 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Fact Checker: Enabling High-Fidelity Detailed Caption Generation
Apr 30, 2024



Existing automatic captioning methods for visual content face challenges such as lack of detail, content hallucination, and poor instruction following. In this work, we propose VisualFactChecker (VFC), a flexible training-free pipeline that generates high-fidelity and detailed captions for both 2D images and 3D objects. VFC consists of three steps: 1) proposal, where image-to-text captioning models propose multiple initial captions; 2) verification, where a large language model (LLM) utilizes tools such as object detection and VQA models to fact-check proposed captions; 3) captioning, where an LLM generates the final caption by summarizing caption proposals and the fact check verification results. In this step, VFC can flexibly generate captions in various styles following complex instructions. We conduct comprehensive captioning evaluations using four metrics: 1) CLIP-Score for image-text similarity; 2) CLIP-Image-Score for measuring the image-image similarity between the original and the reconstructed image generated by a text-to-image model using the caption. 3) human study on Amazon Mechanical Turk; 4) GPT-4V for fine-grained evaluation. Evaluation results show that VFC outperforms state-of-the-art open-sourced captioning methods for 2D images on the COCO dataset and 3D assets on the Objaverse dataset. Our study demonstrates that by combining open-source models into a pipeline, we can attain captioning capability comparable to proprietary models such as GPT-4V, despite being over 10x smaller in model size.
Module-wise Adaptive Distillation for Multimodality Foundation Models
Oct 06, 2023



Pre-trained multimodal foundation models have demonstrated remarkable generalizability but pose challenges for deployment due to their large sizes. One effective approach to reducing their sizes is layerwise distillation, wherein small student models are trained to match the hidden representations of large teacher models at each layer. Motivated by our observation that certain architecture components, referred to as modules, contribute more significantly to the student's performance than others, we propose to track the contributions of individual modules by recording the loss decrement after distillation each module and choose the module with a greater contribution to distill more frequently. Such an approach can be naturally formulated as a multi-armed bandit (MAB) problem, where modules and loss decrements are considered as arms and rewards, respectively. We then develop a modified-Thompson sampling algorithm named OPTIMA to address the nonstationarity of module contributions resulting from model updating. Specifically, we leverage the observed contributions in recent history to estimate the changing contribution of each module and select modules based on these estimations to maximize the cumulative contribution. We evaluate the effectiveness of OPTIMA through distillation experiments on various multimodal understanding and image captioning tasks, using the CoCa-Large model (Yu et al., 2022) as the teacher model.
VideoGLUE: Video General Understanding Evaluation of Foundation Models
Jul 06, 2023



We evaluate existing foundation models video understanding capabilities using a carefully designed experiment protocol consisting of three hallmark tasks (action recognition, temporal localization, and spatiotemporal localization), eight datasets well received by the community, and four adaptation methods tailoring a foundation model (FM) for a downstream task. Moreover, we propose a scalar VideoGLUE score (VGS) to measure an FMs efficacy and efficiency when adapting to general video understanding tasks. Our main findings are as follows. First, task-specialized models significantly outperform the six FMs studied in this work, in sharp contrast to what FMs have achieved in natural language and image understanding. Second,video-native FMs, whose pretraining data contains the video modality, are generally better than image-native FMs in classifying motion-rich videos, localizing actions in time, and understanding a video of more than one action. Third, the video-native FMs can perform well on video tasks under light adaptations to downstream tasks(e.g., freezing the FM backbones), while image-native FMs win in full end-to-end finetuning. The first two observations reveal the need and tremendous opportunities to conduct research on video-focused FMs, and the last confirms that both tasks and adaptation methods matter when it comes to the evaluation of FMs.
