 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
DrafterBench: Benchmarking Large Language Models for Tasks Automation in Civil Engineering
Jul 15, 2025Large Language Model (LLM) agents have shown great potential for solving real-world problems and promise to be a solution for tasks automation in industry. However, more benchmarks are needed to systematically evaluate automation agents from an industrial perspective, for example, in Civil Engineering. Therefore, we propose DrafterBench for the comprehensive evaluation of LLM agents in the context of technical drawing revision, a representation task in civil engineering. DrafterBench contains twelve types of tasks summarized from real-world drawing files, with 46 customized functions/tools and 1920 tasks in total. DrafterBench is an open-source benchmark to rigorously test AI agents' proficiency in interpreting intricate and long-context instructions, leveraging prior knowledge, and adapting to dynamic instruction quality via implicit policy awareness. The toolkit comprehensively assesses distinct capabilities in structured data comprehension, function execution, instruction following, and critical reasoning. DrafterBench offers detailed analysis of task accuracy and error statistics, aiming to provide deeper insight into agent capabilities and identify improvement targets for integrating LLMs in engineering applications. Our benchmark is available at https://github.com/Eason-Li-AIS/DrafterBench, with the test set hosted at https://huggingface.co/datasets/Eason666/DrafterBench.
Infinigen-Sim: Procedural Generation of Articulated Simulation Assets
May 19, 2025

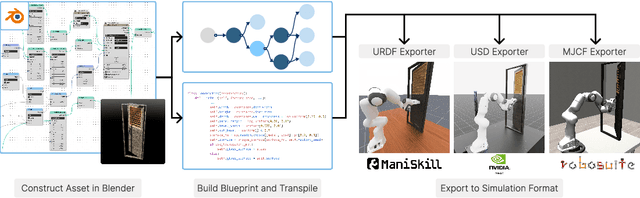
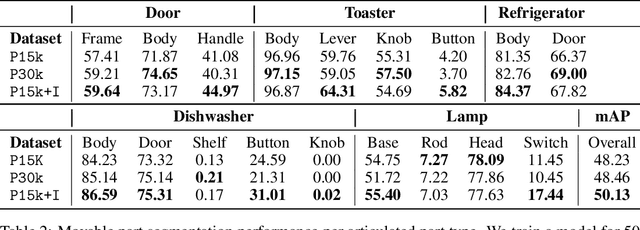
We introduce Infinigen-Sim, a toolkit which enables users to create diverse and realistic articulated object procedural generators. These tools are composed of high-level utilities for use creating articulated assets in Blender, as well as an export pipeline to integrate the resulting assets into common robotics simulators. We demonstrate our system by creating procedural generators for 5 common articulated object categories. Experiments show that assets sampled from these generators are useful for movable object segmentation, training generalizable reinforcement learning policies, and sim-to-real transfer of imitation learning policies.
Multimodal Inverse Attention Network with Intrinsic Discriminant Feature Exploitation for Fake News Detection
Feb 03, 2025



Multimodal fake news detection has garnered significant attention due to its profound implications for social security. While existing approaches have contributed to understanding cross-modal consistency, they often fail to leverage modal-specific representations and explicit discrepant features. To address these limitations, we propose a Multimodal Inverse Attention Network (MIAN), a novel framework that explores intrinsic discriminative features based on news content to advance fake news detection. Specifically, MIAN introduces a hierarchical learning module that captures diverse intra-modal relationships through local-to-global and local-to-local interactions, thereby generating enhanced unimodal representations to improve the identification of fake news at the intra-modal level. Additionally, a cross-modal interaction module employs a co-attention mechanism to establish and model dependencies between the refined unimodal representations, facilitating seamless semantic integration across modalities. To explicitly extract inconsistency features, we propose an inverse attention mechanism that effectively highlights the conflicting patterns and semantic deviations introduced by fake news in both intra- and inter-modality. Extensive experiments on benchmark datasets demonstrate that MIAN significantly outperforms state-of-the-art methods, underscoring its pivotal contribution to advancing social security through enhanced multimodal fake news detection.
Molecular Odor Prediction with Harmonic Modulated Feature Mapping and Chemically-Informed Loss
Feb 03, 2025



Molecular odor prediction has great potential across diverse fields such as chemistry, pharmaceuticals, and environmental science, enabling the rapid design of new materials and enhancing environmental monitoring. However, current methods face two main challenges: First, existing models struggle with non-smooth objective functions and the complexity of mixed feature dimensions; Second, datasets suffer from severe label imbalance, which hampers model training, particularly in learning minority class labels. To address these issues, we introduce a novel feature mapping method and a molecular ensemble optimization loss function. By incorporating feature importance learning and frequency modulation, our model adaptively adjusts the contribution of each feature, efficiently capturing the intricate relationship between molecular structures and odor descriptors. Our feature mapping preserves feature independence while enhancing the model's efficiency in utilizing molecular features through frequency modulation. Furthermore, the proposed loss function dynamically adjusts label weights, improves structural consistency, and strengthens label correlations, effectively addressing data imbalance and label co-occurrence challenges. Experimental results show that our method significantly can improves the accuracy of molecular odor prediction across various deep learning models, demonstrating its promising potential in molecular structure representation and chemoinformatics.
Molecular Odor Prediction Based on Multi-Feature Graph Attention Networks
Feb 03, 2025



