 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoL: A Comparative Regularization Loss over Query Reformulation Losses for Pseudo-Relevance Feedback
Apr 25, 2022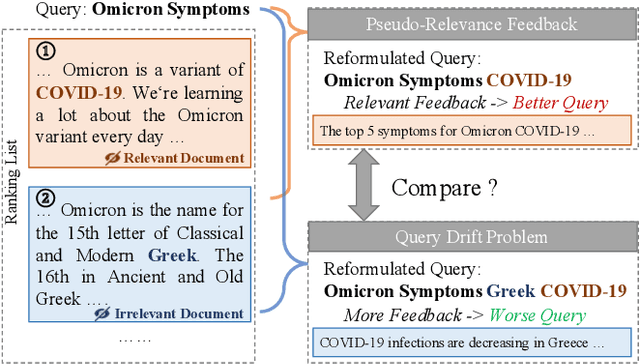
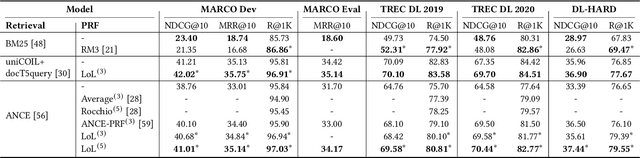
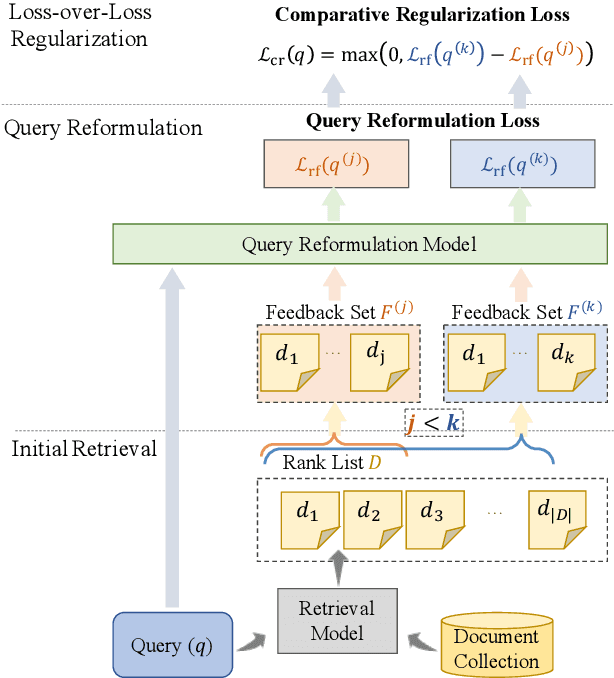
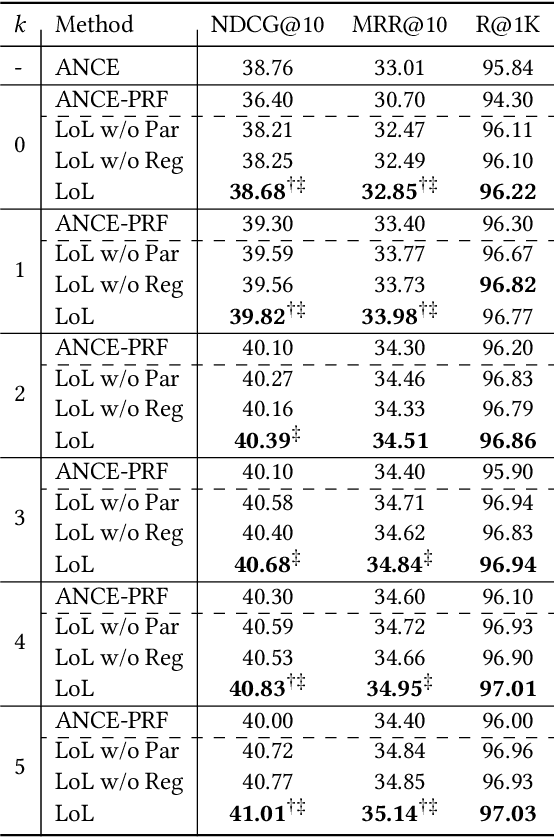
Pseudo-relevance feedback (PRF) has proven to be an effective query reformulation technique to improve retrieval accuracy. It aims to alleviate the mismatch of linguistic expressions between a query and its potential relevant documents. Existing PRF methods independently treat revised queries originating from the same query but using different numbers of feedback documents, resulting in severe query drift. Without comparing the effects of two different revisions from the same query, a PRF model may incorrectly focus on the additional irrelevant information increased in the more feedback, and thus reformulate a query that is less effective than the revision using the less feedback. Ideally, if a PRF model can distinguish between irrelevant and relevant information in the feedback, the more feedback documents there are, the better the revised query will be. To bridge this gap, we propose the Loss-over-Loss (LoL) framework to compare the reformulation losses between different revisions of the same query during training. Concretely, we revise an original query multiple times in parallel using different amounts of feedback and compute their reformulation losses. Then, we introduce an additional regularization loss on these reformulation losses to penalize revisions that use more feedback but gain larger losses. With such comparative regularization, the PRF model is expected to learn to suppress the extra increased irrelevant information by comparing the effects of different revised queries. Further, we present a differentiable query reformulation method to implement this framework. This method revises queries in the vector space and directly optimizes the retrieval performance of query vectors, applicable for both sparse and dense retrieval models. Empirical evaluation demonstrates the effectiveness and robustness of our method for two typical sparse and dense retrieval models.
