 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Modifying Data Address Graph Domain Adaptation?
Jul 27, 2024



Graph neural networks (GNNs) have demonstrated remarkable success in numerous graph analytical tasks. Yet, their effectiveness is often compromised in real-world scenarios due to distribution shifts, limiting their capacity for knowledge transfer across changing environments or domains. Recently, Unsupervised Graph Domain Adaptation (UGDA) has been introduced to resolve this issue. UGDA aims to facilitate knowledge transfer from a labeled source graph to an unlabeled target graph. Current UGDA efforts primarily focus on model-centric methods, such as employing domain invariant learning strategies and designing model architectures. However, our critical examination reveals the limitations inherent to these model-centric methods, while a data-centric method allowed to modify the source graph provably demonstrates considerable potential. This insight motivates us to explore UGDA from a data-centric perspective. By revisiting the theoretical generalization bound for UGDA, we identify two data-centric principles for UGDA: alignment principle and rescaling principle. Guided by these principles, we propose GraphAlign, a novel UGDA method that generates a small yet transferable graph. By exclusively training a GNN on this new graph with classic Empirical Risk Minimization (ERM), GraphAlign attains exceptional performance on the target graph. Extensive experiments under various transfer scenarios demonstrate the GraphAlign outperforms the best baselines by an average of 2.16%, training on the generated graph as small as 0.25~1% of the original training graph.
Unveiling Privacy Vulnerabilities: Investigating the Role of Structure in Graph Data
Jul 26, 2024



The public sharing of user information opens the door for adversaries to infer private data, leading to privacy breaches and facilitating malicious activities. While numerous studies have concentrated on privacy leakage via public user attributes, the threats associated with the exposure of user relationships, particularly through network structure, are often neglected. This study aims to fill this critical gap by advancing the understanding and protection against privacy risks emanating from network structure, moving beyond direct connections with neighbors to include the broader implications of indirect network structural patterns. To achieve this, we first investigate the problem of Graph Privacy Leakage via Structure (GPS), and introduce a novel measure, the Generalized Homophily Ratio, to quantify the various mechanisms contributing to privacy breach risks in GPS. Based on this insight, we develop a novel graph private attribute inference attack, which acts as a pivotal tool for evaluating the potential for privacy leakage through network structures under worst-case scenarios. To protect users' private data from such vulnerabilities, we propose a graph data publishing method incorporating a learnable graph sampling technique, effectively transforming the original graph into a privacy-preserving version. Extensive experiments demonstrate that our attack model poses a significant threat to user privacy, and our graph data publishing method successfully achieves the optimal privacy-utility trade-off compared to baselines.
3D Question Answering for City Scene Understanding
Jul 24, 20243D multimodal question answering (MQA) plays a crucial role in scene understanding by enabling intelligent agents to comprehend their surroundings in 3D environments. While existing research has primarily focused on indoor household tasks and outdoor roadside autonomous driving tasks, there has been limited exploration of city-level scene understanding tasks. Furthermore, existing research faces challenges in understanding city scenes, due to the absence of spatial semantic information and human-environment interaction information at the city level.To address these challenges, we investigate 3D MQA from both dataset and method perspectives. From the dataset perspective, we introduce a novel 3D MQA dataset named City-3DQA for city-level scene understanding, which is the first dataset to incorporate scene semantic and human-environment interactive tasks within the city. From the method perspective, we propose a Scene graph enhanced City-level Understanding method (Sg-CityU), which utilizes the scene graph to introduce the spatial semantic. A new benchmark is reported and our proposed Sg-CityU achieves accuracy of 63.94 % and 63.76 % in different settings of City-3DQA. Compared to indoor 3D MQA methods and zero-shot using advanced large language models (LLMs), Sg-CityU demonstrates state-of-the-art (SOTA) performance in robustness and generalization.
Diffusion Models as Optimizers for Efficient Planning in Offline RL
Jul 23, 2024



Diffusion models have shown strong competitiveness in offline reinforcement learning tasks by formulating decision-making as sequential generation. However, the practicality of these methods is limited due to the lengthy inference processes they require. In this paper, we address this problem by decomposing the sampling process of diffusion models into two decoupled subprocesses: 1) generating a feasible trajectory, which is a time-consuming process, and 2) optimizing the trajectory. With this decomposition approach, we are able to partially separate efficiency and quality factors, enabling us to simultaneously gain efficiency advantages and ensure quality assurance. We propose the Trajectory Diffuser, which utilizes a faster autoregressive model to handle the generation of feasible trajectories while retaining the trajectory optimization process of diffusion models. This allows us to achieve more efficient planning without sacrificing capability. To evaluate the effectiveness and efficiency of the Trajectory Diffuser, we conduct experiments on the D4RL benchmarks. The results demonstrate that our method achieves $\it 3$-$\it 10 \times$ faster inference speed compared to previous sequence modeling methods, while also outperforming them in terms of overall performance. https://github.com/RenMing-Huang/TrajectoryDiffuser Keywords: Reinforcement Learning and Efficient Planning and Diffusion Model
DMM: Disparity-guided Multispectral Mamba for Oriented Object Detection in Remote Sensing
Jul 11, 2024