DaTaSeg: Taming a Universal Multi-Dataset Multi-Task Segmentation Model
Jun 02, 2023



Observing the close relationship among panoptic, semantic and instance segmentation tasks, we propose to train a universal multi-dataset multi-task segmentation model: DaTaSeg.We use a shared representation (mask proposals with class predictions) for all tasks. To tackle task discrepancy, we adopt different merge operations and post-processing for different tasks. We also leverage weak-supervision, allowing our segmentation model to benefit from cheaper bounding box annotations. To share knowledge across datasets, we use text embeddings from the same semantic embedding space as classifiers and share all network parameters among datasets. We train DaTaSeg on ADE semantic, COCO panoptic, and Objects365 detection datasets. DaTaSeg improves performance on all datasets, especially small-scale datasets, achieving 54.0 mIoU on ADE semantic and 53.5 PQ on COCO panoptic. DaTaSeg also enables weakly-supervised knowledge transfer on ADE panoptic and Objects365 instance segmentation. Experiments show DaTaSeg scales with the number of training datasets and enables open-vocabulary segmentation through direct transfer. In addition, we annotate an Objects365 instance segmentation set of 1,000 images and will release it as a public benchmark.
Alternating Gradient Descent and Mixture-of-Experts for Integrated Multimodal Perception
May 10, 2023



We present Integrated Multimodal Perception (IMP), a simple and scalable multimodal multi-task training and modeling approach. IMP integrates multimodal inputs including image, video, text, and audio into a single Transformer encoder with minimal modality-specific components. IMP makes use of a novel design that combines Alternating Gradient Descent (AGD) and Mixture-of-Experts (MoE) for efficient model \& task scaling. We conduct extensive empirical studies about IMP and reveal the following key insights: 1) performing gradient descent updates by alternating on diverse heterogeneous modalities, loss functions, and tasks, while also varying input resolutions, efficiently improves multimodal understanding. 2) model sparsification with MoE on a single modality-agnostic encoder substantially improves the performance, outperforming dense models that use modality-specific encoders or additional fusion layers and greatly mitigating the conflicts between modalities. IMP achieves competitive performance on a wide range of downstream tasks including image classification, video classification, image-text, and video-text retrieval. Most notably, we train a sparse IMP-MoE-L focusing on video tasks that achieves new state-of-the-art in zero-shot video classification. Our model achieves 77.0% on Kinetics-400, 76.8% on Kinetics-600, and 76.8% on Kinetics-700 zero-shot classification accuracy, improving the previous state-of-the-art by +5%, +6.7%, and +5.8%, respectively, while using only 15% of their total training computational cost.
Towards Understanding the Effect of Pretraining Label Granularity
Mar 29, 2023



In this paper, we study how pretraining label granularity affects the generalization of deep neural networks in image classification tasks. We focus on the "fine-to-coarse" transfer learning setting where the pretraining label is more fine-grained than that of the target problem. We experiment with this method using the label hierarchy of iNaturalist 2021, and observe a 8.76% relative improvement of the error rate over the baseline. We find the following conditions are key for the improvement: 1) the pretraining dataset has a strong and meaningful label hierarchy, 2) its label function strongly aligns with that of the target task, and most importantly, 3) an appropriate level of pretraining label granularity is chosen. The importance of pretraining label granularity is further corroborated by our transfer learning experiments on ImageNet. Most notably, we show that pretraining at the leaf labels of ImageNet21k produces better transfer results on ImageNet1k than pretraining at other coarser granularity levels, which supports the common practice. Theoretically, through an analysis on a two-layer convolutional ReLU network, we prove that: 1) models trained on coarse-grained labels only respond strongly to the common or "easy-to-learn" features; 2) with the dataset satisfying the right conditions, fine-grained pretraining encourages the model to also learn rarer or "harder-to-learn" features well, thus improving the model's generalization.
