 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Learning Hierarchical Orthogonal Prototypes for Generalized Few-Shot 3D Point Cloud Segmentation
Mar 20, 2026Generalized few-shot 3D point cloud segmentation aims to adapt to novel classes from only a few annotations while maintaining strong performance on base classes, but this remains challenging due to the inherent stability-plasticity trade-off: adapting to novel classes can interfere with shared representations and cause base-class forgetting. We present HOP3D, a unified framework that learns hierarchical orthogonal prototypes with an entropy-based few-shot regularizer to enable robust novel-class adaptation without degrading base-class performance. HOP3D introduces hierarchical orthogonalization that decouples base and novel learning at both the gradient and representation levels, effectively mitigating base-novel interference. To further enhance adaptation under sparse supervision, we incorporate an entropy-based regularizer that leverages predictive uncertainty to refine prototype learning and promote balanced predictions. Extensive experiments on ScanNet200 and ScanNet++ demonstrate that HOP3D consistently outperforms state-of-the-art baselines under both 1-shot and 5-shot settings. The code is available at https://fdueblab-hop3d.github.io/.
Uncertainty-aware Prototype Learning with Variational Inference for Few-shot Point Cloud Segmentation
Mar 20, 2026Few-shot 3D semantic segmentation aims to generate accurate semantic masks for query point clouds with only a few annotated support examples. Existing prototype-based methods typically construct compact and deterministic prototypes from the support set to guide query segmentation. However, such rigid representations are unable to capture the intrinsic uncertainty introduced by scarce supervision, which often results in degraded robustness and limited generalization. In this work, we propose UPL (Uncertainty-aware Prototype Learning), a probabilistic approach designed to incorporate uncertainty modeling into prototype learning for few-shot 3D segmentation. Our framework introduces two key components. First, UPL introduces a dual-stream prototype refinement module that enriches prototype representations by jointly leveraging limited information from both support and query samples. Second, we formulate prototype learning as a variational inference problem, regarding class prototypes as latent variables. This probabilistic formulation enables explicit uncertainty modeling, providing robust and interpretable mask predictions. Extensive experiments on the widely used ScanNet and S3DIS benchmarks show that our UPL achieves consistent state-of-the-art performance under different settings while providing reliable uncertainty estimation. The code is available at https://fdueblab-upl.github.io/.
DrafterBench: Benchmarking Large Language Models for Tasks Automation in Civil Engineering
Jul 15, 2025Large Language Model (LLM) agents have shown great potential for solving real-world problems and promise to be a solution for tasks automation in industry. However, more benchmarks are needed to systematically evaluate automation agents from an industrial perspective, for example, in Civil Engineering. Therefore, we propose DrafterBench for the comprehensive evaluation of LLM agents in the context of technical drawing revision, a representation task in civil engineering. DrafterBench contains twelve types of tasks summarized from real-world drawing files, with 46 customized functions/tools and 1920 tasks in total. DrafterBench is an open-source benchmark to rigorously test AI agents' proficiency in interpreting intricate and long-context instructions, leveraging prior knowledge, and adapting to dynamic instruction quality via implicit policy awareness. The toolkit comprehensively assesses distinct capabilities in structured data comprehension, function execution, instruction following, and critical reasoning. DrafterBench offers detailed analysis of task accuracy and error statistics, aiming to provide deeper insight into agent capabilities and identify improvement targets for integrating LLMs in engineering applications. Our benchmark is available at https://github.com/Eason-Li-AIS/DrafterBench, with the test set hosted at https://huggingface.co/datasets/Eason666/DrafterBench.
