 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlender Object Detection: Diagnoses and Improvements
Nov 21, 2020


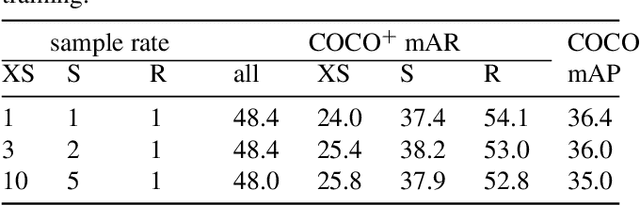
In this paper, we are concerned with the detection of a particular type of objects with extreme aspect ratios, namely slender objects. In real-world scenarios as well as widely-used datasets (such as COCO), slender objects are actually very common. However, this type of object has been largely overlooked by previous object detection algorithms. Upon our investigation, for a classical object detection method, a drastic drop of 18.9% mAP on COCO is observed, if solely evaluated on slender objects. Therefore, We systematically study the problem of slender object detection in this work. Accordingly, an analytical framework with carefully designed benchmark and evaluation protocols is established, in which different algorithms and modules can be inspected and compared. Our key findings include: 1) the essential role of anchors in label assignment; 2) the descriptive capability of the 2-point representation; 3) the crucial strategies for improving the detection of slender objects and regular objects. Our work identifies and extends the insights of existing methods that are previously underexploited. Furthermore, we propose a feature adaption strategy that achieves clear and consistent improvements over current representative object detection methods. In particular, a natural and effective extension of the center prior, which leads to a significant improvement on slender objects, is devised. We believe this work opens up new opportunities and calibrates ablation standards for future research in the field of object detection.
Adaptive Unimodal Cost Volume Filtering for Deep Stereo Matching
Sep 09, 2019
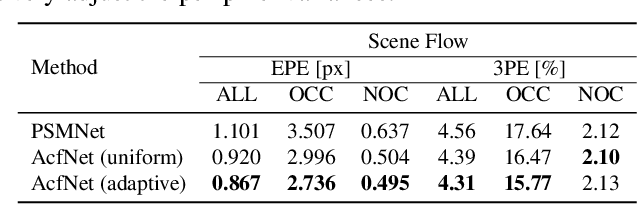
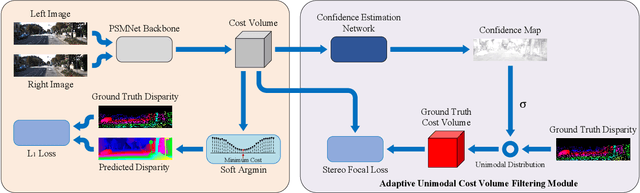
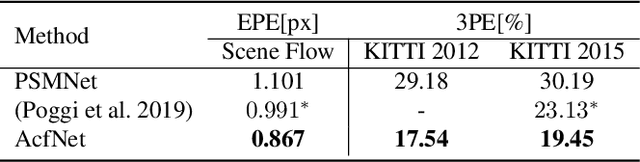
State-of-the-art deep learning based stereo matching approaches treat disparity estimation as a regression problem, where loss function is directly defined on true disparities and their estimated ones. However, disparity is just a byproduct of a matching process modeled by cost volume, while indirectly learning cost volume driven by disparity regression is prone to overfitting since cost volume is under constrained. In this paper, we propose to directly add constraints to the cost volume by filtering cost volume with unimodal distribution peaked at true disparities. In addition, variances of the unimodal distributions for each pixel are estimated to explicitly model matching uncertainty under different contexts. The proposed architecture achieves state-of-the-art performance on Scene Flow and two KITTI stereo benchmarks. In particular, our method ranked the $1^{st}$ place of KITTI 2012 evaluation and the $4^{th}$ place of KITTI 2015 evaluation (recorded on 2019.8.20).