Unified Visual Relationship Detection with Vision and Language Models
Mar 16, 2023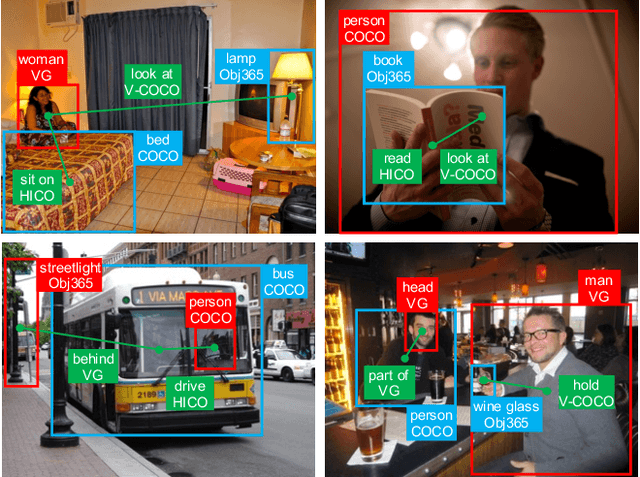
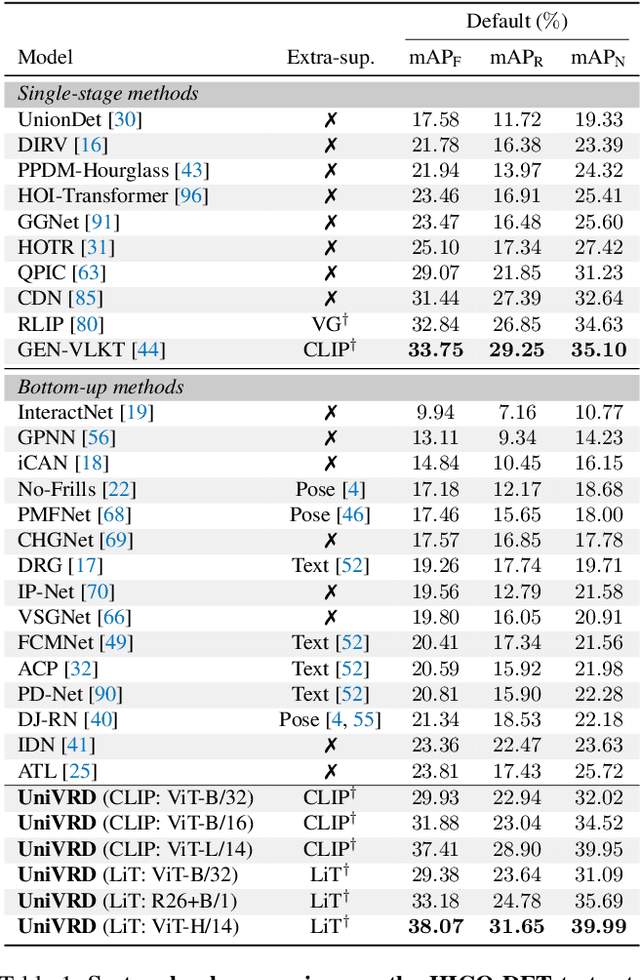
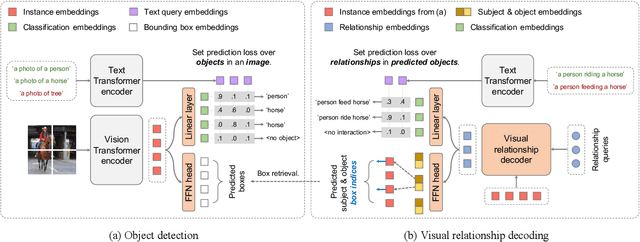
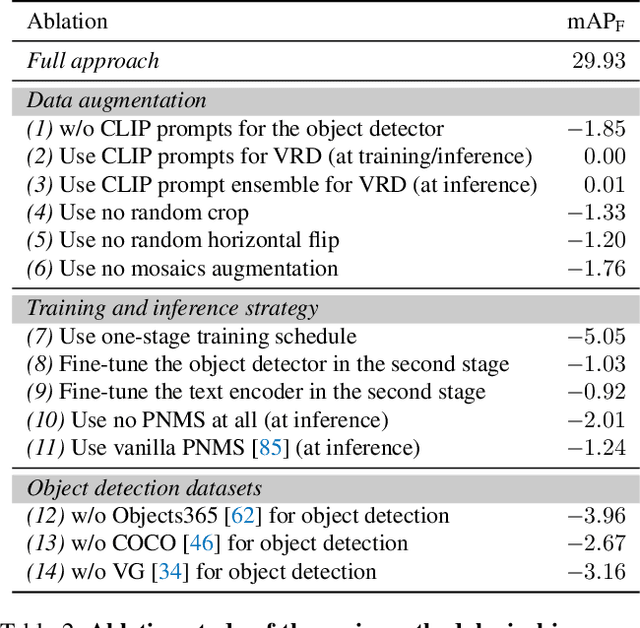
This work focuses on training a single visual relationship detector predicting over the union of label spaces from multiple datasets. Merging labels spanning different datasets could be challenging due to inconsistent taxonomies. The issue is exacerbated in visual relationship detection when second-order visual semantics are introduced between pairs of objects. To address this challenge, we propose UniVRD, a novel bottom-up method for Unified Visual Relationship Detection by leveraging vision and language models (VLMs). VLMs provide well-aligned image and text embeddings, where similar relationships are optimized to be close to each other for semantic unification. Our bottom-up design enables the model to enjoy the benefit of training with both object detection and visual relationship datasets. Empirical results on both human-object interaction detection and scene-graph generation demonstrate the competitive performance of our model. UniVRD achieves 38.07 mAP on HICO-DET, outperforming the current best bottom-up HOI detector by 60% relatively. More importantly, we show that our unified detector performs as well as dataset-specific models in mAP, and achieves further improvements when we scale up the model.
