 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-document Summarization with Maximal Marginal Relevance-guided Reinforcement Learning
Sep 30, 2020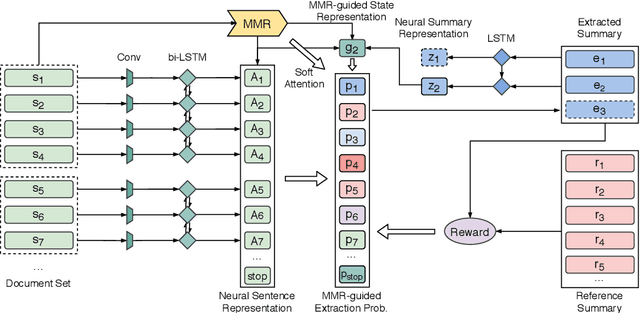
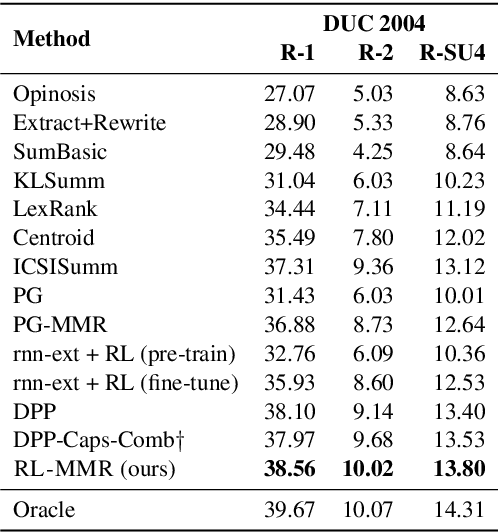
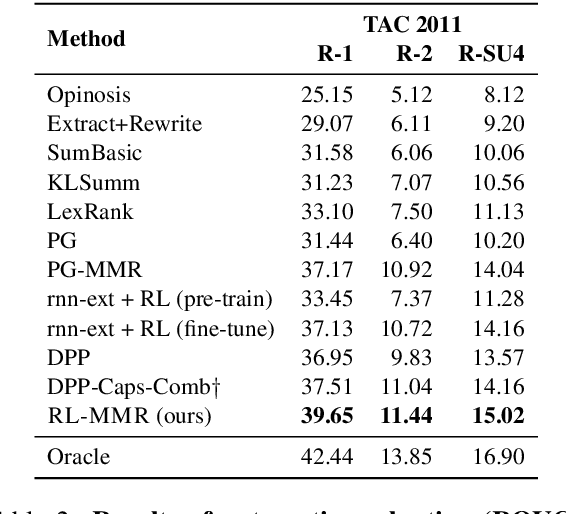
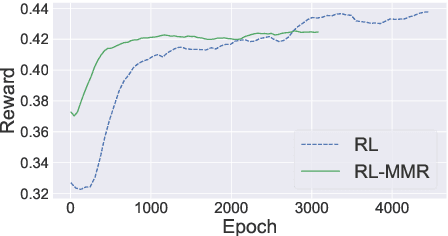
While neural sequence learning methods have made significant progress in single-document summarization (SDS), they produce unsatisfactory results on multi-document summarization (MDS). We observe two major challenges when adapting SDS advances to MDS: (1) MDS involves larger search space and yet more limited training data, setting obstacles for neural methods to learn adequate representations; (2) MDS needs to resolve higher information redundancy among the source documents, which SDS methods are less effective to handle. To close the gap, we present RL-MMR, Maximal Margin Relevance-guided Reinforcement Learning for MDS, which unifies advanced neural SDS methods and statistical measures used in classical MDS. RL-MMR casts MMR guidance on fewer promising candidates, which restrains the search space and thus leads to better representation learning. Additionally, the explicit redundancy measure in MMR helps the neural representation of the summary to better capture redundancy. Extensive experiments demonstrate that RL-MMR achieves state-of-the-art performance on benchmark MDS datasets. In particular, we show the benefits of incorporating MMR into end-to-end learning when adapting SDS to MDS in terms of both learning effectiveness and efficiency.
