 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdit Where You Mean: Region-Aware Adapter Injection for Mask-Free Local Image Editing
Apr 26, 2026Large diffusion transformers (DiTs) follow global editing instructions well but consistently leak local edits into unrelated regions, because joint-attention architectures offer no explicit channel telling the network where to apply the edit. We introduce REDEdit, a co-trained, instruction- and region-aware adapter framework that retrofits a frozen DiT into a precise local editor without modifying its backbone weights. A lightweight Block Adapter at every transformer block injects a structured condition stream that factorizes what to edit (instruction semantics) from where to edit (spatial mask); a learned SpatialGate routes the adapter signal selectively into the edit region while keeping the rest of the image near-identical to the source; and a Region-Aware Loss focuses the training objective on the changing pixels. Because these components make the backbone's internal representation mask-aware end-to-end, a thin MaskPredictor head trained jointly with the editor can ground the edit region directly from the instruction and source image eliminating any user-mask requirement at deployment. We evaluate on two complementary benchmarks: MagicBrush (paired ground-truth targets) to measure pixel-level preservation and edit accuracy, and Emu-Edit Test (no ground-truth images, 9 diverse edit categories) to stress-test instruction following and generalization across edit types. On both, REDEdit achieves state-of-the-art results, simultaneously outperforming mask-free and oracle-mask baselines. A seven-variant ablation cleanly isolates the contribution of each component.
EditCaption: Human-Aligned Instruction Synthesis for Image Editing via Supervised Fine-Tuning and Direct Preference Optimization
Apr 09, 2026High-quality training triplets (source-target image pairs with precise editing instructions) are a critical bottleneck for scaling instruction-guided image editing models. Vision-language models (VLMs) are widely used for automated instruction synthesis, but we identify three systematic failure modes in image-pair settings: orientation inconsistency (e.g., left/right confusion), viewpoint ambiguity, and insufficient fine-grained attribute description. Human evaluation shows that over 47% of instructions from strong baseline VLMs contain critical errors unusable for downstream training. We propose EditCaption, a scalable two-stage post-training pipeline for VLM-based instruction synthesis. Stage 1 builds a 100K supervised fine-tuning (SFT) dataset by combining GLM automatic annotation, EditScore-based filtering, and human refinement for spatial, directional, and attribute-level accuracy. Stage 2 collects 10K human preference pairs targeting the three failure modes and applies direct preference optimization (DPO) for alignment beyond SFT alone. On Eval-400, ByteMorph-Bench, and HQ-Edit, fine-tuned Qwen3-VL models outperform open-source baselines; the 235B model reaches 4.712 on Eval-400 (vs. Gemini-3-Pro 4.706, GPT-4.1 4.220, Kimi-K2.5 4.111) and 4.588 on ByteMorph-Bench (vs. Gemini-3-Pro 4.522, GPT-4.1 3.412). Human evaluation shows critical errors falling from 47.75% to 23% and correctness rising from 41.75% to 66%. The work offers a practical path to scalable, human-aligned instruction synthesis for image editing data.
CSSDF-Net: Safe Motion Planning Based on Neural Implicit Representations of Configuration Space Distance Field
Mar 19, 2026High-dimensional manipulator operation in unstructured environments requires a differentiable, scene-agnostic distance query mechanism to guide safe motion generation. Existing geometric collision checkers are typically non-differentiable, while workspace-based implicit distance models are hindered by the highly nonlinear workspace--configuration mapping and often suffer from poor convergence; moreover, self-collision and environment collision are commonly handled as separate constraints. We propose Configuration-Space Signed Distance Field-Net (CSSDF-Net), which learns a continuous signed distance field directly in configuration space to provide joint-space distance and gradient queries under a unified geometric notion of safety. To enable zero-shot generalization without environment-specific retraining, we introduce a spatial-hashing-based data generation pipeline that encodes robot-centric geometric priors and supports efficient retrieval of risk configurations for arbitrary obstacle point sets. The learned distance field is integrated into safety-constrained trajectory optimization and receding-horizon MPC, enabling both offline planning and online reactive avoidance. Experiments on a planar arm and a 7-DoF manipulator demonstrate stable gradients, effective collision avoidance in static and dynamic scenes, and practical inference latency for large-scale point-cloud queries, supporting deployment in previously unseen environments.