Uncertainty Calibration for Ensemble-Based Debiasing Methods
Nov 07, 2021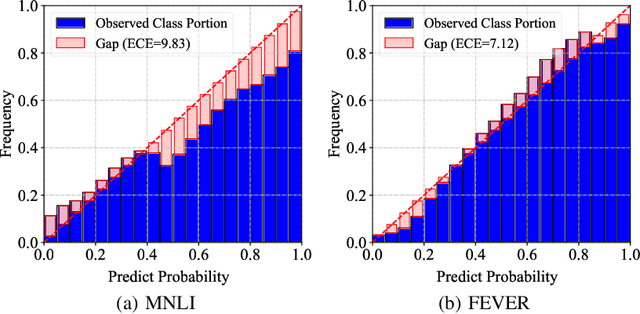
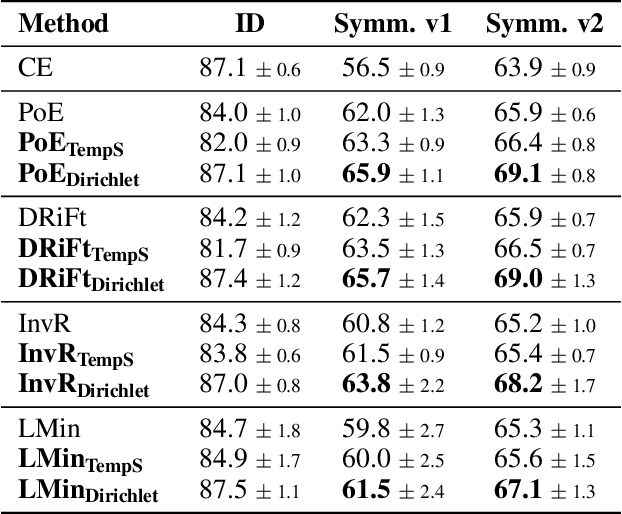
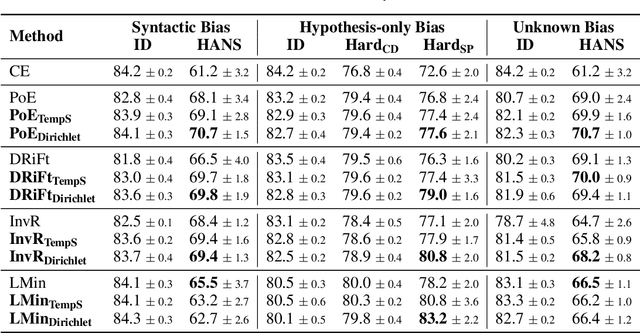
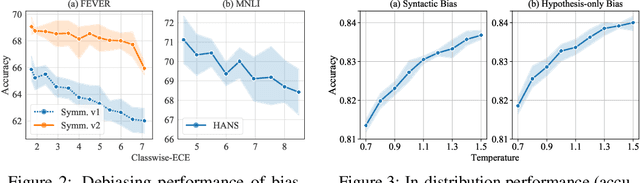
Ensemble-based debiasing methods have been shown effective in mitigating the reliance of classifiers on specific dataset bias, by exploiting the output of a bias-only model to adjust the learning target. In this paper, we focus on the bias-only model in these ensemble-based methods, which plays an important role but has not gained much attention in the existing literature. Theoretically, we prove that the debiasing performance can be damaged by inaccurate uncertainty estimations of the bias-only model. Empirically, we show that existing bias-only models fall short in producing accurate uncertainty estimations. Motivated by these findings, we propose to conduct calibration on the bias-only model, thus achieving a three-stage ensemble-based debiasing framework, including bias modeling, model calibrating, and debiasing. Experimental results on NLI and fact verification tasks show that our proposed three-stage debiasing framework consistently outperforms the traditional two-stage one in out-of-distribution accuracy.