GIKT: A Graph-based Interaction Model for Knowledge Tracing
Sep 13, 2020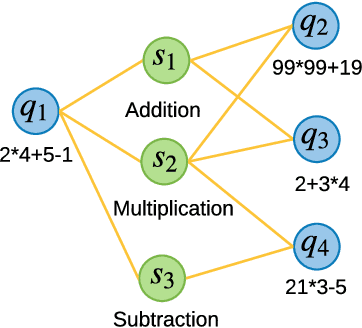
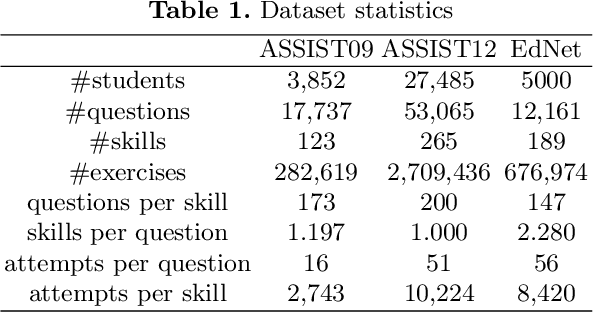
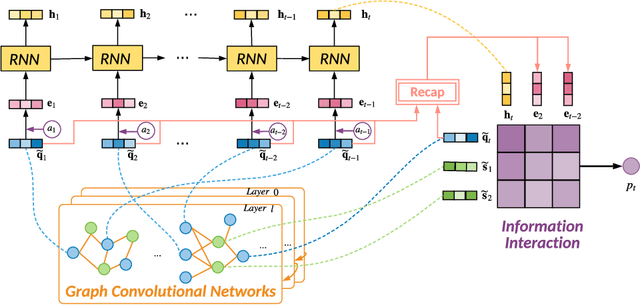
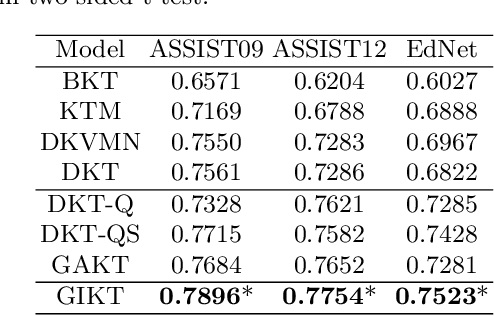
With the rapid development in online education, knowledge tracing (KT) has become a fundamental problem which traces students' knowledge status and predicts their performance on new questions. Questions are often numerous in online education systems, and are always associated with much fewer skills. However, the previous literature fails to involve question information together with high-order question-skill correlations, which is mostly limited by data sparsity and multi-skill problems. From the model perspective, previous models can hardly capture the long-term dependency of student exercise history, and cannot model the interactions between student-questions, and student-skills in a consistent way. In this paper, we propose a Graph-based Interaction model for Knowledge Tracing (GIKT) to tackle the above probems. More specifically, GIKT utilizes graph convolutional network (GCN) to substantially incorporate question-skill correlations via embedding propagation. Besides, considering that relevant questions are usually scattered throughout the exercise history, and that question and skill are just different instantiations of knowledge, GIKT generalizes the degree of students' master of the question to the interactions between the student's current state, the student's history related exercises, the target question, and related skills. Experiments on three datasets demonstrate that GIKT achieves the new state-of-the-art performance, with at least 1% absolute AUC improvement.