SWDL: Stratum-Wise Difference Learning with Deep Laplacian Pyramid for Semi-Supervised 3D Intracranial Hemorrhage Segmentation
Jun 12, 2025Recent advances in medical imaging have established deep learning-based segmentation as the predominant approach, though it typically requires large amounts of manually annotated data. However, obtaining annotations for intracranial hemorrhage (ICH) remains particularly challenging due to the tedious and costly labeling process. Semi-supervised learning (SSL) has emerged as a promising solution to address the scarcity of labeled data, especially in volumetric medical image segmentation. Unlike conventional SSL methods that primarily focus on high-confidence pseudo-labels or consistency regularization, we propose SWDL-Net, a novel SSL framework that exploits the complementary advantages of Laplacian pyramid and deep convolutional upsampling. The Laplacian pyramid excels at edge sharpening, while deep convolutions enhance detail precision through flexible feature mapping. Our framework achieves superior segmentation of lesion details and boundaries through a difference learning mechanism that effectively integrates these complementary approaches. Extensive experiments on a 271-case ICH dataset and public benchmarks demonstrate that SWDL-Net outperforms current state-of-the-art methods in scenarios with only 2% labeled data. Additional evaluations on the publicly available Brain Hemorrhage Segmentation Dataset (BHSD) with 5% labeled data further confirm the superiority of our approach. Code and data have been released at https://github.com/SIAT-CT-LAB/SWDL.
Reconstructing Quantitative Cerebral Perfusion Images Directly From Measured Sinogram Data Acquired Using C-arm Cone-Beam CT
Dec 06, 2024



To shorten the door-to-puncture time for better treating patients with acute ischemic stroke, it is highly desired to obtain quantitative cerebral perfusion images using C-arm cone-beam computed tomography (CBCT) equipped in the interventional suite. However, limited by the slow gantry rotation speed, the temporal resolution and temporal sampling density of typical C-arm CBCT are much poorer than those of multi-detector-row CT in the diagnostic imaging suite. The current quantitative perfusion imaging includes two cascaded steps: time-resolved image reconstruction and perfusion parametric estimation. For time-resolved image reconstruction, the technical challenge imposed by poor temporal resolution and poor sampling density causes inaccurate quantification of the temporal variation of cerebral artery and tissue attenuation values. For perfusion parametric estimation, it remains a technical challenge to appropriately design the handcrafted regularization for better solving the associated deconvolution problem. These two challenges together prevent obtaining quantitatively accurate perfusion images using C-arm CBCT. The purpose of this work is to simultaneously address these two challenges by combining the two cascaded steps into a single joint optimization problem and reconstructing quantitative perfusion images directly from the measured sinogram data. In the developed direct cerebral perfusion parametric image reconstruction technique, TRAINER in short, the quantitative perfusion images have been represented as a subject-specific conditional generative model trained under the constraint of the time-resolved CT forward model, perfusion convolutional model, and the subject's own measured sinogram data. Results shown in this paper demonstrated that using TRAINER, quantitative cerebral perfusion images can be accurately obtained using C-arm CBCT in the interventional suite.
Sequential-Scanning Dual-Energy CT Imaging Using High Temporal Resolution Image Reconstruction and Error-Compensated Material Basis Image Generation
Aug 27, 2024



Dual-energy computed tomography (DECT) has been widely used to obtain quantitative elemental composition of imaged subjects for personalized and precise medical diagnosis. Compared with DECT leveraging advanced X-ray source and/or detector technologies, the use of the sequential-scanning data acquisition scheme to implement DECT may make a broader impact on clinical practice because this scheme requires no specialized hardware designs and can be directly implemented into conventional CT systems. However, since the concentration of iodinated contrast agent in the imaged subject varies over time, sequentially scanned data sets acquired at two tube potentials are temporally inconsistent. As existing material basis image reconstruction approaches assume that the data sets acquired at two tube potentials are temporally consistent, the violation of this assumption results in inaccurate quantification of material concentration. In this work, we developed sequential-scanning DECT imaging using high temporal resolution image reconstruction and error-compensated material basis image generation, ACCELERATION in short, to address the technical challenge induced by temporal inconsistency of sequentially scanned data sets and improve quantification accuracy of material concentration in sequential-scanning DECT. ACCELERATION has been validated and evaluated using numerical simulation data sets generated from clinical human subject exams and experimental human subject studies. Results demonstrated the improvement of quantification accuracy and image quality using ACCELERATION.
