 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSci: A Memory-Centric Agentic System for the Full Scientific Research Lifecycle
May 29, 2026Scientific research has traditionally been human-intensive, requiring researchers to coordinate literature, ideas, experiments, manuscripts, and review responses across long project cycles. The rise of LLM-based scientific agents creates an opportunity to automate this process. Such a system must support the full research lifecycle, maintain structured persistent memory across projects, and improve its own research procedures over time. However, existing systems either partially satisfy or fail to satisfy these requirements, leaving a gap for a unified automated scientific research system. As a result, we present AutoSci, a memory-centric agentic system for the full scientific research lifecycle. AutoSci is organized around four modules. SciMem provides schema-governed research memory, separating Long-Term Knowledge Memory for reusable scientific knowledge from Active Research Memory for project-level artifacts such as ideas, experiments, manuscripts, and reviews. SciFlow executes a five-stage lifecycle from literature understanding to rebuttal through a harness that controls state, context, verification, feedback, and orchestration. SciDAG augments difficult skills with DAG-shaped multi-agent operators and reusable stage-specific templates. SciEvolve converts feedback signals from users, experiments, reviews, and external environments into versioned updates to SciMem organization, SciFlow skills, and SciDAG templates. Together, these modules make AutoSci a persistent research environment that can execute, remember, and evolve across research projects. The code repository is available at https://github.com/skyllwt/AutoSci.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Baichuan Alignment Technical Report
Oct 19, 2024



We introduce Baichuan Alignment, a detailed analysis of the alignment techniques employed in the Baichuan series of models. This represents the industry's first comprehensive account of alignment methodologies, offering valuable insights for advancing AI research. We investigate the critical components that enhance model performance during the alignment process, including optimization methods, data strategies, capability enhancements, and evaluation processes. The process spans three key stages: Prompt Augmentation System (PAS), Supervised Fine-Tuning (SFT), and Preference Alignment. The problems encountered, the solutions applied, and the improvements made are thoroughly recorded. Through comparisons across well-established benchmarks, we highlight the technological advancements enabled by Baichuan Alignment. Baichuan-Instruct is an internal model, while Qwen2-Nova-72B and Llama3-PBM-Nova-70B are instruct versions of the Qwen2-72B and Llama-3-70B base models, optimized through Baichuan Alignment. Baichuan-Instruct demonstrates significant improvements in core capabilities, with user experience gains ranging from 17% to 28%, and performs exceptionally well on specialized benchmarks. In open-source benchmark evaluations, both Qwen2-Nova-72B and Llama3-PBM-Nova-70B consistently outperform their respective official instruct versions across nearly all datasets. This report aims to clarify the key technologies behind the alignment process, fostering a deeper understanding within the community. Llama3-PBM-Nova-70B model is available at https://huggingface.co/PKU-Baichuan-MLSystemLab/Llama3-PBM-Nova-70B.
SysBench: Can Large Language Models Follow System Messages?
Aug 20, 2024



Large Language Models (LLMs) have become instrumental across various applications, with the customization of these models to specific scenarios becoming increasingly critical. System message, a fundamental component of LLMs, is consist of carefully crafted instructions that guide the behavior of model to meet intended goals. Despite the recognized potential of system messages to optimize AI-driven solutions, there is a notable absence of a comprehensive benchmark for evaluating how well different LLMs follow these system messages. To fill this gap, we introduce SysBench, a benchmark that systematically analyzes system message following ability in terms of three challenging aspects: constraint complexity, instruction misalignment and multi-turn stability. In order to enable effective evaluation, SysBench constructs multi-turn user conversations covering various interaction relationships, based on six common types of constraints from system messages in real-world scenarios. Our dataset contains 500 system messages from various domains, each paired with 5 turns of user conversations, which have been manually formulated and checked to guarantee high quality. SysBench provides extensive evaluation across various LLMs, measuring their ability to follow specified constraints given in system messages. The results highlight both the strengths and weaknesses of existing models, offering key insights and directions for future research. The open source library SysBench is available at https://github.com/PKU-Baichuan-MLSystemLab/SysBench.
When Emotional Stimuli meet Prompt Designing: An Auto-Prompt Graphical Paradigm
Apr 16, 2024