Multi-modal Self-supervised Pre-training for Regulatory Genome Across Cell Types
Nov 03, 2021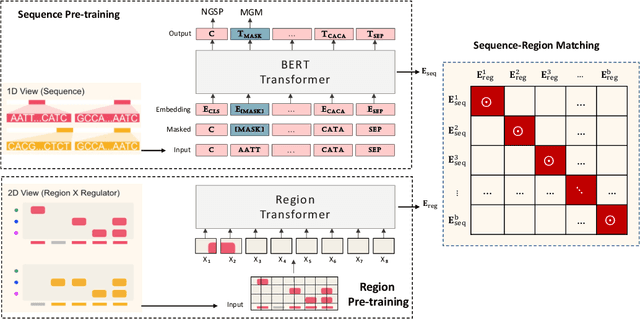

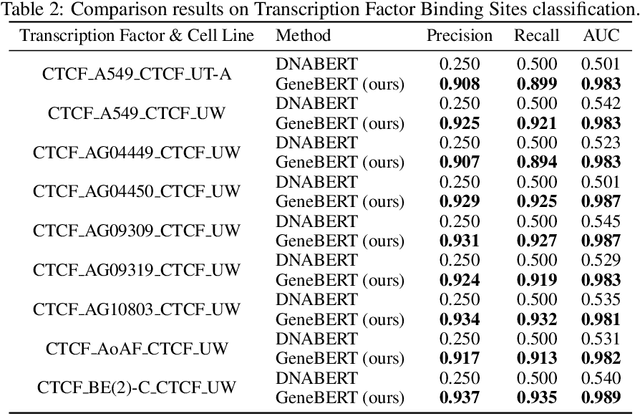
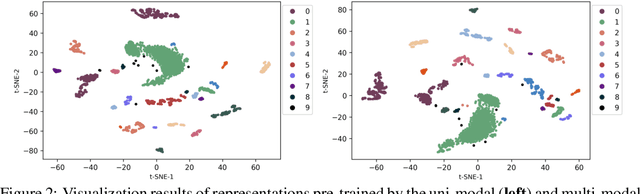
In the genome biology research, regulatory genome modeling is an important topic for many regulatory downstream tasks, such as promoter classification, transaction factor binding sites prediction. The core problem is to model how regulatory elements interact with each other and its variability across different cell types. However, current deep learning methods often focus on modeling genome sequences of a fixed set of cell types and do not account for the interaction between multiple regulatory elements, making them only perform well on the cell types in the training set and lack the generalizability required in biological applications. In this work, we propose a simple yet effective approach for pre-training genome data in a multi-modal and self-supervised manner, which we call GeneBERT. Specifically, we simultaneously take the 1d sequence of genome data and a 2d matrix of (transcription factors x regions) as the input, where three pre-training tasks are proposed to improve the robustness and generalizability of our model. We pre-train our model on the ATAC-seq dataset with 17 million genome sequences. We evaluate our GeneBERT on regulatory downstream tasks across different cell types, including promoter classification, transaction factor binding sites prediction, disease risk estimation, and splicing sites prediction. Extensive experiments demonstrate the effectiveness of multi-modal and self-supervised pre-training for large-scale regulatory genomics data.