Fashion Retrieval via Graph Reasoning Networks on a Similarity Pyramid
Aug 30, 2019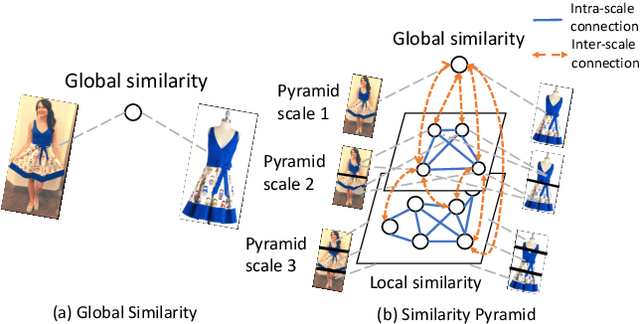
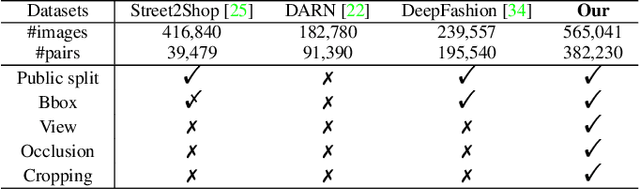
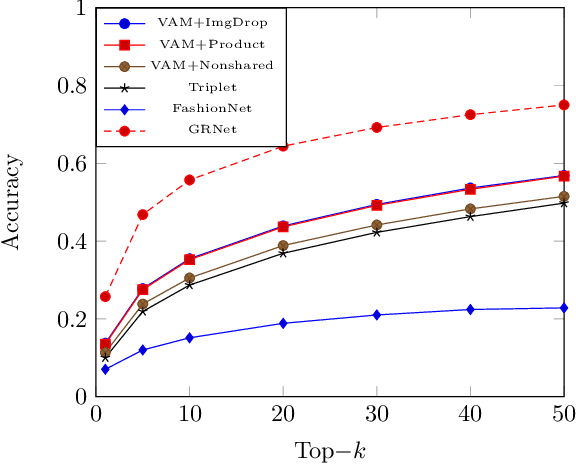
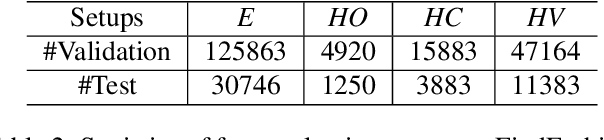
Matching clothing images from customers and online shopping stores has rich applications in E-commerce. Existing algorithms encoded an image as a global feature vector and performed retrieval with the global representation. However, discriminative local information on clothes are submerged in this global representation, resulting in sub-optimal performance. To address this issue, we propose a novel Graph Reasoning Network (GRNet) on a Similarity Pyramid, which learns similarities between a query and a gallery cloth by using both global and local representations in multiple scales. The similarity pyramid is represented by a Graph of similarity, where nodes represent similarities between clothing components at different scales, and the final matching score is obtained by message passing along edges. In GRNet, graph reasoning is solved by training a graph convolutional network, enabling to align salient clothing components to improve clothing retrieval. To facilitate future researches, we introduce a new benchmark FindFashion, containing rich annotations of bounding boxes, views, occlusions, and cropping. Extensive experiments show that GRNet obtains new state-of-the-art results on two challenging benchmarks, e.g., pushing the top-1, top-20, and top-50 accuracies on DeepFashion to 26%, 64%, and 75% (i.e., 4%, 10%, and 10% absolute improvements), outperforming competitors with large margins. On FindFashion, GRNet achieves considerable improvements on all empirical settings.