Dynamically Fused Graph Network for Multi-hop Reasoning
Jun 06, 2019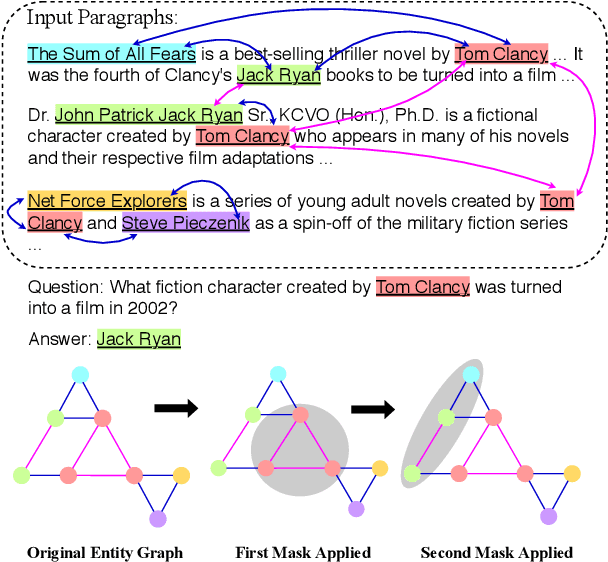
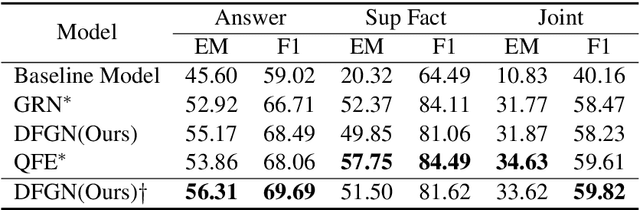

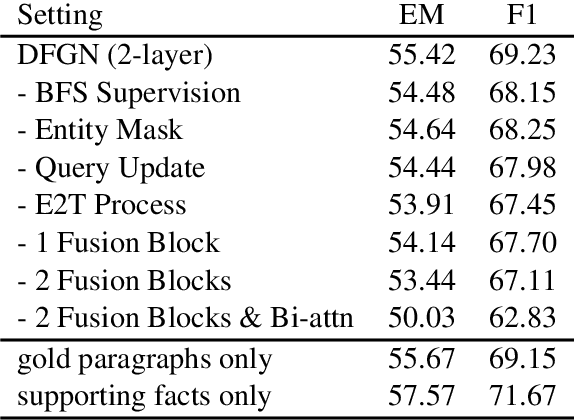
Text-based question answering (TBQA) has been studied extensively in recent years. Most existing approaches focus on finding the answer to a question within a single paragraph. However, many difficult questions require multiple supporting evidence from scattered text among two or more documents. In this paper, we propose Dynamically Fused Graph Network(DFGN), a novel method to answer those questions requiring multiple scattered evidence and reasoning over them. Inspired by human's step-by-step reasoning behavior, DFGN includes a dynamic fusion layer that starts from the entities mentioned in the given query, explores along the entity graph dynamically built from the text, and gradually finds relevant supporting entities from the given documents. We evaluate DFGN on HotpotQA, a public TBQA dataset requiring multi-hop reasoning. DFGN achieves competitive results on the public board. Furthermore, our analysis shows DFGN produces interpretable reasoning chains.
TGE-PS: Text-driven Graph Embedding with Pairs Sampling
Sep 12, 2018
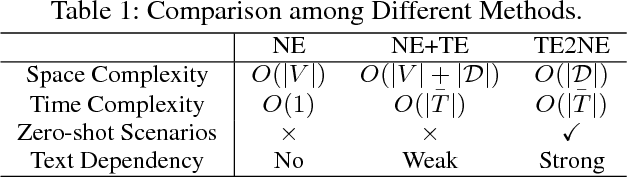
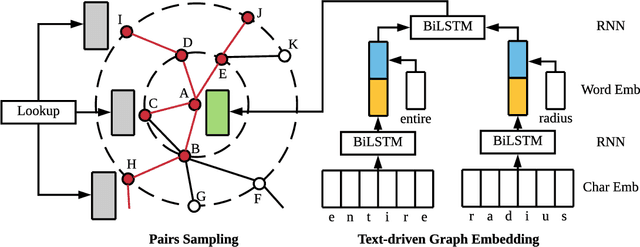
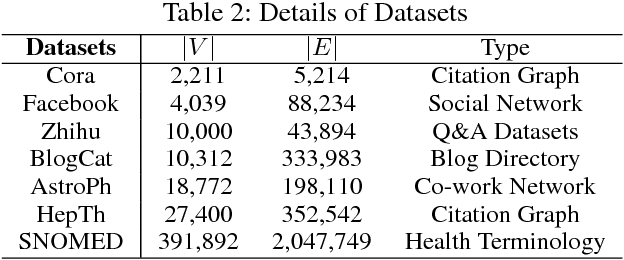
In graphs with rich text information, constructing expressive graph representations requires incorporating textual information with structural information. Graph embedding models are becoming more and more popular in representing graphs, yet they are faced with two issues: sampling efficiency and text utilization. Through analyzing existing models, we find their training objectives are composed of pairwise proximities, and there are large amounts of redundant node pairs in Random Walk-based methods. Besides, inferring graph structures directly from texts (also known as zero-shot scenario) is a problem that requires higher text utilization. To solve these problems, we propose a novel Text-driven Graph Embedding with Pairs Sampling (TGE-PS) framework. TGE-PS uses Pairs Sampling (PS) to generate training samples which reduces ~99% training samples and is competitive compared to Random Walk. TGE-PS uses Text-driven Graph Embedding (TGE) which adopts word- and character-level embeddings to generate node embeddings. We evaluate TGE-PS on several real-world datasets, and experimental results demonstrate that TGE-PS produces state-of-the-art results in traditional and zero-shot link prediction tasks.