Adaptive Bridge between Training and Inference for Dialogue
Oct 22, 2021
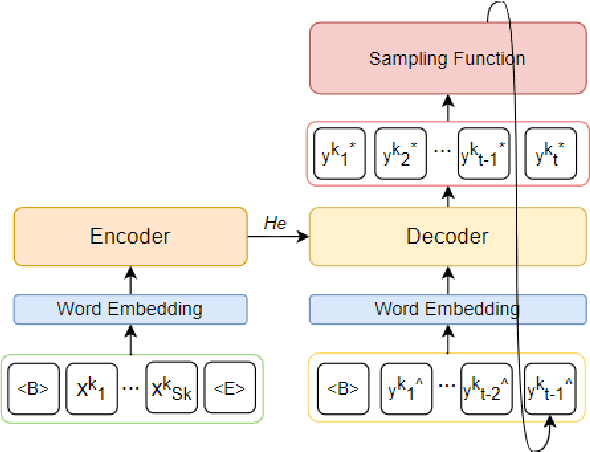
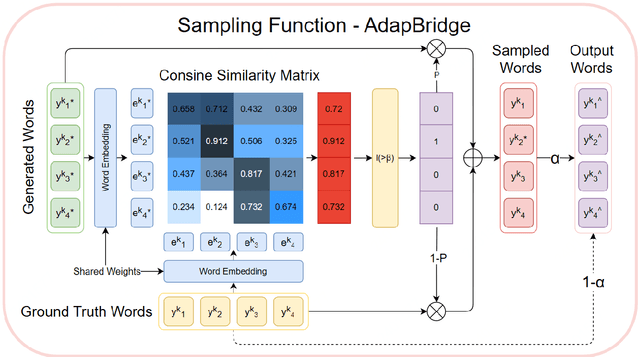
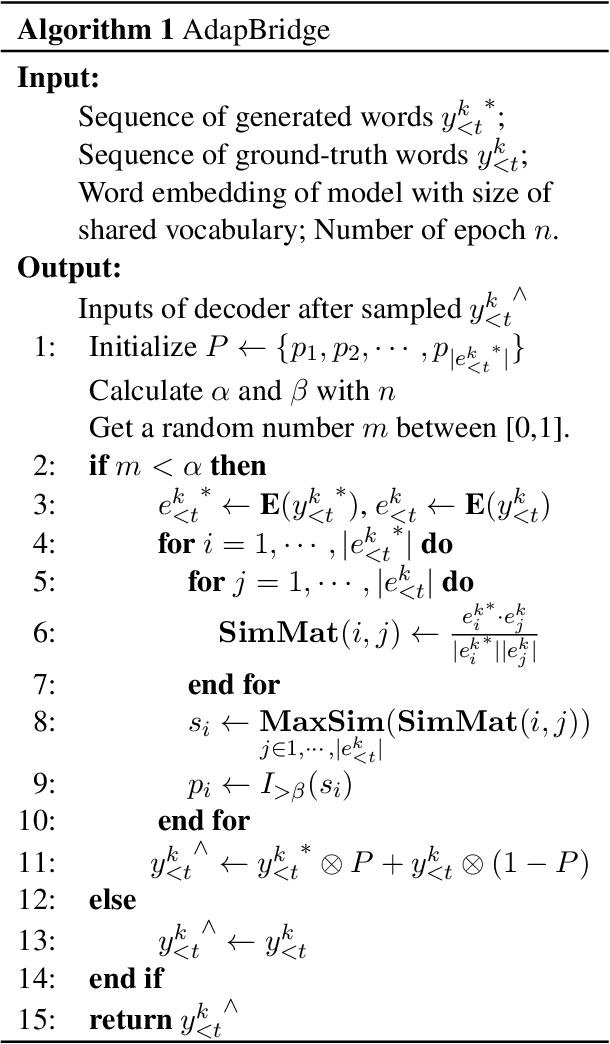
Although exposure bias has been widely studied in some NLP tasks, it faces its unique challenges in dialogue response generation, the representative one-to-various generation scenario. In real human dialogue, there are many appropriate responses for the same context, not only with different expressions, but also with different topics. Therefore, due to the much bigger gap between various ground-truth responses and the generated synthetic response, exposure bias is more challenging in dialogue generation task. What's more, as MLE encourages the model to only learn the common words among different ground-truth responses, but ignores the interesting and specific parts, exposure bias may further lead to the common response generation problem, such as "I don't know" and "HaHa?" In this paper, we propose a novel adaptive switching mechanism, which learns to automatically transit between ground-truth learning and generated learning regarding the word-level matching score, such as the cosine similarity. Experimental results on both Chinese STC dataset and English Reddit dataset, show that our adaptive method achieves a significant improvement in terms of metric-based evaluation and human evaluation, as compared with the state-of-the-art exposure bias approaches. Further analysis on NMT task also shows that our model can achieve a significant improvement.