Data-Driven Neuron Allocation for Scale Aggregation Networks
Apr 20, 2019
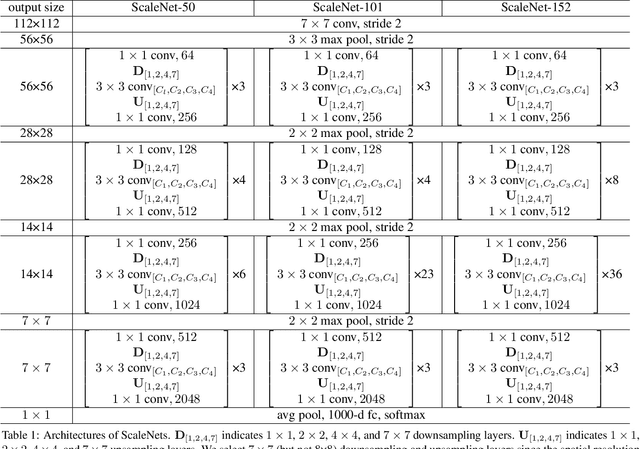
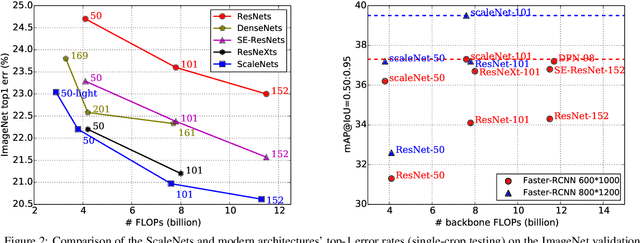
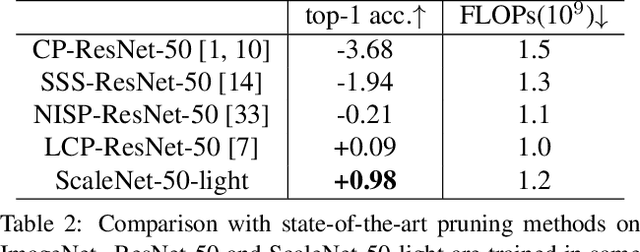
Successful visual recognition networks benefit from aggregating information spanning from a wide range of scales. Previous research has investigated information fusion of connected layers or multiple branches in a block, seeking to strengthen the power of multi-scale representations. Despite their great successes, existing practices often allocate the neurons for each scale manually, and keep the same ratio in all aggregation blocks of an entire network, rendering suboptimal performance. In this paper, we propose to learn the neuron allocation for aggregating multi-scale information in different building blocks of a deep network. The most informative output neurons in each block are preserved while others are discarded, and thus neurons for multiple scales are competitively and adaptively allocated. Our scale aggregation network (ScaleNet) is constructed by repeating a scale aggregation (SA) block that concatenates feature maps at a wide range of scales. Feature maps for each scale are generated by a stack of downsampling, convolution and upsampling operations. The data-driven neuron allocation and SA block achieve strong representational power at the cost of considerably low computational complexity. The proposed ScaleNet, by replacing all 3x3 convolutions in ResNet with our SA blocks, achieves better performance than ResNet and its outstanding variants like ResNeXt and SE-ResNet, in the same computational