Product-based Neural Networks for User Response Prediction over Multi-field Categorical Data
Jul 01, 2018

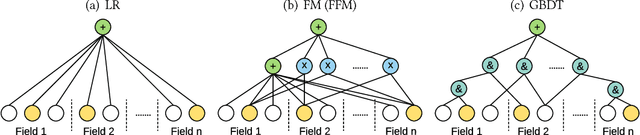
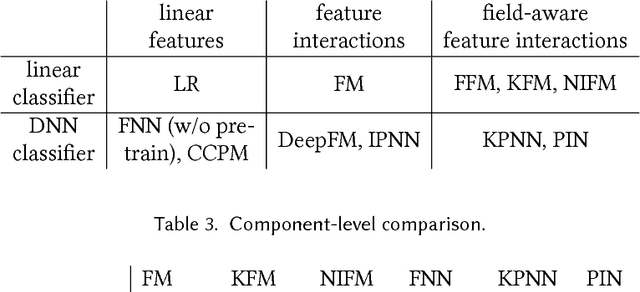
User response prediction is a crucial component for personalized information retrieval and filtering scenarios, such as recommender system and web search. The data in user response prediction is mostly in a multi-field categorical format and transformed into sparse representations via one-hot encoding. Due to the sparsity problems in representation and optimization, most research focuses on feature engineering and shallow modeling. Recently, deep neural networks have attracted research attention on such a problem for their high capacity and end-to-end training scheme. In this paper, we study user response prediction in the scenario of click prediction. We first analyze a coupled gradient issue in latent vector-based models and propose kernel product to learn field-aware feature interactions. Then we discuss an insensitive gradient issue in DNN-based models and propose Product-based Neural Network (PNN) which adopts a feature extractor to explore feature interactions. Generalizing the kernel product to a net-in-net architecture, we further propose Product-network In Network (PIN) which can generalize previous models. Extensive experiments on 4 industrial datasets and 1 contest dataset demonstrate that our models consistently outperform 8 baselines on both AUC and log loss. Besides, PIN makes great CTR improvement (relatively 34.67%) in online A/B test.
