 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Queries Reinforcement Learning: Self-Aware Policy Execution for VLA Models
Jun 12, 2026Vision-language-action (VLA) models are powerful action generators for robot manipulation, but they are typically executed with fixed inference and replanning schedules. This rigidity ignores the uneven difficulty of robot control: contact-rich or uncertain states may need more computation and fresher feedback, while easier states can often be handled with fewer inference steps and longer open-loop execution. We propose Elastic Queries Reinforcement Learning (EQRL), a framework that makes each VLA policy query elastic. A lightweight latent-schedule adaptor jointly selects the latent input, denoising budget, and action chunk length, without fine-tuning the underlying VLA model. To make scheduling difficulty-aware, EQRL trains a critic over the joint latent-schedule action and derives a state difficulty signal from critic ensemble disagreement. This signal guides compute toward difficult states, while a learned residual allows task-driven correction. We formulate variable chunk execution as query-level macro-action RL with chunk-dependent discounting and an amortized number-of-function-evaluations (NFE) budget. Across simulation and real-robot manipulation, EQRL reduces amortized inference cost while preserving or improving task success.
ReasonAlloc: Hierarchical Decoding-Time KV Cache Budget Allocation for Reasoning Models
Jun 09, 2026Long chain-of-thought (CoT) trajectories in large language model (LLM) reasoning cause severe inference bottlenecks due to rapid key-value (KV) cache growth. Current decoding-time compression methods mitigate this issue via token eviction, but typically assume a uniform budget distribution across all layers and heads. In contrast, existing non-uniform budget allocation methods are predominantly designed for the static prompt prefill phase, and they do not capture the stepwise context demands of autoregressive reasoning. To bridge this gap, we propose ReasonAlloc, a training-free framework that recasts decoding-time KV compression as a hierarchical budget allocation problem. ReasonAlloc operates at two complementary levels: an offline layer-wise preallocation strategy captures an architecture-driven demand pattern which we call ``\textit{Reasoning Wave}'', while an online head-wise strategy reallocates resources during decoding to information-rich heads based on real-time utility. Evaluations on mathematical reasoning benchmarks (MATH-500, AIME~2024) using DeepSeek-R1-Distill-Llama-8B, DeepSeek-R1-Distill-Qwen-14B, and AceReason-14B show that ReasonAlloc outperforms uniform-budget R-KV, SnapKV, and Pyramid-RKV (a baseline enforcing a static, monotonically decreasing layer budget), with the largest gains at small budgets (128-512 tokens). ReasonAlloc is plug-and-play with existing token-eviction policies and introduces negligible inference-time overhead.
The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
Edit Where You Mean: Region-Aware Adapter Injection for Mask-Free Local Image Editing
Apr 26, 2026Large diffusion transformers (DiTs) follow global editing instructions well but consistently leak local edits into unrelated regions, because joint-attention architectures offer no explicit channel telling the network where to apply the edit. We introduce REDEdit, a co-trained, instruction- and region-aware adapter framework that retrofits a frozen DiT into a precise local editor without modifying its backbone weights. A lightweight Block Adapter at every transformer block injects a structured condition stream that factorizes what to edit (instruction semantics) from where to edit (spatial mask); a learned SpatialGate routes the adapter signal selectively into the edit region while keeping the rest of the image near-identical to the source; and a Region-Aware Loss focuses the training objective on the changing pixels. Because these components make the backbone's internal representation mask-aware end-to-end, a thin MaskPredictor head trained jointly with the editor can ground the edit region directly from the instruction and source image eliminating any user-mask requirement at deployment. We evaluate on two complementary benchmarks: MagicBrush (paired ground-truth targets) to measure pixel-level preservation and edit accuracy, and Emu-Edit Test (no ground-truth images, 9 diverse edit categories) to stress-test instruction following and generalization across edit types. On both, REDEdit achieves state-of-the-art results, simultaneously outperforming mask-free and oracle-mask baselines. A seven-variant ablation cleanly isolates the contribution of each component.
EditCaption: Human-Aligned Instruction Synthesis for Image Editing via Supervised Fine-Tuning and Direct Preference Optimization
Apr 09, 2026High-quality training triplets (source-target image pairs with precise editing instructions) are a critical bottleneck for scaling instruction-guided image editing models. Vision-language models (VLMs) are widely used for automated instruction synthesis, but we identify three systematic failure modes in image-pair settings: orientation inconsistency (e.g., left/right confusion), viewpoint ambiguity, and insufficient fine-grained attribute description. Human evaluation shows that over 47% of instructions from strong baseline VLMs contain critical errors unusable for downstream training. We propose EditCaption, a scalable two-stage post-training pipeline for VLM-based instruction synthesis. Stage 1 builds a 100K supervised fine-tuning (SFT) dataset by combining GLM automatic annotation, EditScore-based filtering, and human refinement for spatial, directional, and attribute-level accuracy. Stage 2 collects 10K human preference pairs targeting the three failure modes and applies direct preference optimization (DPO) for alignment beyond SFT alone. On Eval-400, ByteMorph-Bench, and HQ-Edit, fine-tuned Qwen3-VL models outperform open-source baselines; the 235B model reaches 4.712 on Eval-400 (vs. Gemini-3-Pro 4.706, GPT-4.1 4.220, Kimi-K2.5 4.111) and 4.588 on ByteMorph-Bench (vs. Gemini-3-Pro 4.522, GPT-4.1 3.412). Human evaluation shows critical errors falling from 47.75% to 23% and correctness rising from 41.75% to 66%. The work offers a practical path to scalable, human-aligned instruction synthesis for image editing data.
IdGlow: Dynamic Identity Modulation for Multi-Subject Generation
Feb 28, 2026Multi-subject image generation requires seamlessly harmonizing multiple reference identities within a coherent scene. However, existing methods relying on rigid spatial masks or localized attention often struggle with the "stability-plasticity dilemma," particularly failing in tasks that require complex structural deformations, such as identity-preserving age transformation. To address this, we present IdGlow, a mask-free, progressive two-stage framework built upon Flow Matching diffusion models. In the supervised fine-tuning (SFT) stage, we introduce task-adaptive timestep scheduling aligned with diffusion generative dynamics: a linear decay schedule that progressively relaxes constraints for natural group composition, and a temporal gating mechanism that concentrates identity injection within a critical semantic window, successfully preserving adult facial semantics without overriding child-like anatomical structures. To resolve attribute leakage and semantic ambiguity without explicit layout inputs, we further integrate a badcase-driven Vision-Language Model (VLM) for precise, context-aware prompt synthesis. In the second stage, we design a Fine-Grained Group-Level Direct Preference Optimization (DPO) with a weighted margin formulation to simultaneously eliminate multi-subject artifacts, elevate texture harmony, and recalibrate identity fidelity towards real-world distributions. Extensive experiments on two challenging benchmarks -- direct multi-person fusion and age-transformed group generation -- demonstrate that IdGlow fundamentally mitigates the stability-plasticity conflict, achieving a superior Pareto balance between state-of-the-art facial fidelity and commercial-grade aesthetic quality.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025