FCM: A Fine-grained Comparison Model for Multi-turn Dialogue Reasoning
Sep 23, 2021
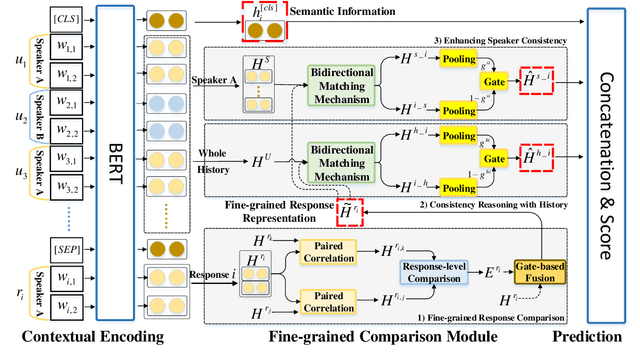
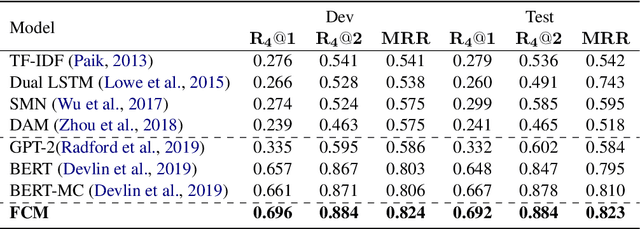
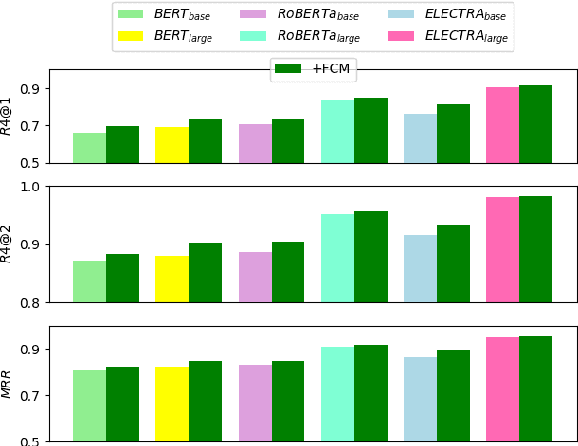
Despite the success of neural dialogue systems in achieving high performance on the leader-board, they cannot meet users' requirements in practice, due to their poor reasoning skills. The underlying reason is that most neural dialogue models only capture the syntactic and semantic information, but fail to model the logical consistency between the dialogue history and the generated response. Recently, a new multi-turn dialogue reasoning task has been proposed, to facilitate dialogue reasoning research. However, this task is challenging, because there are only slight differences between the illogical response and the dialogue history. How to effectively solve this challenge is still worth exploring. This paper proposes a Fine-grained Comparison Model (FCM) to tackle this problem. Inspired by human's behavior in reading comprehension, a comparison mechanism is proposed to focus on the fine-grained differences in the representation of each response candidate. Specifically, each candidate representation is compared with the whole history to obtain a history consistency representation. Furthermore, the consistency signals between each candidate and the speaker's own history are considered to drive a model to prefer a candidate that is logically consistent with the speaker's history logic. Finally, the above consistency representations are employed to output a ranking list of the candidate responses for multi-turn dialogue reasoning. Experimental results on two public dialogue datasets show that our method obtains higher ranking scores than the baseline models.
Transductive Learning for Unsupervised Text Style Transfer
Sep 16, 2021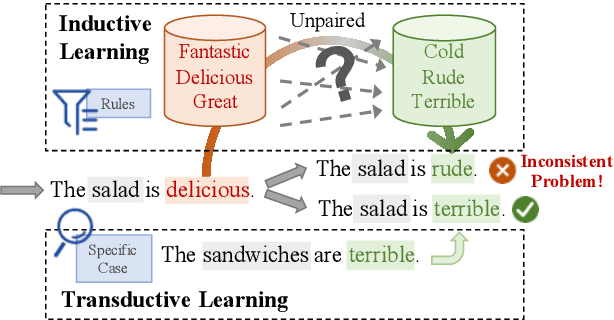
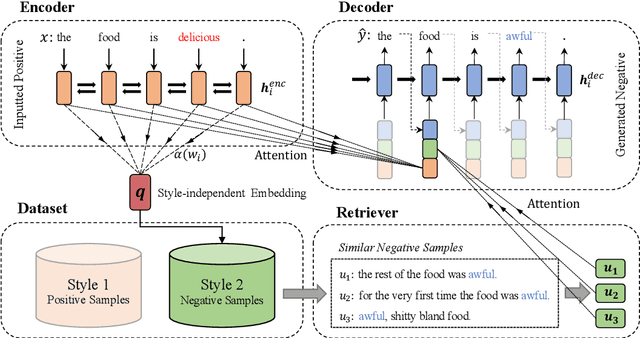
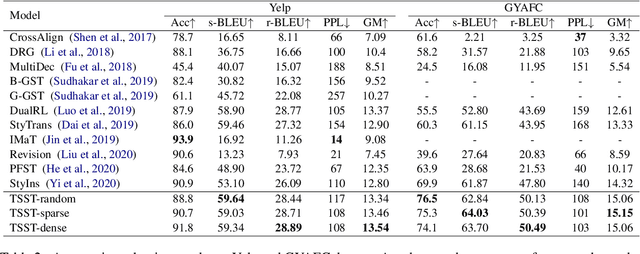
Unsupervised style transfer models are mainly based on an inductive learning approach, which represents the style as embeddings, decoder parameters, or discriminator parameters and directly applies these general rules to the test cases. However, the lacking of parallel corpus hinders the ability of these inductive learning methods on this task. As a result, it is likely to cause severe inconsistent style expressions, like `the salad is rude`. To tackle this problem, we propose a novel transductive learning approach in this paper, based on a retrieval-based context-aware style representation. Specifically, an attentional encoder-decoder with a retriever framework is utilized. It involves top-K relevant sentences in the target style in the transfer process. In this way, we can learn a context-aware style embedding to alleviate the above inconsistency problem. In this paper, both sparse (BM25) and dense retrieval functions (MIPS) are used, and two objective functions are designed to facilitate joint learning. Experimental results show that our method outperforms several strong baselines. The proposed transductive learning approach is general and effective to the task of unsupervised style transfer, and we will apply it to the other two typical methods in the future.