SegviGen: Repurposing 3D Generative Model for Part Segmentation
Mar 17, 2026We introduce SegviGen, a framework that repurposes native 3D generative models for 3D part segmentation. Existing pipelines either lift strong 2D priors into 3D via distillation or multi-view mask aggregation, often suffering from cross-view inconsistency and blurred boundaries, or explore native 3D discriminative segmentation, which typically requires large-scale annotated 3D data and substantial training resources. In contrast, SegviGen leverages the structured priors encoded in pretrained 3D generative model to induce segmentation through distinctive part colorization, establishing a novel and efficient framework for part segmentation. Specifically, SegviGen encodes a 3D asset and predicts part-indicative colors on active voxels of a geometry-aligned reconstruction. It supports interactive part segmentation, full segmentation, and full segmentation with 2D guidance in a unified framework. Extensive experiments show that SegviGen improves over the prior state of the art by 40% on interactive part segmentation and by 15% on full segmentation, while using only 0.32% of the labeled training data. It demonstrates that pretrained 3D generative priors transfer effectively to 3D part segmentation, enabling strong performance with limited supervision. See our project page at https://fenghora.github.io/SegviGen-Page/.
PROMO: Promptable Outfitting for Efficient High-Fidelity Virtual Try-On
Mar 12, 2026Virtual Try-on (VTON) has become a core capability for online retail, where realistic try-on results provide reliable fit guidance, reduce returns, and benefit both consumers and merchants. Diffusion-based VTON methods achieve photorealistic synthesis, yet often rely on intricate architectures such as auxiliary reference networks and suffer from slow sampling, making the trade-off between fidelity and efficiency a persistent challenge. We approach VTON as a structured image editing problem that demands strong conditional generation under three key requirements: subject preservation, faithful texture transfer, and seamless harmonization. Under this perspective, our training framework is generic and transfers to broader image editing tasks. Moreover, the paired data produced by VTON constitutes a rich supervisory resource for training general-purpose editors. We present PROMO, a promptable virtual try-on framework built upon a Flow Matching DiT backbone with latent multi-modal conditional concatenation. By leveraging conditioning efficiency and self-reference mechanisms, our approach substantially reduces inference overhead. On standard benchmarks, PROMO surpasses both prior VTON methods and general image editing models in visual fidelity while delivering a competitive balance between quality and speed. These results demonstrate that flow-matching transformers, coupled with latent multi-modal conditioning and self-reference acceleration, offer an effective and training-efficient solution for high-quality virtual try-on.
Orthogonal Approximate Message Passing Algorithms for Rectangular Spiked Matrix Models with Rotationally Invariant Noise
Feb 03, 2026We propose an orthogonal approximate message passing (OAMP) algorithm for signal estimation in the rectangular spiked matrix model with general rotationally invariant (RI) noise. We establish a rigorous state evolution that exactly characterizes the high-dimensional dynamics of the algorithm. Building on this framework, we derive an optimal variant of OAMP that minimizes the predicted mean-squared error at each iteration. For the special case of i.i.d. Gaussian noise, the fixed point of the proposed OAMP algorithm coincides with that of the standard AMP algorithm. For general RI noise models, we conjecture that the optimal OAMP algorithm is statistically optimal within a broad class of iterative methods, and achieves Bayes-optimal performance in certain regimes.
Orthogonal Approximate Message Passing with Optimal Spectral Initializations for Rectangular Spiked Matrix Models
Dec 22, 2025We propose an orthogonal approximate message passing (OAMP) algorithm for signal estimation in the rectangular spiked matrix model with general rotationally invariant (RI) noise. We establish a rigorous state evolution that precisely characterizes the algorithm's high-dimensional dynamics and enables the construction of iteration-wise optimal denoisers. Within this framework, we accommodate spectral initializations under minimal assumptions on the empirical noise spectrum. In the rectangular setting, where a single rank-one component typically generates multiple informative outliers, we further propose a procedure for combining these outliers under mild non-Gaussian signal assumptions. For general RI noise models, the predicted performance of the proposed optimal OAMP algorithm agrees with replica-symmetric predictions for the associated Bayes-optimal estimator, and we conjecture that it is statistically optimal within a broad class of iterative estimation methods.