Label-aware Double Transfer Learning for Cross-Specialty Medical Named Entity Recognition
Apr 28, 2018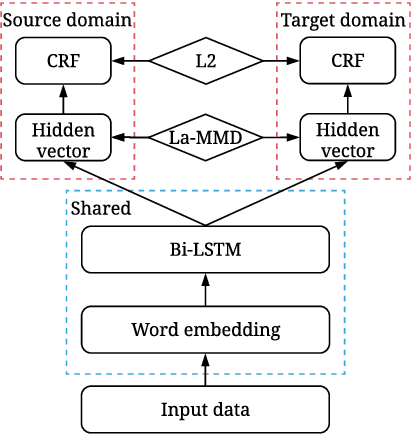
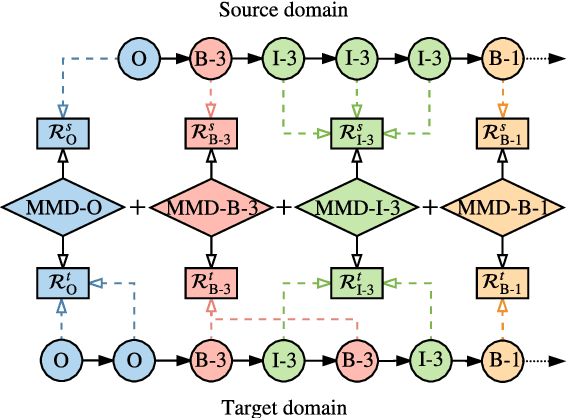
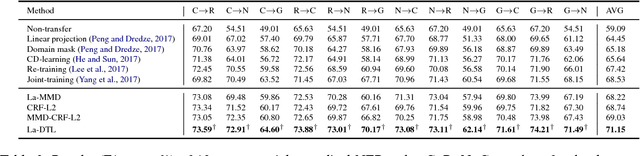
We study the problem of named entity recognition (NER) from electronic medical records, which is one of the most fundamental and critical problems for medical text mining. Medical records which are written by clinicians from different specialties usually contain quite different terminologies and writing styles. The difference of specialties and the cost of human annotation makes it particularly difficult to train a universal medical NER system. In this paper, we propose a label-aware double transfer learning framework (La-DTL) for cross-specialty NER, so that a medical NER system designed for one specialty could be conveniently applied to another one with minimal annotation efforts. The transferability is guaranteed by two components: (i) we propose label-aware MMD for feature representation transfer, and (ii) we perform parameter transfer with a theoretical upper bound which is also label aware. We conduct extensive experiments on 12 cross-specialty NER tasks. The experimental results demonstrate that La-DTL provides consistent accuracy improvement over strong baselines. Besides, the promising experimental results on non-medical NER scenarios indicate that La-DTL is potential to be seamlessly adapted to a wide range of NER tasks.
QA4IE: A Question Answering based Framework for Information Extraction
Apr 10, 2018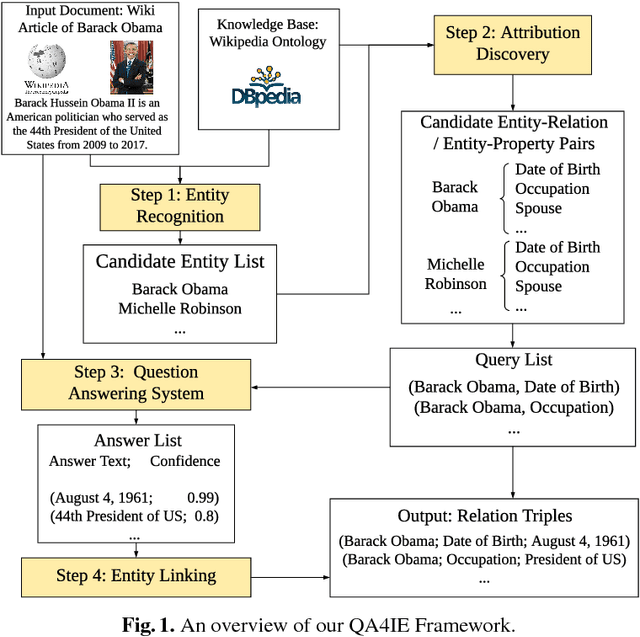
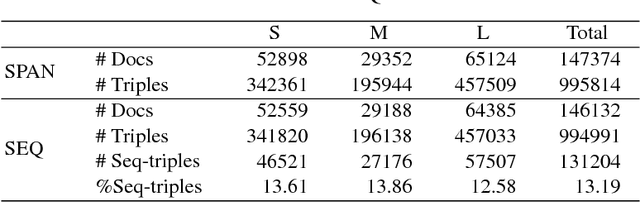
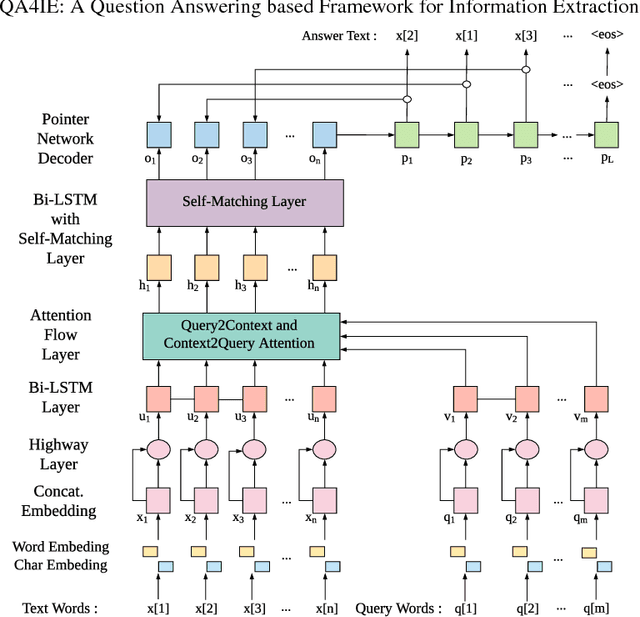