Adaptive Information Seeking for Open-Domain Question Answering
Sep 14, 2021
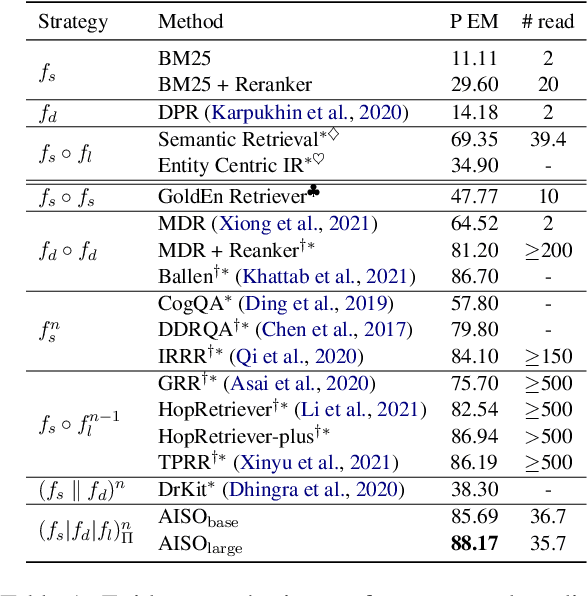
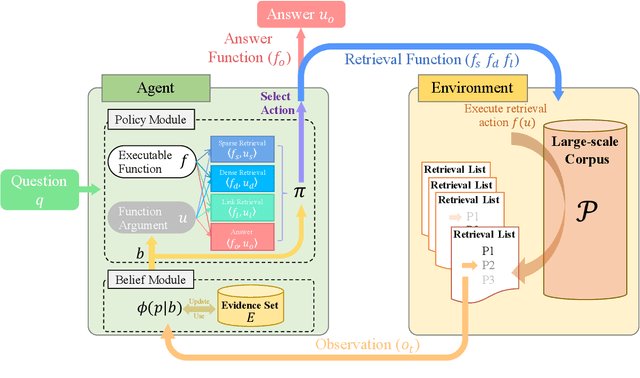
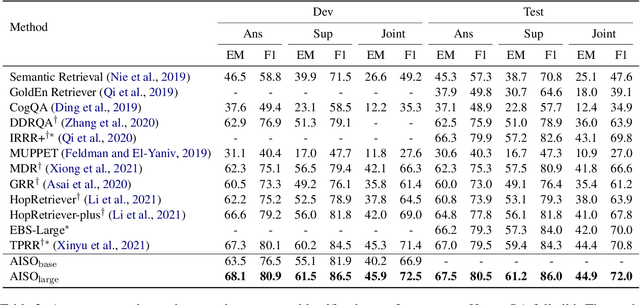
Information seeking is an essential step for open-domain question answering to efficiently gather evidence from a large corpus. Recently, iterative approaches have been proven to be effective for complex questions, by recursively retrieving new evidence at each step. However, almost all existing iterative approaches use predefined strategies, either applying the same retrieval function multiple times or fixing the order of different retrieval functions, which cannot fulfill the diverse requirements of various questions. In this paper, we propose a novel adaptive information-seeking strategy for open-domain question answering, namely AISO. Specifically, the whole retrieval and answer process is modeled as a partially observed Markov decision process, where three types of retrieval operations (e.g., BM25, DPR, and hyperlink) and one answer operation are defined as actions. According to the learned policy, AISO could adaptively select a proper retrieval action to seek the missing evidence at each step, based on the collected evidence and the reformulated query, or directly output the answer when the evidence set is sufficient for the question. Experiments on SQuAD Open and HotpotQA fullwiki, which serve as single-hop and multi-hop open-domain QA benchmarks, show that AISO outperforms all baseline methods with predefined strategies in terms of both retrieval and answer evaluations.