Multispectral oriented object detection faces challenges due to both inter-modal and intra-modal discrepancies. Recent studies often rely on transformer-based models to address these issues and achieve cross-modal fusion detection. However, the quadratic computational complexity of transformers limits their performance. Inspired by the efficiency and lower complexity of Mamba in long sequence tasks, we propose Disparity-guided Multispectral Mamba (DMM), a multispectral oriented object detection framework comprised of a Disparity-guided Cross-modal Fusion Mamba (DCFM) module, a Multi-scale Target-aware Attention (MTA) module, and a Target-Prior Aware (TPA) auxiliary task. The DCFM module leverages disparity information between modalities to adaptively merge features from RGB and IR images, mitigating inter-modal conflicts. The MTA module aims to enhance feature representation by focusing on relevant target regions within the RGB modality, addressing intra-modal variations. The TPA auxiliary task utilizes single-modal labels to guide the optimization of the MTA module, ensuring it focuses on targets and their local context. Extensive experiments on the DroneVehicle and VEDAI datasets demonstrate the effectiveness of our method, which outperforms state-of-the-art methods while maintaining computational efficiency. Code will be available at https://github.com/Another-0/DMM.
Chromosomal Structural Abnormality Diagnosis by Homologous Similarity
Jul 11, 2024Pathogenic chromosome abnormalities are very common among the general population. While numerical chromosome abnormalities can be quickly and precisely detected, structural chromosome abnormalities are far more complex and typically require considerable efforts by human experts for identification. This paper focuses on investigating the modeling of chromosome features and the identification of chromosomes with structural abnormalities. Most existing data-driven methods concentrate on a single chromosome and consider each chromosome independently, overlooking the crucial aspect of homologous chromosomes. In normal cases, homologous chromosomes share identical structures, with the exception that one of them is abnormal. Therefore, we propose an adaptive method to align homologous chromosomes and diagnose structural abnormalities through homologous similarity. Inspired by the process of human expert diagnosis, we incorporate information from multiple pairs of homologous chromosomes simultaneously, aiming to reduce noise disturbance and improve prediction performance. Extensive experiments on real-world datasets validate the effectiveness of our model compared to baselines.
Ternary Spike-based Neuromorphic Signal Processing System
Jul 07, 2024



Deep Neural Networks (DNNs) have been successfully implemented across various signal processing fields, resulting in significant enhancements in performance. However, DNNs generally require substantial computational resources, leading to significant economic costs and posing challenges for their deployment on resource-constrained edge devices. In this study, we take advantage of spiking neural networks (SNNs) and quantization technologies to develop an energy-efficient and lightweight neuromorphic signal processing system. Our system is characterized by two principal innovations: a threshold-adaptive encoding (TAE) method and a quantized ternary SNN (QT-SNN). The TAE method can efficiently encode time-varying analog signals into sparse ternary spike trains, thereby reducing energy and memory demands for signal processing. QT-SNN, compatible with ternary spike trains from the TAE method, quantifies both membrane potentials and synaptic weights to reduce memory requirements while maintaining performance. Extensive experiments are conducted on two typical signal-processing tasks: speech and electroencephalogram recognition. The results demonstrate that our neuromorphic signal processing system achieves state-of-the-art (SOTA) performance with a 94% reduced memory requirement. Furthermore, through theoretical energy consumption analysis, our system shows 7.5x energy saving compared to other SNN works. The efficiency and efficacy of the proposed system highlight its potential as a promising avenue for energy-efficient signal processing.
The Solution for Language-Enhanced Image New Category Discovery
Jul 06, 2024