complexity. On ImageNet classification, ScaleNets absolutely reduce the top-1 error rate of ResNets by 1.12 (101 layers) and 1.82 (50 layers). On COCO object detection, ScaleNets absolutely improve the mmAP with backbone of ResNets by 3.6 (101 layers) and 4.6 (50 layers) on Faster RCNN, respectively. Code and models are released at https://github.com/Eli-YiLi/ScaleNet.
* 11 pages,
Intra-Ensemble in Neural Networks
Apr 09, 2019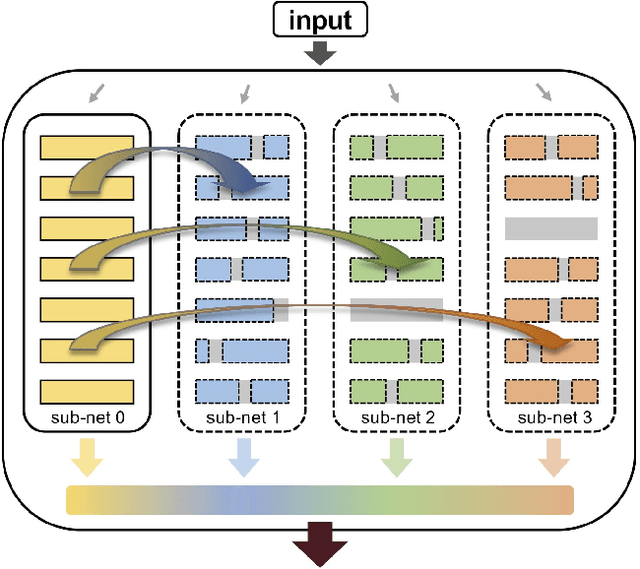
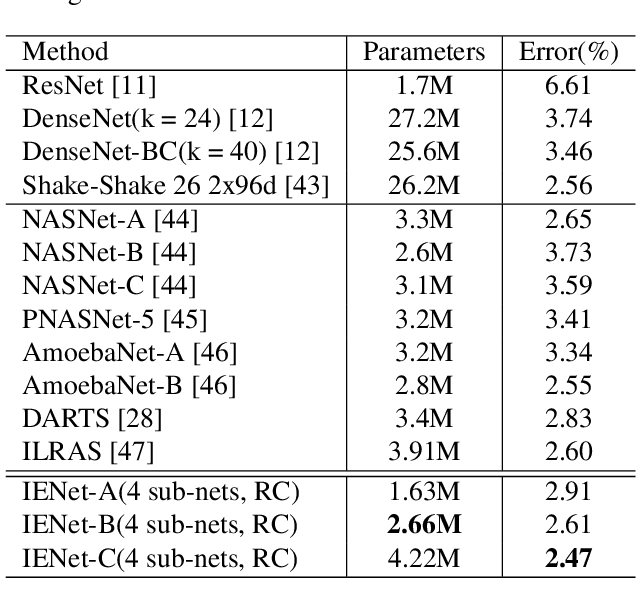
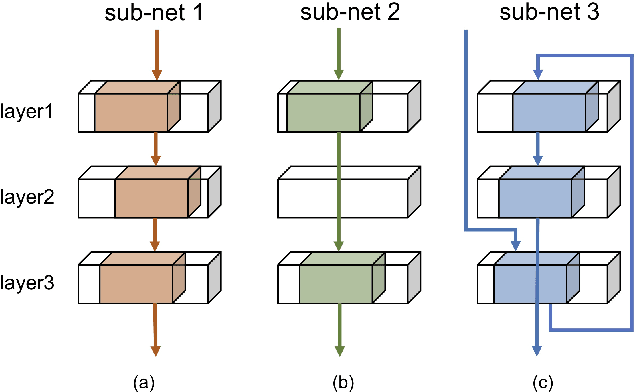
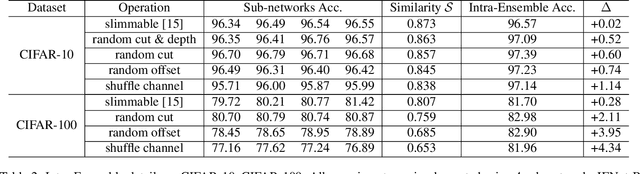
Improving model performance is always the key problem in machine learning including deep learning. However, stand-alone neural networks always suffer from marginal effect when stacking more layers. At the same time, ensemble is a useful technique to further enhance model performance. Nevertheless, training several independent stand-alone deep neural networks costs multiple resources. In this work, we propose Intra-Ensemble, an end-to-end strategy with stochastic training operations to train several sub-networks simultaneously within one neural network. Additional parameter size is marginal since the majority of parameters are mutually shared. Meanwhile, stochastic training increases the diversity of sub-networks with weight sharing, which significantly enhances intra-ensemble performance. Extensive experiments prove the applicability of intra-ensemble on various kinds of datasets and network architectures. Our models achieve comparable results with the state-of-the-art architectures on CIFAR-10 and CIFAR-100.