A Simple Zero-shot Prompt Weighting Technique to Improve Prompt Ensembling in Text-Image Models
Feb 13, 2023



Contrastively trained text-image models have the remarkable ability to perform zero-shot classification, that is, classifying previously unseen images into categories that the model has never been explicitly trained to identify. However, these zero-shot classifiers need prompt engineering to achieve high accuracy. Prompt engineering typically requires hand-crafting a set of prompts for individual downstream tasks. In this work, we aim to automate this prompt engineering and improve zero-shot accuracy through prompt ensembling. In particular, we ask "Given a large pool of prompts, can we automatically score the prompts and ensemble those that are most suitable for a particular downstream dataset, without needing access to labeled validation data?". We demonstrate that this is possible. In doing so, we identify several pathologies in a naive prompt scoring method where the score can be easily overconfident due to biases in pre-training and test data, and we propose a novel prompt scoring method that corrects for the biases. Using our proposed scoring method to create a weighted average prompt ensemble, our method outperforms equal average ensemble, as well as hand-crafted prompts, on ImageNet, 4 of its variants, and 11 fine-grained classification benchmarks, all while being fully automatic, optimization-free, and not requiring access to labeled validation data.
F-VLM: Open-Vocabulary Object Detection upon Frozen Vision and Language Models
Sep 30, 2022
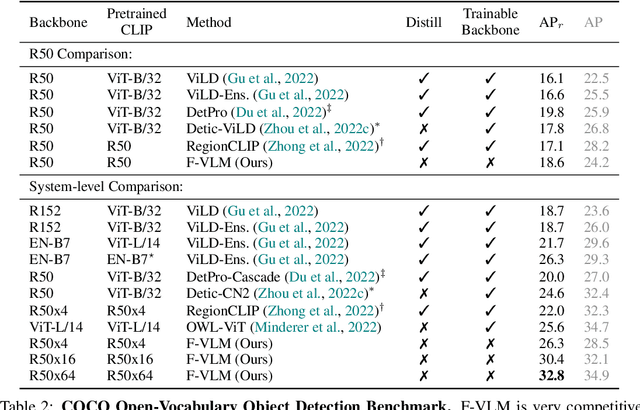
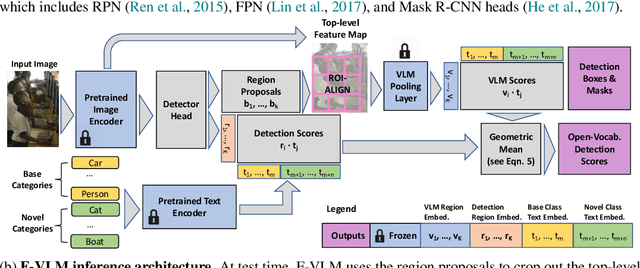
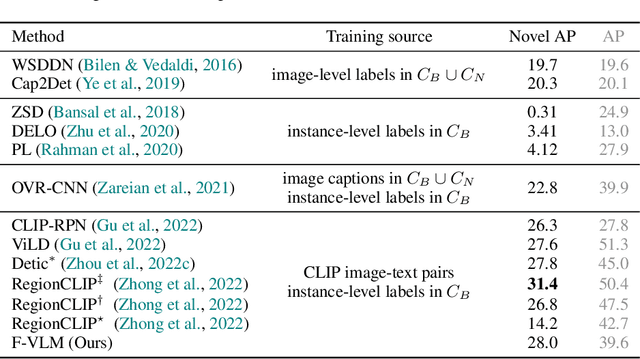
We present F-VLM, a simple open-vocabulary object detection method built upon Frozen Vision and Language Models. F-VLM simplifies the current multi-stage training pipeline by eliminating the need for knowledge distillation or detection-tailored pretraining. Surprisingly, we observe that a frozen VLM: 1) retains the locality-sensitive features necessary for detection, and 2) is a strong region classifier. We finetune only the detector head and combine the detector and VLM outputs for each region at inference time. F-VLM shows compelling scaling behavior and achieves +6.5 mask AP improvement over the previous state of the art on novel categories of LVIS open-vocabulary detection benchmark. In addition, we demonstrate very competitive results on COCO open-vocabulary detection benchmark and cross-dataset transfer detection, in addition to significant training speed-up and compute savings. Code will be released.