ACCELERATION: Sequentially-scanning DECT Imaging Using High Temporal Resolution Image Reconstruction And Temporal Extrapolation
Aug 12, 2024Dual-energy computed tomography (DECT) has been widely used to obtain quantitative elemental composition of imaged subjects for personalized and precise medical diagnosis. Compared with existing high-end DECT leveraging advanced X-ray source and/or detector technologies, the use of the sequentially-scanning data acquisition scheme to implement DECT may make broader impact on clinical practice because this scheme requires no specialized hardware designs. However, since the concentration of iodinated contrast agent in the imaged subject varies over time, sequentially-scanned data sets acquired at two tube potentials are temporally inconsistent. As existing material decomposition approaches for DECT assume that the data sets acquired at two tube potentials are temporally consistent, the violation of this assumption results in inaccurate quantification accuracy of iodine concentration. In this work, we developed a technique to achieve sequentially-scanning DECT imaging using high temporal resolution image reconstruction and temporal extrapolation, ACCELERATION in short, to address the technical challenge induced by temporal inconsistency of sequentially-scanned data sets and improve iodine quantification accuracy in sequentially-scanning DECT. ACCELERATION has been validated and evaluated using numerical simulation data sets generated from clinical human subject exams. Results demonstrated the improvement of iodine quantification accuracy using ACCELERATION.
RetinexFlow for CT metal artifact reduction
Jun 18, 2023



Metal artifacts is a major challenge in computed tomography (CT) imaging, significantly degrading image quality and making accurate diagnosis difficult. However, previous methods either require prior knowledge of the location of metal implants, or have modeling deviations with the mechanism of artifact formation, which limits the ability to obtain high-quality CT images. In this work, we formulate metal artifacts reduction problem as a combination of decomposition and completion tasks. And we propose RetinexFlow, which is a novel end-to-end image domain model based on Retinex theory and conditional normalizing flow, to solve it. Specifically, we first design a feature decomposition encoder for decomposing the metal implant component and inherent component, and extracting the inherent feature. Then, it