Olfactory perception plays a critical role in both human and organismal interactions, yet understanding of its underlying mechanisms and influencing factors remain insufficient. Molecular structures influence odor perception through intricate biochemical interactions, and accurately quantifying structure-odor relationships presents significant challenges. The Quantitative Structure-Odor Relationship (QSOR) task, which involves predicting the associations between molecular structures and their corresponding odors, seeks to address these challenges. To this end, we propose a method for QSOR, utilizing Graph Attention Networks to model molecular structures and capture both local and global features. Unlike conventional QSOR approaches reliant on predefined descriptors, our method leverages diverse molecular feature extraction techniques to automatically learn comprehensive representations. This integration enhances the model's capacity to handle complex molecular information, improves prediction accuracy. Our approach demonstrates clear advantages in QSOR prediction tasks, offering valuable insights into the application of deep learning in cheminformatics.
Ophtha-LLaMA2: A Large Language Model for Ophthalmology
Dec 08, 2023



In recent years, pre-trained large language models (LLMs) have achieved tremendous success in the field of Natural Language Processing (NLP). Prior studies have primarily focused on general and generic domains, with relatively less research on specialized LLMs in the medical field. The specialization and high accuracy requirements for diagnosis in the medical field, as well as the challenges in collecting large-scale data, have constrained the application and development of LLMs in medical scenarios. In the field of ophthalmology, clinical diagnosis mainly relies on doctors' interpretation of reports and making diagnostic decisions. In order to take advantage of LLMs to provide decision support for doctors, we collected three modalities of ophthalmic report data and fine-tuned the LLaMA2 model, successfully constructing an LLM termed the "Ophtha-LLaMA2" specifically tailored for ophthalmic disease diagnosis. Inference test results show that even with a smaller fine-tuning dataset, Ophtha-LLaMA2 performs significantly better in ophthalmic diagnosis compared to other LLMs. It demonstrates that the Ophtha-LLaMA2 exhibits satisfying accuracy and efficiency in ophthalmic disease diagnosis, making it a valuable tool for ophthalmologists to provide improved diagnostic support for patients. This research provides a useful reference for the application of LLMs in the field of ophthalmology, while showcasing the immense potential and prospects in this domain.
Evaluating Large Language Models in Ophthalmology
Nov 07, 2023Purpose: The performance of three different large language models (LLMS) (GPT-3.5, GPT-4, and PaLM2) in answering ophthalmology professional questions was evaluated and compared with that of three different professional populations (medical undergraduates, medical masters, and attending physicians). Methods: A 100-item ophthalmology single-choice test was administered to three different LLMs (GPT-3.5, GPT-4, and PaLM2) and three different professional levels (medical undergraduates, medical masters, and attending physicians), respectively. The performance of LLM was comprehensively evaluated and compared with the human group in terms of average score, stability, and confidence. Results: Each LLM outperformed undergraduates in general, with GPT-3.5 and PaLM2 being slightly below the master's level, while GPT-4 showed a level comparable to that of attending physicians. In addition, GPT-4 showed significantly higher answer stability and confidence than GPT-3.5 and PaLM2. Conclusion: Our study shows that LLM represented by GPT-4 performs better in the field of ophthalmology. With further improvements, LLM will bring unexpected benefits in medical education and clinical decision making in the near future.
Evaluating multiple large language models in pediatric ophthalmology
Nov 07, 2023



IMPORTANCE The response effectiveness of different large language models (LLMs) and various individuals, including medical students, graduate students, and practicing physicians, in pediatric ophthalmology consultations, has not been clearly established yet. OBJECTIVE Design a 100-question exam based on pediatric ophthalmology to evaluate the performance of LLMs in highly specialized scenarios and compare them with the performance of medical students and physicians at different levels. DESIGN, SETTING, AND PARTICIPANTS This survey study assessed three LLMs, namely ChatGPT (GPT-3.5), GPT-4, and PaLM2, were assessed alongside three human cohorts: medical students, postgraduate students, and attending physicians, in their ability to answer questions related to pediatric ophthalmology. It was conducted by administering questionnaires in the form of test papers through the LLM network interface, with the valuable participation of volunteers. MAIN OUTCOMES AND MEASURES Mean scores of LLM and humans on 100 multiple-choice questions, as well as the answer stability, correlation, and response confidence of each LLM. RESULTS GPT-4 performed comparably to attending physicians, while ChatGPT (GPT-3.5) and PaLM2 outperformed medical students but slightly trailed behind postgraduate students. Furthermore, GPT-4 exhibited greater stability and confidence when responding to inquiries compared to ChatGPT (GPT-3.5) and PaLM2. CONCLUSIONS AND RELEVANCE Our results underscore the potential for LLMs to provide medical assistance in pediatric ophthalmology and suggest significant capacity to guide the education of medical students.