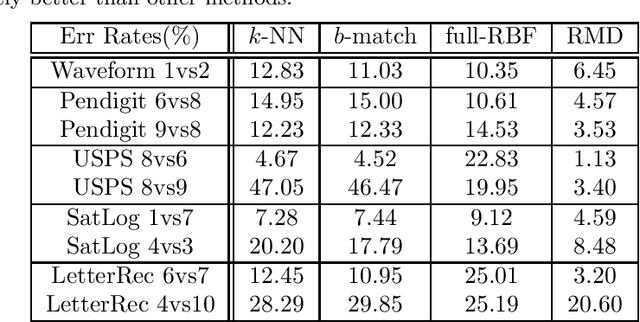
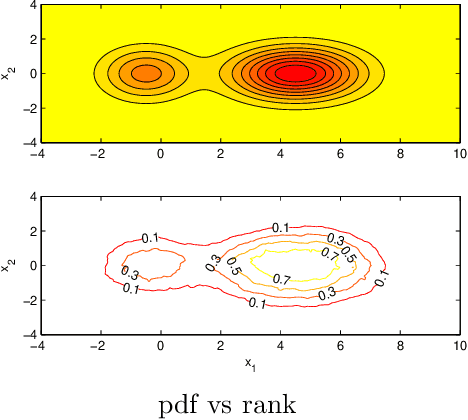
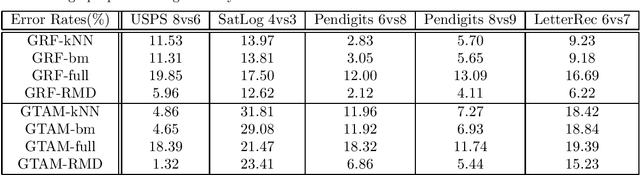
Unbalanced data arises in many learning tasks such as clustering of multi-class data, hierarchical divisive clustering and semisupervised learning. Graph-based approaches are popular tools for these problems. Graph construction is an important aspect of graph-based learning. We show that graph-based algorithms can fail for unbalanced data for many popular graphs such as k-NN, \epsilon-neighborhood and full-RBF graphs. We propose a novel graph construction technique that encodes global statistical information into node degrees through a ranking scheme. The rank of a data sample is an estimate of its p-value and is proportional to the total number of data samples with smaller density. This ranking scheme serves as a surrogate for density; can be reliably estimated; and indicates whether a data sample is close to valleys/modes. This rank-modulated degree(RMD) scheme is able to significantly sparsify the graph near valleys and provides an adaptive way to cope with unbalanced data. We then theoretically justify our method through limit cut analysis. Unsupervised and semi-supervised experiments on synthetic and real data sets demonstrate the superiority of our method.
Anomaly Detection with Score functions based on Nearest Neighbor Graphs
Oct 28, 2009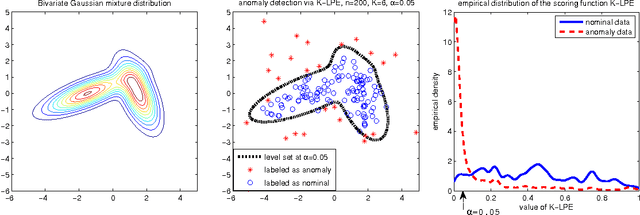
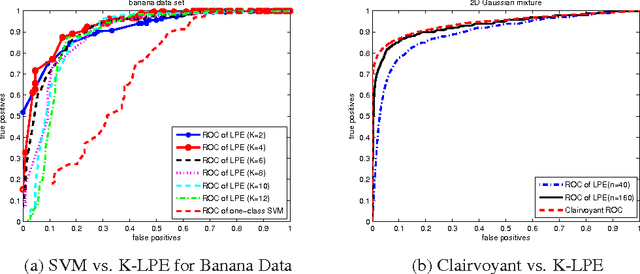
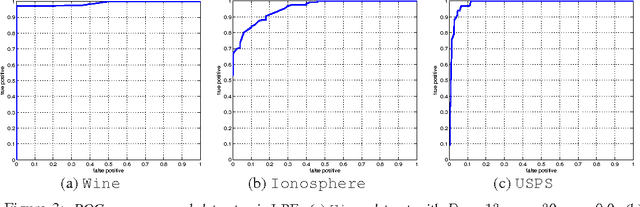
We propose a novel non-parametric adaptive anomaly detection algorithm for high dimensional data based on score functions derived from nearest neighbor graphs on $n$-point nominal data. Anomalies are declared whenever the score of a test sample falls below $\alpha$, which is supposed to be the desired false alarm level. The resulting anomaly detector is shown to be asymptotically optimal in that it is uniformly most powerful for the specified false alarm level, $\alpha$, for the case when the anomaly density is a mixture of the nominal and a known density. Our algorithm is computationally efficient, being linear in dimension and quadratic in data size. It does not require choosing complicated tuning parameters or function approximation classes and it can adapt to local structure such as local change in dimensionality. We demonstrate the algorithm on both artificial and real data sets in high dimensional feature spaces.