With the development of Large Language Models (LLM), numerous prompts have been proposed, each with a rich set of features and their own merits. This paper summarizes the prompt words for large language models (LLMs), categorizing them into stimulating and framework types, and proposes an Auto-Prompt Graphical Paradigm(APGP) that combines both stimulating and framework prompts to enhance the problem-solving capabilities of LLMs across multiple domains, then exemplifies it with a framework that adheres to this paradigm. The framework involves automated prompt generation and consideration of emotion-stimulus factors, guiding LLMs in problem abstraction, diversified solutions generation, comprehensive optimization, and self-verification after providing answers, ensuring solution accuracy. Compared to traditional stimuli and framework prompts, this framework integrates the advantages of both by adopting automated approaches inspired by APE work, overcoming the limitations of manually designed prompts. Test results on the ruozhiba and BBH datasets demonstrate that this framework can effectively improve the efficiency and accuracy of LLMs in problem-solving, paving the way for new applications of LLMs.
Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation
Sep 15, 2021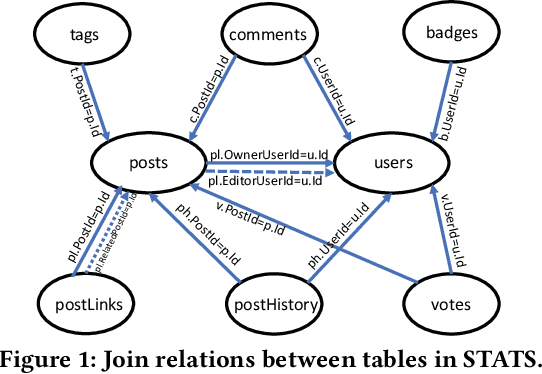
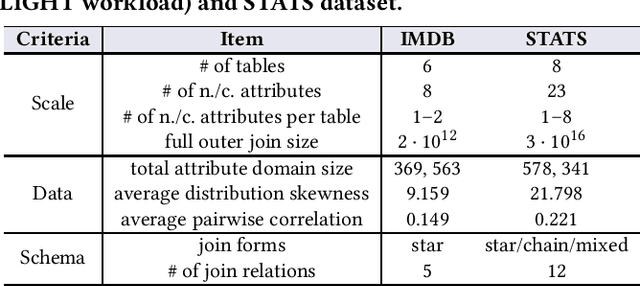
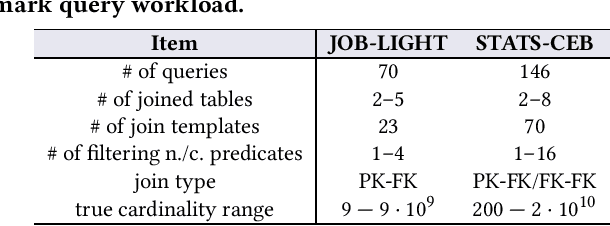
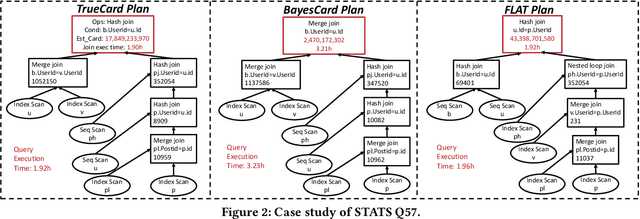
Cardinality estimation (CardEst) plays a significant role in generating high-quality query plans for a query optimizer in DBMS. In the last decade, an increasing number of advanced CardEst methods (especially ML-based) have been proposed with outstanding estimation accuracy and inference latency. However, there exists no study that systematically evaluates the quality of these methods and answer the fundamental problem: to what extent can these methods improve the performance of query optimizer in real-world settings, which is the ultimate goal of a CardEst method. In this paper, we comprehensively and systematically compare the effectiveness of CardEst methods in a real DBMS. We establish a new benchmark for CardEst, which contains a new complex real-world dataset STATS and a diverse query workload STATS-CEB. We integrate multiple most representative CardEst methods into an open-source database system PostgreSQL, and comprehensively evaluate their true effectiveness in improving query plan quality, and other important aspects affecting their applicability, ranging from inference latency, model size, and training time, to update efficiency and accuracy. We obtain a number of key findings for the CardEst methods, under different data and query settings. Furthermore, we find that the widely used estimation accuracy metric(Q-Error) cannot distinguish the importance of different sub-plan queries during query optimization and thus cannot truly reflect the query plan quality generated by CardEst methods. Therefore, we propose a new metric P-Error to evaluate the performance of CardEst methods, which overcomes the limitation of Q-Error and is able to reflect the overall end-to-end performance of CardEst methods. We have made all of the benchmark data and evaluation code publicly available at https://github.com/Nathaniel-Han/End-to-End-CardEst-Benchmark.