InterMoE: Individual-Specific 3D Human Interaction Generation via Dynamic Temporal-Selective MoE
Nov 17, 2025



Generating high-quality human interactions holds significant value for applications like virtual reality and robotics. However, existing methods often fail to preserve unique individual characteristics or fully adhere to textual descriptions. To address these challenges, we introduce InterMoE, a novel framework built on a Dynamic Temporal-Selective Mixture of Experts. The core of InterMoE is a routing mechanism that synergistically uses both high-level text semantics and low-level motion context to dispatch temporal motion features to specialized experts. This allows experts to dynamically determine the selection capacity and focus on critical temporal features, thereby preserving specific individual characteristic identities while ensuring high semantic fidelity. Extensive experiments show that InterMoE achieves state-of-the-art performance in individual-specific high-fidelity 3D human interaction generation, reducing FID scores by 9% on the InterHuman dataset and 22% on InterX.
BezierSeg: Parametric Shape Representation for Fast Object Segmentation in Medical Images
Aug 02, 2021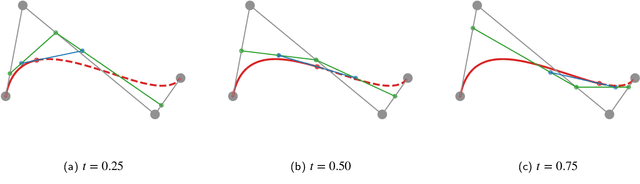
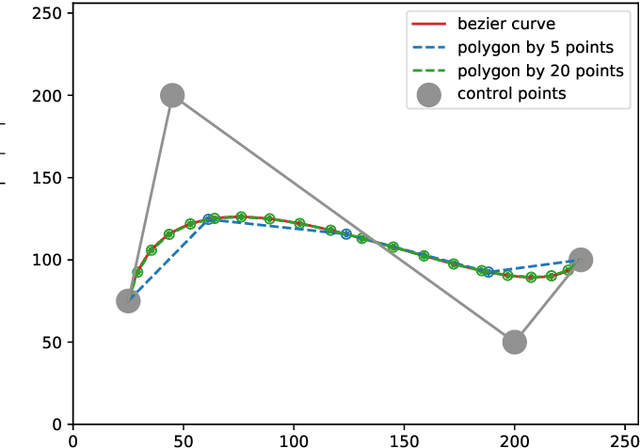
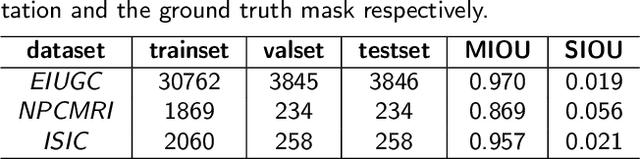
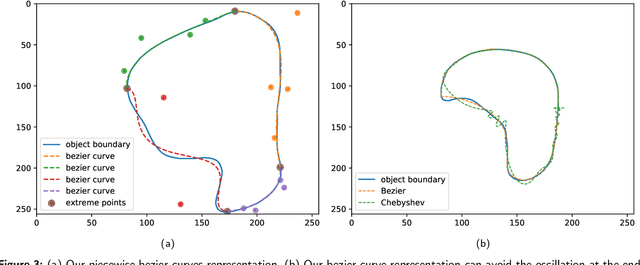
Delineating the lesion area is an important task in image-based diagnosis. Pixel-wise classification is a popular approach to segmenting the region of interest. However, at fuzzy boundaries such methods usually result in glitches, discontinuity, or disconnection, inconsistent with the fact that lesions are solid and smooth. To overcome these undesirable artifacts, we propose the BezierSeg model which outputs bezier curves encompassing the region of interest. Directly modelling the contour with analytic equations ensures that the segmentation is connected, continuous, and the boundary is smooth. In addition, it offers sub-pixel accuracy. Without loss of accuracy, the bezier contour can be resampled and overlaid with images of any resolution. Moreover, a doctor can conveniently adjust the curve's control points to refine the result. Our experiments show that the proposed method runs in real time and achieves accuracy competitive with pixel-wise segmentation models.