Toward the Understanding of Deep Text Matching Models for Information Retrieval
Aug 16, 2021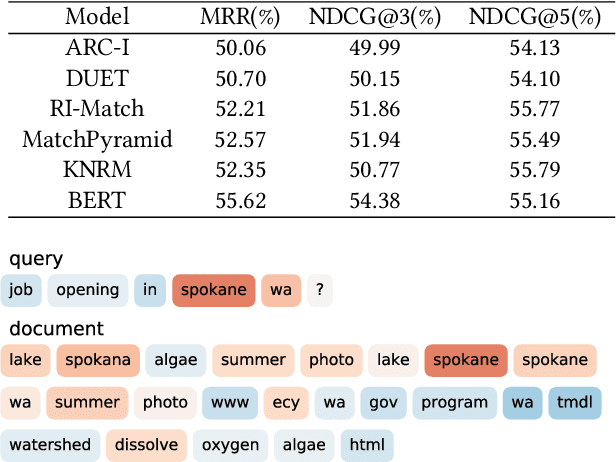
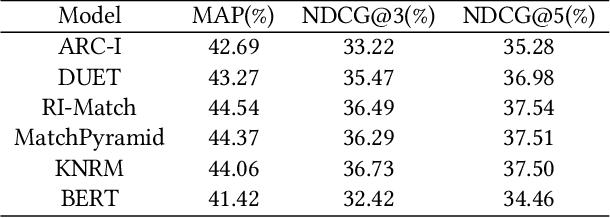

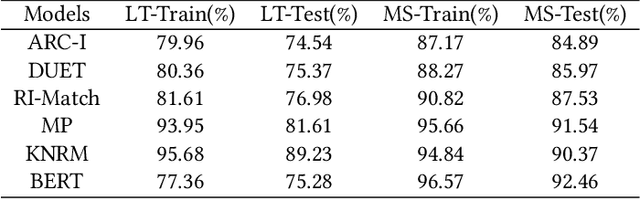
Semantic text matching is a critical problem in information retrieval. Recently, deep learning techniques have been widely used in this area and obtained significant performance improvements. However, most models are black boxes and it is hard to understand what happened in the matching process, due to the poor interpretability of deep learning. This paper aims at tackling this problem. The key idea is to test whether existing deep text matching methods satisfy some fundamental heuristics in information retrieval. Specifically, four heuristics are used in our study, i.e., term frequency constraint, term discrimination constraint, length normalization constraints, and TF-length constraint. Since deep matching models usually contain many parameters, it is difficult to conduct a theoretical study for these complicated functions. In this paper, We propose an empirical testing method. Specifically, We first construct some queries and documents to make them satisfy the assumption in a constraint, and then test to which extend a deep text matching model trained on the original dataset satisfies the corresponding constraint. Besides, a famous attribution based interpretation method, namely integrated gradient, is adopted to conduct detailed analysis and guide for feasible improvement. Experimental results on LETOR 4.0 and MS Marco show that all the investigated deep text matching methods, both representation and interaction based methods, satisfy the above constraints with high probabilities in statistics. We further extend these constraints to the semantic settings, which are shown to be better satisfied for all the deep text matching models. These empirical findings give clear understandings on why deep text matching models usually perform well in information retrieval. We believe the proposed evaluation methodology will be useful for testing future deep text matching models.
A Discriminative Semantic Ranker for Question Retrieval
Jul 18, 2021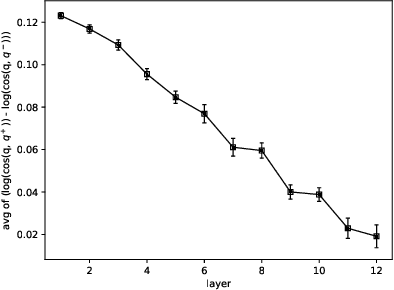

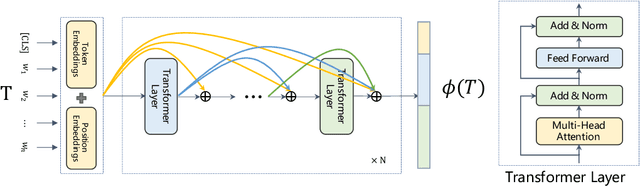
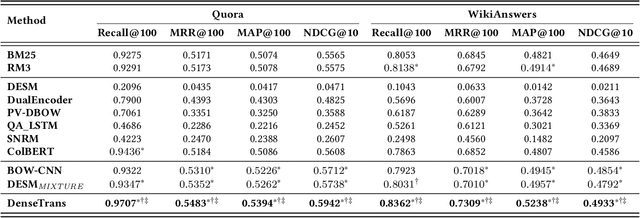
Similar question retrieval is a core task in community-based question answering (CQA) services. To balance the effectiveness and efficiency, the question retrieval system is typically implemented as multi-stage rankers: The first-stage ranker aims to recall potentially relevant questions from a large repository, and the latter stages attempt to re-rank the retrieved results. Most existing works on question retrieval mainly focused on the re-ranking stages, leaving the first-stage ranker to some traditional term-based methods. However, term-based methods often suffer from the vocabulary mismatch problem, especially on short texts, which may block the re-rankers from relevant questions at the very beginning. An alternative is to employ embedding-based methods for the first-stage ranker, which compress texts into dense vectors to enhance the semantic matching. However, these methods often lose the discriminative power as term-based methods, thus introduce noise during retrieval and hurt the recall performance. In this work, we aim to tackle the dilemma of the first-stage ranker, and propose a discriminative semantic ranker, namely DenseTrans, for high-recall retrieval. Specifically, DenseTrans is a densely connected Transformer, which learns semantic embeddings for texts based on Transformer layers. Meanwhile, DenseTrans promotes low-level features through dense connections to keep the discriminative power of the learned representations. DenseTrans is inspired by DenseNet in computer vision (CV), but poses a new way to use the dense connectivity which is totally different from its original design purpose. Experimental results over two question retrieval benchmark datasets show that our model can obtain significant gain on recall against strong term-based methods as well as state-of-the-art embedding-based methods.