Learning Efficient Detector with Semi-supervised Adaptive Distillation
Jan 14, 2019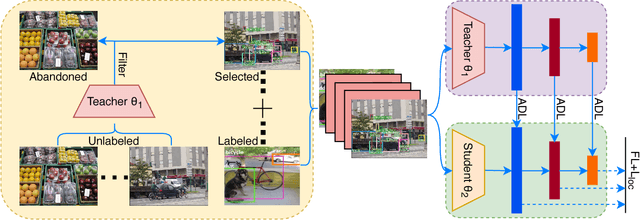
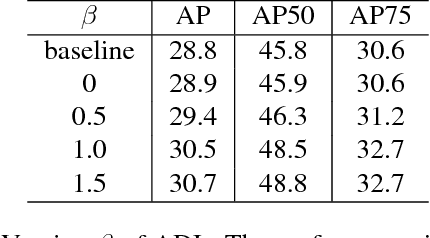
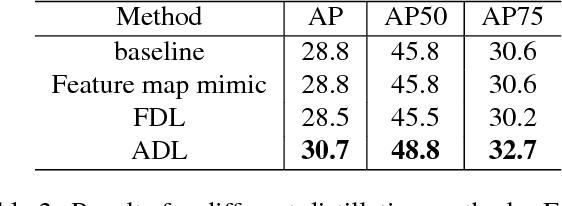
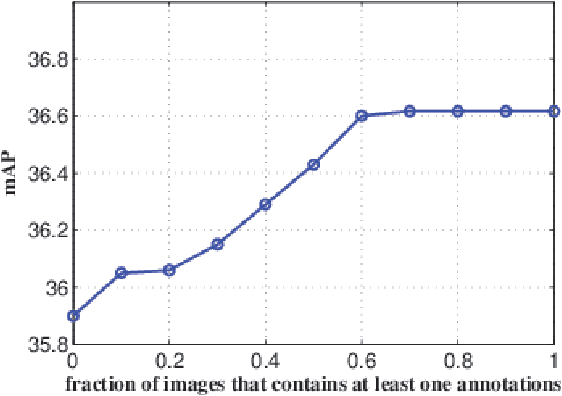
Knowledge Distillation (KD) has been used in image classification for model compression. However, rare studies apply this technology on single-stage object detectors. Focal loss shows that the accumulated errors of easily-classified samples dominate the overall loss in the training process. This problem is also encountered when applying KD in the detection task. For KD, the teacher-defined hard samples are far more important than any others. We propose ADL to address this issue by adaptively mimicking the teacher's logits, with more attention paid on two types of hard samples: hard-to-learn samples predicted by teacher with low certainty and hard-to-mimic samples with a large gap between the teacher's and the student's prediction. ADL enlarges the distillation loss for hard-to-learn and hard-to-mimic samples and reduces distillation loss for the dominant easy samples, enabling distillation to work on the single-stage detector first time, even if the student and the teacher are identical. Besides, ADL is effective in both the supervised setting and the semi-supervised setting, even when the labeled data and unlabeled data are from different distributions. For distillation on unlabeled data, ADL achieves better performance than existing data distillation which simply utilizes hard targets, making the student detector surpass its teacher. On the COCO database, semi-supervised adaptive distillation (SAD) makes a student detector with a backbone of ResNet-50 surpasses its teacher with a backbone of ResNet-101, while the student has half of the teacher's computation complexity. The code is avaiable at https://github.com/Tangshitao/Semi-supervised-Adaptive-Distillation
Learning Segmentation Masks with the Independence Prior
Nov 13, 2018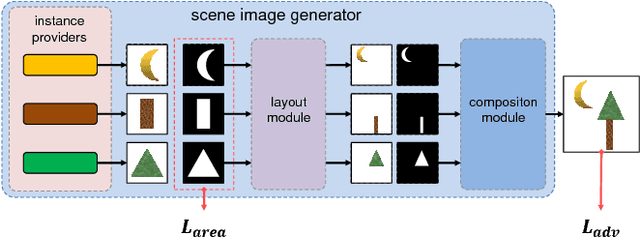
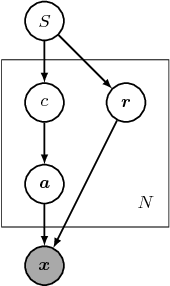


An instance with a bad mask might make a composite image that uses it look fake. This encourages us to learn segmentation by generating realistic composite images. To achieve this, we propose a novel framework that exploits a new proposed prior called the independence prior based on Generative Adversarial Networks (GANs). The generator produces an image with multiple category-specific instance providers, a layout module and a composition module. Firstly, each provider independently outputs a category-specific instance image with a soft mask. Then the provided instances' poses are corrected by the layout module. Lastly, the composition module combines these instances into a final image. Training with adversarial loss and penalty for mask area, each provider learns a mask that is as small as possible but enough to cover a complete category-specific instance. Weakly supervised semantic segmentation methods widely use grouping cues modeling the association between image parts, which are either artificially designed or learned with costly segmentation labels or only modeled on local pairs. Unlike them, our method automatically models the dependence between any parts and learns instance segmentation. We apply our framework in two cases: (1) Foreground segmentation on category-specific images with box-level annotation. (2) Unsupervised learning of instance appearances and masks with only one image of homogeneous object cluster (HOC). We get appealing results in both tasks, which shows the independence prior is useful for instance segmentation and it is possible to unsupervisedly learn instance masks with only one image.