Multimodal Open-Vocabulary Video Classification via Pre-Trained Vision and Language Models
Jul 15, 2022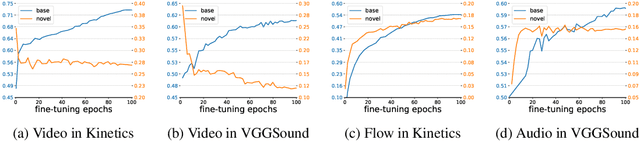
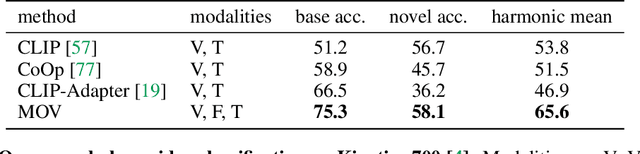
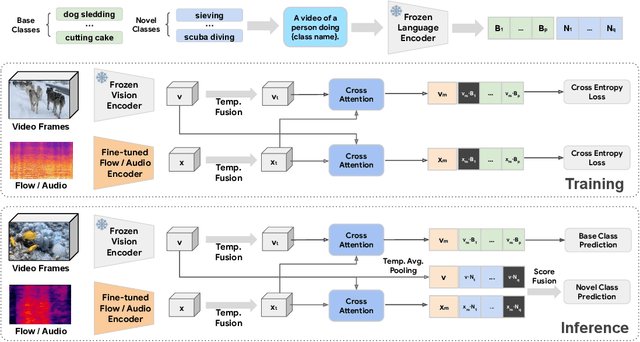
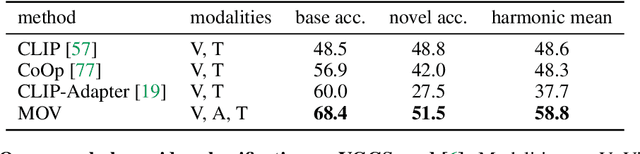
Utilizing vision and language models (VLMs) pre-trained on large-scale image-text pairs is becoming a promising paradigm for open-vocabulary visual recognition. In this work, we extend this paradigm by leveraging motion and audio that naturally exist in video. We present \textbf{MOV}, a simple yet effective method for \textbf{M}ultimodal \textbf{O}pen-\textbf{V}ocabulary video classification. In MOV, we directly use the vision encoder from pre-trained VLMs with minimal modifications to encode video, optical flow and audio spectrogram. We design a cross-modal fusion mechanism to aggregate complimentary multimodal information. Experiments on Kinetics-700 and VGGSound show that introducing flow or audio modality brings large performance gains over the pre-trained VLM and existing methods. Specifically, MOV greatly improves the accuracy on base classes, while generalizes better on novel classes. MOV achieves state-of-the-art results on UCF and HMDB zero-shot video classification benchmarks, significantly outperforming both traditional zero-shot methods and recent methods based on VLMs. Code and models will be released.