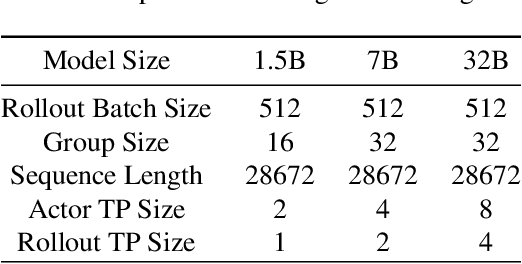
Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
A first-order method for nonconvex-nonconcave minimax problems under a local Kurdyka-Łojasiewicz condition
Jul 02, 2025We study a class of nonconvex-nonconcave minimax problems in which the inner maximization problem satisfies a local Kurdyka-{\L}ojasiewicz (KL) condition that may vary with the outer minimization variable. In contrast to the global KL or Polyak-{\L}ojasiewicz (PL) conditions commonly assumed in the literature -- which are significantly stronger and often too restrictive in practice -- this local KL condition accommodates a broader range of practical scenarios. However, it also introduces new analytical challenges. In particular, as an optimization algorithm progresses toward a stationary point of the problem, the region over which the KL condition holds may shrink, resulting in a more intricate and potentially ill-conditioned landscape. To address this challenge, we show that the associated maximal function is locally H\"older smooth. Leveraging this key property, we develop an inexact proximal gradient method for solving the minimax problem, where the inexact gradient of the maximal function is computed by applying a proximal gradient method to a KL-structured subproblem. Under mild assumptions, we establish complexity guarantees for computing an approximate stationary point of the minimax problem.
Frequency-Adaptive Low-Latency Object Detection Using Events and Frames
Dec 05, 2024



Fusing Events and RGB images for object detection leverages the robustness of Event cameras in adverse environments and the rich semantic information provided by RGB cameras. However, two critical mismatches: low-latency Events \textit{vs.}~high-latency RGB frames; temporally sparse labels in training \textit{vs.}~continuous flow in inference, significantly hinder the high-frequency fusion-based object detection. To address these challenges, we propose the \textbf{F}requency-\textbf{A}daptive Low-Latency \textbf{O}bject \textbf{D}etector (FAOD). FAOD aligns low-frequency RGB frames with high-frequency Events through an Align Module, which reinforces cross-modal style and spatial proximity to address the Event-RGB Mismatch. We further propose a training strategy, Time Shift, which enforces the module to align the prediction from temporally shifted Event-RGB pairs and their original representation, that is, consistent with Event-aligned annotations. This strategy enables the network to use high-frequency Event data as the primary reference while treating low-frequency RGB images as supplementary information, retaining the low-latency nature of the Event stream toward high-frequency detection. Furthermore, we observe that these corrected Event-RGB pairs demonstrate better generalization from low training frequency to higher inference frequencies compared to using Event data alone. Extensive experiments on the PKU-DAVIS-SOD and DSEC-Detection datasets demonstrate that our FAOD achieves SOTA performance. Specifically, in the PKU-DAVIS-SOD Dataset, FAOD achieves 9.8 points improvement in terms of the mAP in fully paired Event-RGB data with only a quarter of the parameters compared to SODFormer, and even maintains robust performance (only a 3 points drop in mAP) under 80$\times$ Event-RGB frequency mismatch.
FE-DeTr: Keypoint Detection and Tracking in Low-quality Image Frames with Events
Mar 18, 2024



Keypoint detection and tracking in traditional image frames are often compromised by image quality issues such as motion blur and extreme lighting conditions. Event cameras offer potential solutions to these challenges by virtue of their high temporal resolution and high dynamic range. However, they have limited performance in practical applications due to their inherent noise in event data. This paper advocates fusing the complementary information from image frames and event streams to achieve more robust keypoint detection and tracking. Specifically, we propose a novel keypoint detection network that fuses the textural and structural information from image frames with the high-temporal-resolution motion information from event streams, namely FE-DeTr. The network leverages a temporal response consistency for supervision, ensuring stable and efficient keypoint detection. Moreover, we use a spatio-temporal nearest-neighbor search strategy for robust keypoint tracking. Extensive experiments are conducted on a new dataset featuring both image frames and event data captured under extreme conditions. The experimental results confirm the superior performance of our method over both existing frame-based and event-based methods.