Information Extraction (IE) refers to automatically extracting structured relation tuples from unstructured texts. Common IE solutions, including Relation Extraction (RE) and open IE systems, can hardly handle cross-sentence tuples, and are severely restricted by limited relation types as well as informal relation specifications (e.g., free-text based relation tuples). In order to overcome these weaknesses, we propose a novel IE framework named QA4IE, which leverages the flexible question answering (QA) approaches to produce high quality relation triples across sentences. Based on the framework, we develop a large IE benchmark with high quality human evaluation. This benchmark contains 293K documents, 2M golden relation triples, and 636 relation types. We compare our system with some IE baselines on our benchmark and the results show that our system achieves great improvements.
Wasserstein Distance Guided Representation Learning for Domain Adaptation
Mar 09, 2018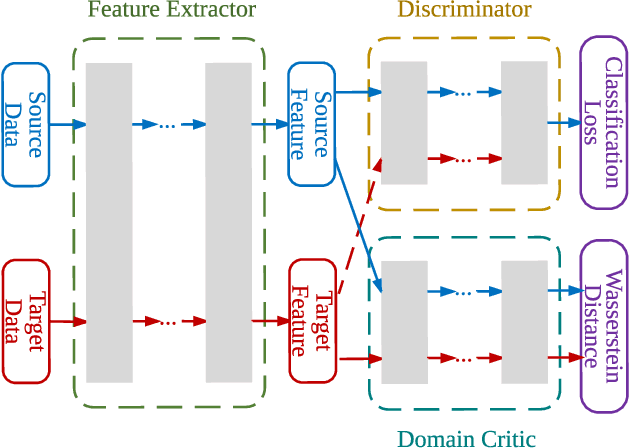
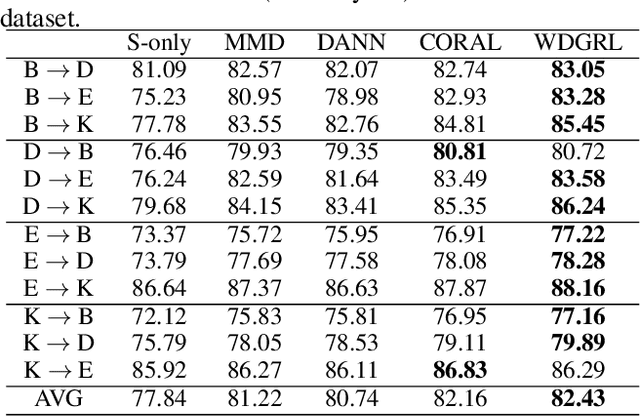
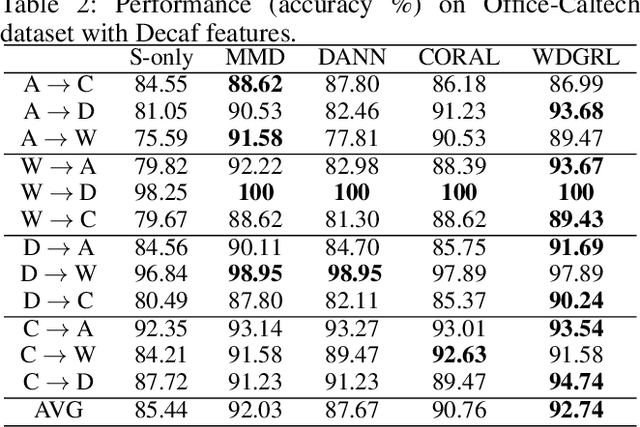
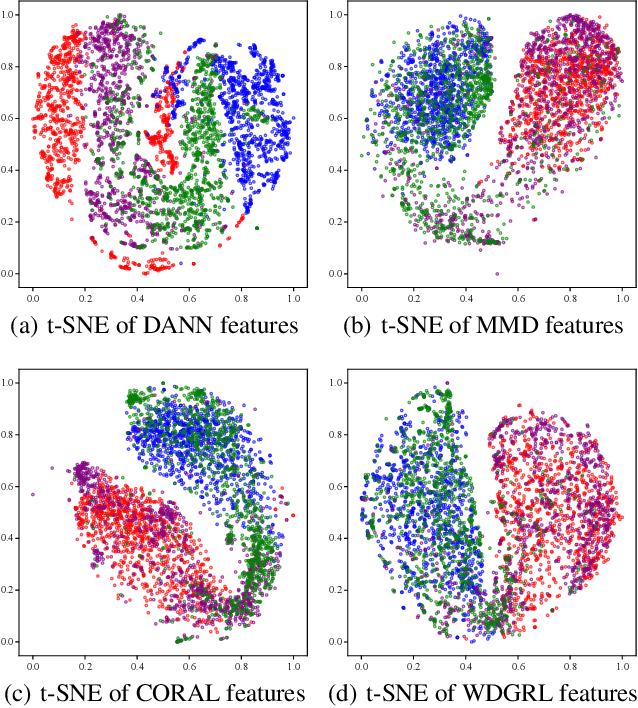
Domain adaptation aims at generalizing a high-performance learner on a target domain via utilizing the knowledge distilled from a source domain which has a different but related data distribution. One solution to domain adaptation is to learn domain invariant feature representations while the learned representations should also be discriminative in prediction. To learn such representations, domain adaptation frameworks usually include a domain invariant representation learning approach to measure and reduce the domain discrepancy, as well as a discriminator for classification. Inspired by Wasserstein GAN, in this paper we propose a novel approach to learn domain invariant feature representations, namely Wasserstein Distance Guided Representation Learning (WDGRL). WDGRL utilizes a neural network, denoted by