uses a feature-to-image flow module to complete the metal artifact-free CT image step by step through a series of invertible transformations. These designs are incorporated in our model with a coarse-to-fine strategy, enabling it to achieve superior performance. The experimental results on on simulation and clinical datasets show our method achieves better quantitative and qualitative results, exhibiting better visual performance in artifact removal and image fidelity
Deep Learning Angiography (DLA): Three-dimensional C-arm Cone Beam CT Angiography Using Deep Learning
Jan 26, 2018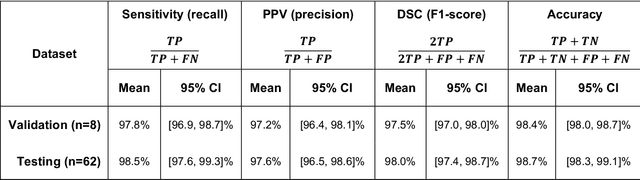
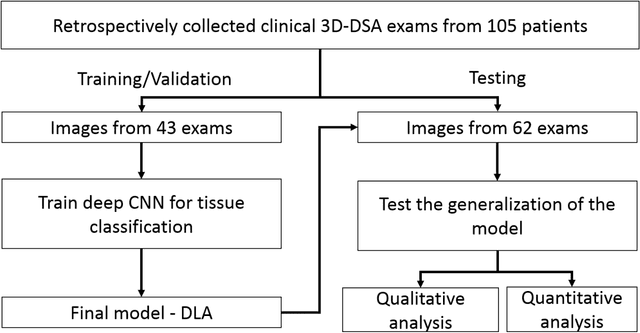
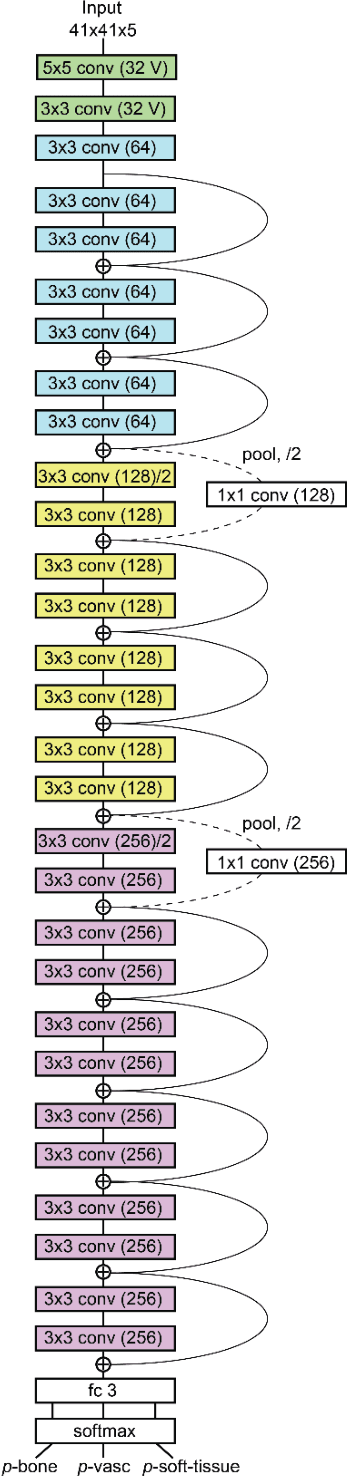
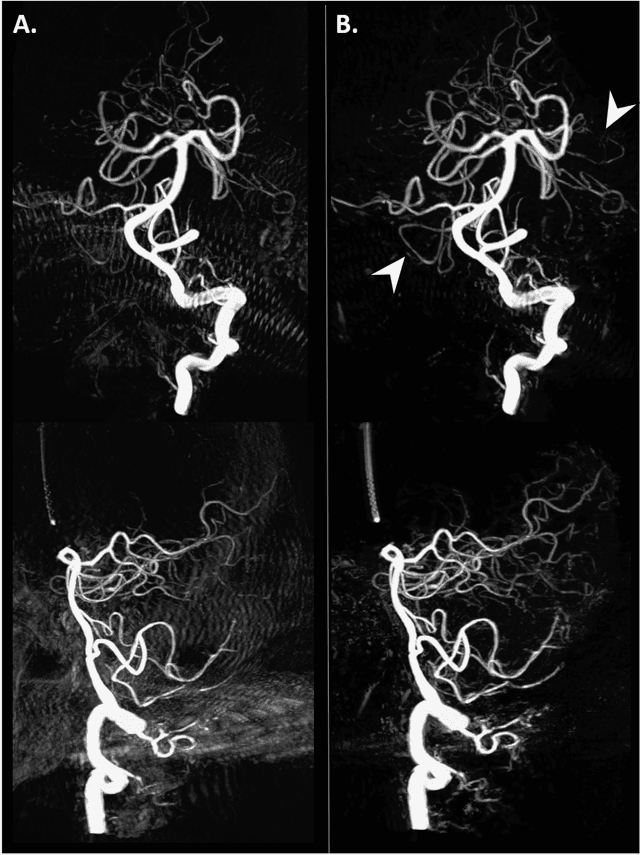
Background and Purpose: Our purpose was to develop a deep learning angiography (DLA) method to generate 3D cerebral angiograms from a single contrast-enhanced acquisition. Material and Methods: Under an approved IRB protocol 105 3D-DSA exams were randomly selected from an internal database. All were acquired using a clinical system (Axiom Artis zee, Siemens Healthineers) in conjunction with a standard injection protocol. More than 150 million labeled voxels from 35 subjects were used for training. A deep convolutional neural network was trained to classify each image voxel into three tissue types (vasculature, bone and soft tissue). The trained DLA model was then applied for tissue classification in a validation cohort of 8 subjects and a final testing cohort consisting of the remaining 62 subjects. The final vasculature tissue class was used to generate the 3D-DLA images. To quantify the generalization error of the trained model, accuracy, sensitivity, precision and F1-scores were calculated for vasculature classification in relevant anatomy. The 3D-DLA and clinical 3D-DSA images were subject to a qualitative assessment for the presence of inter-sweep motion artifacts. Results: Vasculature classification accuracy and 95% CI in the testing dataset was 98.7% ([98.3, 99.1] %). No residual signal from osseous structures was observed for all 3D-DLA testing cases except for small regions in the otic capsule and nasal cavity compared to 37% (23/62) of the 3D-DSAs. Conclusion: DLA accurately recreated the vascular anatomy of the 3D-DSA reconstructions without mask. DLA reduced mis-registration artifacts induced by inter-sweep motion. DLA reduces radiation exposure required to obtain clinically useful 3D-DSA