Treating texts as images, combining prompts with textual labels for prompt tuning, and leveraging the alignment properties of CLIP have been successfully applied in zero-shot multi-label image recognition. Nonetheless, relying solely on textual labels to store visual information is insufficient for representing the diversity of visual objects. In this paper, we propose reversing the training process of CLIP and introducing the concept of Pseudo Visual Prompts. These prompts are initialized for each object category and pre-trained on large-scale, low-cost sentence data generated by large language models. This process mines the aligned visual information in CLIP and stores it in class-specific visual prompts. We then employ contrastive learning to transfer the stored visual information to the textual labels, enhancing their visual representation capacity. Additionally, we introduce a dual-adapter module that simultaneously leverages knowledge from the original CLIP and new learning knowledge derived from downstream datasets. Benefiting from the pseudo visual prompts, our method surpasses the state-of-the-art not only on clean annotated text data but also on pseudo text data generated by large language models.
The Solution for the AIGC Inference Performance Optimization Competition
Jul 06, 2024In recent years, the rapid advancement of large-scale pre-trained language models based on transformer architectures has revolutionized natural language processing tasks. Among these, ChatGPT has gained widespread popularity, demonstrating human-level conversational abilities and attracting over 100 million monthly users by late 2022. Concurrently, Baidu's commercial deployment of the Ernie Wenxin model has significantly enhanced marketing effectiveness through AI-driven technologies. This paper focuses on optimizing high-performance inference for Ernie models, emphasizing GPU acceleration and leveraging the Paddle inference framework. We employ techniques such as Faster Transformer for efficient model processing, embedding layer pruning to reduce computational overhead, and FP16 half-precision inference for enhanced computational efficiency. Additionally, our approach integrates efficient data handling strategies using multi-process parallel processing to minimize latency. Experimental results demonstrate that our optimized solution achieves up to an 8.96x improvement in inference speed compared to standard methods, while maintaining competitive performance.
The Solution for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition
Jul 06, 2024
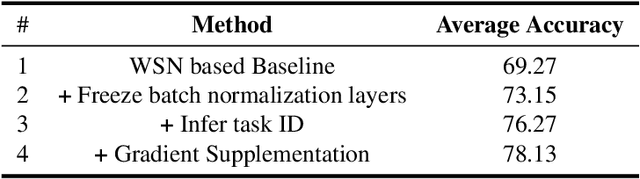
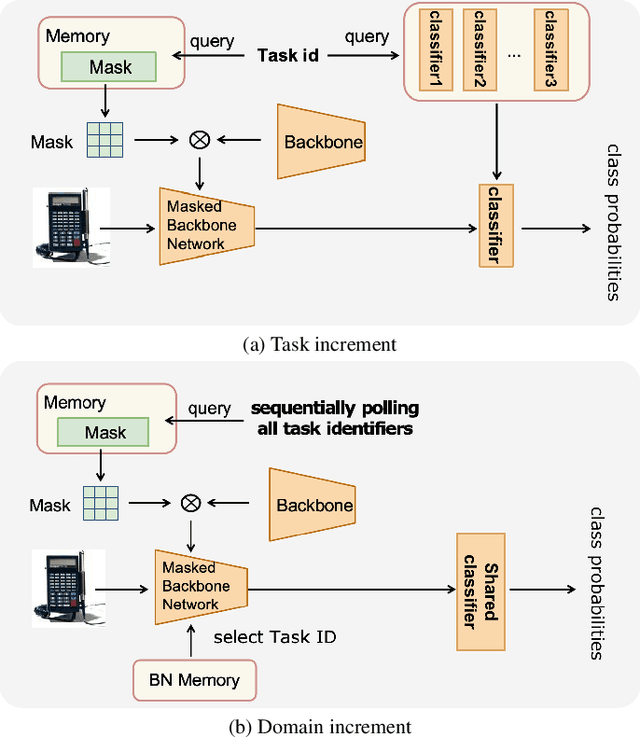
This paper presents a data-free, parameter-isolation-based continual learning algorithm we developed for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition. The method learns an independent parameter subspace for each task within the network's convolutional and linear layers and freezes the batch normalization layers after the first task. Specifically, for domain incremental setting where all domains share a classification head, we freeze the shared classification head after first task is completed, effectively solving the issue of catastrophic forgetting. Additionally, facing the challenge of domain incremental settings without providing a task identity, we designed an inference task identity strategy, selecting an appropriate mask matrix for each sample. Furthermore, we introduced a gradient supplementation strategy to enhance the importance of unselected parameters for the current task, facilitating learning for new tasks. We also implemented an adaptive importance scoring strategy that dynamically adjusts the amount of parameters to optimize single-task performance while reducing parameter usage. Moreover, considering the limitations of storage space and inference time, we designed a mask matrix compression strategy to save storage space and improve the speed of encryption and decryption of the mask matrix. Our approach does not require expanding the core network or using external auxiliary networks or data, and performs well under both task incremental and domain incremental settings. This solution ultimately won a second-place prize in the competition.