the domain critic, to estimate empirical Wasserstein distance between the source and target samples and optimizes the feature extractor network to minimize the estimated Wasserstein distance in an adversarial manner. The theoretical advantages of Wasserstein distance for domain adaptation lie in its gradient property and promising generalization bound. Empirical studies on common sentiment and image classification adaptation datasets demonstrate that our proposed WDGRL outperforms the state-of-the-art domain invariant representation learning approaches.
Product-based Neural Networks for User Response Prediction
Nov 01, 2016Predicting user responses, such as clicks and conversions, is of great importance and has found its usage in many Web applications including recommender systems, web search and online advertising. The data in those applications is mostly categorical and contains multiple fields; a typical representation is to transform it into a high-dimensional sparse binary feature representation via one-hot encoding. Facing with the extreme sparsity, traditional models may limit their capacity of mining shallow patterns from the data, i.e. low-order feature combinations. Deep models like deep neural networks, on the other hand, cannot be directly applied for the high-dimensional input because of the huge feature space. In this paper, we propose a Product-based Neural Networks (PNN) with an embedding layer to learn a distributed representation of the categorical data, a product layer to capture interactive patterns between inter-field categories, and further fully connected layers to explore high-order feature interactions. Our experimental results on two large-scale real-world ad click datasets demonstrate that PNNs consistently outperform the state-of-the-art models on various metrics.