Toward Characteristic-Preserving Image-based Virtual Try-On Network
Sep 12, 2018

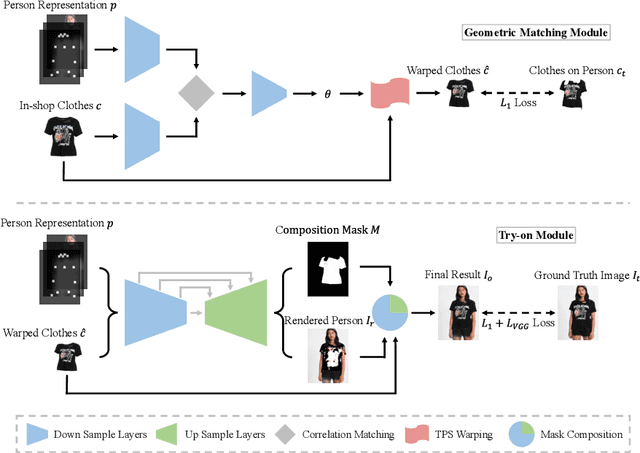

Image-based virtual try-on systems for fitting new in-shop clothes into a person image have attracted increasing research attention, yet is still challenging. A desirable pipeline should not only transform the target clothes into the most fitting shape seamlessly but also preserve well the clothes identity in the generated image, that is, the key characteristics (e.g. texture, logo, embroidery) that depict the original clothes. However, previous image-conditioned generation works fail to meet these critical requirements towards the plausible virtual try-on performance since they fail to handle large spatial misalignment between the input image and target clothes. Prior work explicitly tackled spatial deformation using shape context matching, but failed to preserve clothing details due to its coarse-to-fine strategy. In this work, we propose a new fully-learnable Characteristic-Preserving Virtual Try-On Network(CP-VTON) for addressing all real-world challenges in this task. First, CP-VTON learns a thin-plate spline transformation for transforming the in-shop clothes into fitting the body shape of the target person via a new Geometric Matching Module (GMM) rather than computing correspondences of interest points as prior works did. Second, to alleviate boundary artifacts of warped clothes and make the results more realistic, we employ a Try-On Module that learns a composition mask to integrate the warped clothes and the rendered image to ensure smoothness. Extensive experiments on a fashion dataset demonstrate our CP-VTON achieves the state-of-the-art virtual try-on performance both qualitatively and quantitatively.
Fast Video Shot Transition Localization with Deep Structured Models
Aug 13, 2018
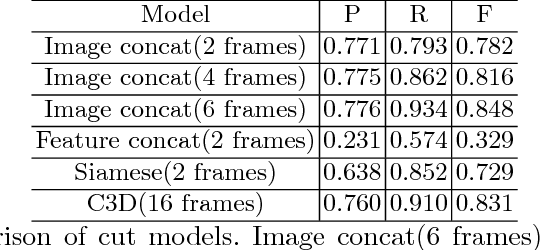
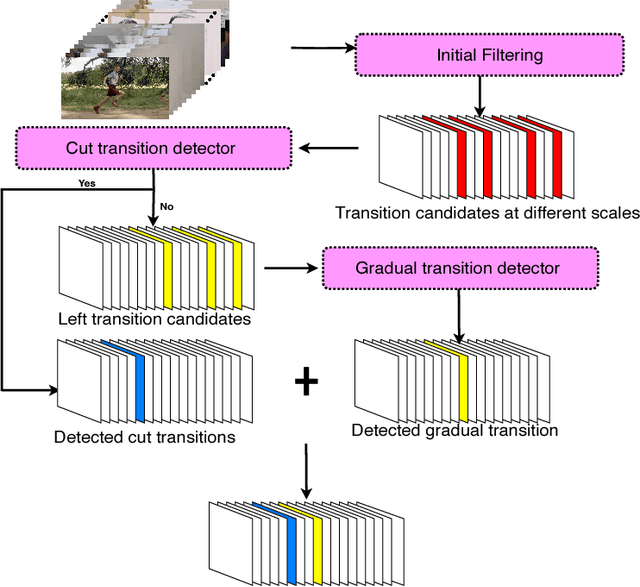
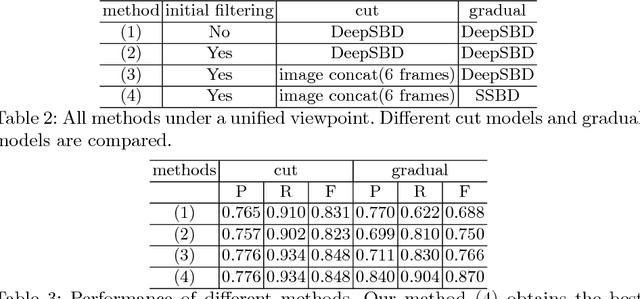
Detection of video shot transition is a crucial pre-processing step in video analysis. Previous studies are restricted on detecting sudden content changes between frames through similarity measurement and multi-scale operations are widely utilized to deal with transitions of various lengths. However, localization of gradual transitions are still under-explored due to the high visual similarity between adjacent frames. Cut shot transitions are abrupt semantic breaks while gradual shot transitions contain low-level spatial-temporal patterns caused by video effects in addition to the gradual semantic breaks, e.g. dissolve. In order to address the