Pre-Trained Models: Past, Present and Future
Jun 15, 2021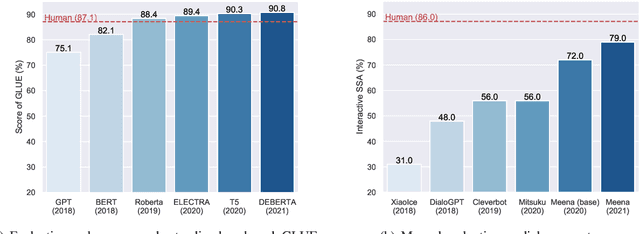
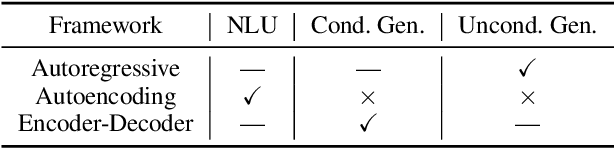
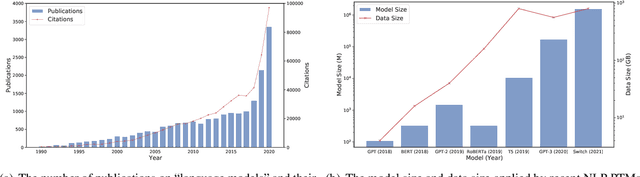
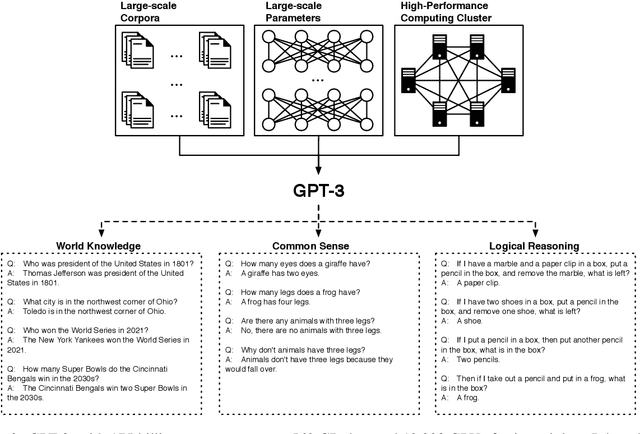
Large-scale pre-trained models (PTMs) such as BERT and GPT have recently achieved great success and become a milestone in the field of artificial intelligence (AI). Owing to sophisticated pre-training objectives and huge model parameters, large-scale PTMs can effectively capture knowledge from massive labeled and unlabeled data. By storing knowledge into huge parameters and fine-tuning on specific tasks, the rich knowledge implicitly encoded in huge parameters can benefit a variety of downstream tasks, which has been extensively demonstrated via experimental verification and empirical analysis. It is now the consensus of the AI community to adopt PTMs as backbone for downstream tasks rather than learning models from scratch. In this paper, we take a deep look into the history of pre-training, especially its special relation with transfer learning and self-supervised learning, to reveal the crucial position of PTMs in the AI development spectrum. Further, we comprehensively review the latest breakthroughs of PTMs. These breakthroughs are driven by the surge of computational power and the increasing availability of data, towards four important directions: designing effective architectures, utilizing rich contexts, improving computational efficiency, and conducting interpretation and theoretical analysis. Finally, we discuss a series of open problems and research directions of PTMs, and hope our view can inspire and advance the future study of PTMs.