problem, we propose a structured network which is able to detect these two shot transitions using targeted models separately. Considering speed performance trade-offs, we design a smart framework. With one TITAN GPU, the proposed method can achieve a 30\(\times\) real-time speed. Experiments on public TRECVID07 and RAI databases show that our method outperforms the state-of-the-art methods. In order to train a high-performance shot transition detector, we contribute a new database ClipShots, which contains 128636 cut transitions and 38120 gradual transitions from 4039 online videos. ClipShots intentionally collect short videos for more hard cases caused by hand-held camera vibrations, large object motions, and occlusion.
Instance-level Human Parsing via Part Grouping Network
Aug 01, 2018
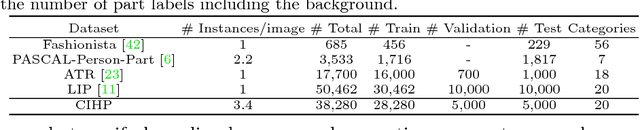
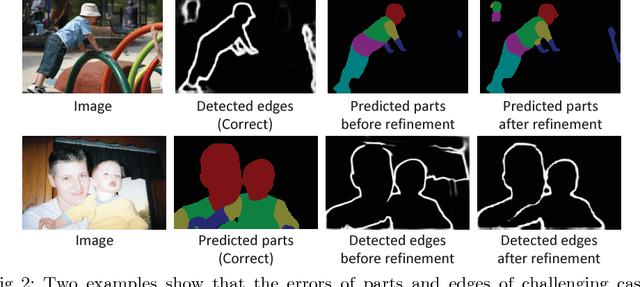

Instance-level human parsing towards real-world human analysis scenarios is still under-explored due to the absence of sufficient data resources and technical difficulty in parsing multiple instances in a single pass. Several related works all follow the "parsing-by-detection" pipeline that heavily relies on separately trained detection models to localize instances and then performs human parsing for each instance sequentially. Nonetheless, two discrepant optimization targets of detection and parsing lead to suboptimal representation learning and error accumulation for final results. In this work, we make the first attempt to explore a detection-free Part Grouping Network (PGN) for efficiently parsing multiple people in an image in a single pass. Our PGN reformulates instance-level human parsing as two twinned sub-tasks that can be jointly learned and mutually refined via a unified network: 1) semantic part segmentation for assigning each pixel as a human part (e.g., face, arms); 2) instance-aware edge detection to group semantic parts into distinct person instances. Thus the shared intermediate representation would be endowed with capabilities in both characterizing fine-grained parts and inferring instance belongings of each part. Finally, a simple instance partition process is employed to get final results during inference. We conducted experiments on PASCAL-Person-Part dataset and our PGN outperforms all state-of-the-art methods. Furthermore, we show its superiority on a newly collected multi-person parsing dataset (CIHP) including 38,280 diverse images, which is the largest dataset so far and can facilitate more advanced human analysis. The CIHP benchmark and our source code are available at http://sysu-hcp.net/lip/.