 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Vision and Language Concepts through Optimal Transport Semantic Flow
Jun 25, 2026Concept Bottleneck Models (CBMs) promise transparent reasoning by predicting through human-interpretable concepts, yet their effectiveness fundamentally depends on how well visual and textual representations are aligned or matched. Existing vision-language CBMs often rely on pre-aligned encoders or global cosine similarity, which obscures fine-grained concept localization and fails to reflect true semantic geometry. In this work, we rethink concept alignment as a dynamic cross-modal transport process instead of static projection and propose the Optimal Transport Flow Concept Bottleneck Model (OTF-CBM). It first learns a data-driven semantic cost via Inverse Optimal Transport to measure cross-modal distances, and then performs unbalanced optimal-transport-based flow matching to model semantic transitions between visual patches and textual concepts. With velocity-based concept activation, OTF-CBM captures interpretable geometric relations without ODE integration. Experiments further show that OTF-CBM achieves superior classification accuracy and concept faithfulness, offering a new geometric and dynamical perspective for interpretable cross-modal reasoning.
SkeletonContext: Skeleton-side Context Prompt Learning for Zero-Shot Skeleton-based Action Recognition
Mar 31, 2026Zero-shot skeleton-based action recognition aims to recognize unseen actions by transferring knowledge from seen categories through semantic descriptions. Most existing methods typically align skeleton features with textual embeddings within a shared latent space. However, the absence of contextual cues, such as objects involved in the action, introduces an inherent gap between skeleton and semantic representations, making it difficult to distinguish visually similar actions. To address this, we propose SkeletonContext, a prompt-based framework that enriches skeletal motion representations with language-driven contextual semantics. Specifically, we introduce a Cross-Modal Context Prompt Module, which leverages a pretrained language model to reconstruct masked contextual prompts under guidance derived from LLMs. This design effectively transfers linguistic context to the skeleton encoder for instance-level semantic grounding and improved cross-modal alignment. In addition, a Key-Part Decoupling Module is incorporated to decouple motion-relevant joint features, ensuring robust action understanding even in the absence of explicit object interactions. Extensive experiments on multiple benchmarks demonstrate that SkeletonContext achieves state-of-the-art performance under both conventional and generalized zero-shot settings, validating its effectiveness in reasoning about context and distinguishing fine-grained, visually similar actions.
Multi-Granularity Mutual Refinement Network for Zero-Shot Learning
Nov 11, 2025Zero-shot learning (ZSL) aims to recognize unseen classes with zero samples by transferring semantic knowledge from seen classes. Current approaches typically correlate global visual features with semantic information (i.e., attributes) or align local visual region features with corresponding attributes to enhance visual-semantic interactions. Although effective, these methods often overlook the intrinsic interactions between local region features, which can further improve the acquisition of transferable and explicit visual features. In this paper, we propose a network named Multi-Granularity Mutual Refinement Network (Mg-MRN), which refine discriminative and transferable visual features by learning decoupled multi-granularity features and cross-granularity feature interactions. Specifically, we design a multi-granularity feature extraction module to learn region-level discriminative features through decoupled region feature mining. Then, a cross-granularity feature fusion module strengthens the inherent interactions between region features of varying granularities. This module enhances the discriminability of representations at each granularity level by integrating region representations from adjacent hierarchies, further improving ZSL recognition performance. Extensive experiments on three popular ZSL benchmark datasets demonstrate the superiority and competitiveness of our proposed Mg-MRN method. Our code is available at https://github.com/NingWang2049/Mg-MRN.
DMM: Disparity-guided Multispectral Mamba for Oriented Object Detection in Remote Sensing
Jul 11, 2024



Multispectral oriented object detection faces challenges due to both inter-modal and intra-modal discrepancies. Recent studies often rely on transformer-based models to address these issues and achieve cross-modal fusion detection. However, the quadratic computational complexity of transformers limits their performance. Inspired by the efficiency and lower complexity of Mamba in long sequence tasks, we propose Disparity-guided Multispectral Mamba (DMM), a multispectral oriented object detection framework comprised of a Disparity-guided Cross-modal Fusion Mamba (DCFM) module, a Multi-scale Target-aware Attention (MTA) module, and a Target-Prior Aware (TPA) auxiliary task. The DCFM module leverages disparity information between modalities to adaptively merge features from RGB and IR images, mitigating inter-modal conflicts. The MTA module aims to enhance feature representation by focusing on relevant target regions within the RGB modality, addressing intra-modal variations. The TPA auxiliary task utilizes single-modal labels to guide the optimization of the MTA module, ensuring it focuses on targets and their local context. Extensive experiments on the DroneVehicle and VEDAI datasets demonstrate the effectiveness of our method, which outperforms state-of-the-art methods while maintaining computational efficiency. Code will be available at https://github.com/Another-0/DMM.
A Systematic Collection of Medical Image Datasets for Deep Learning
Jun 24, 2021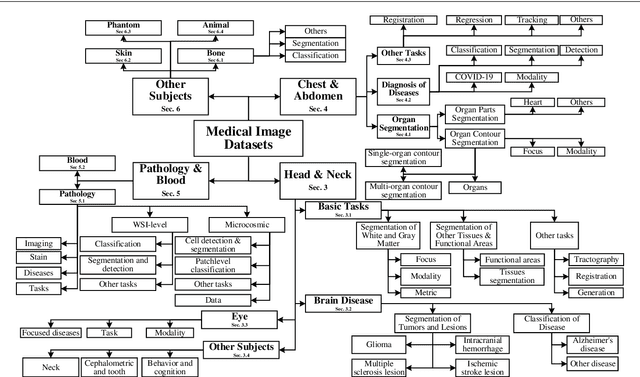
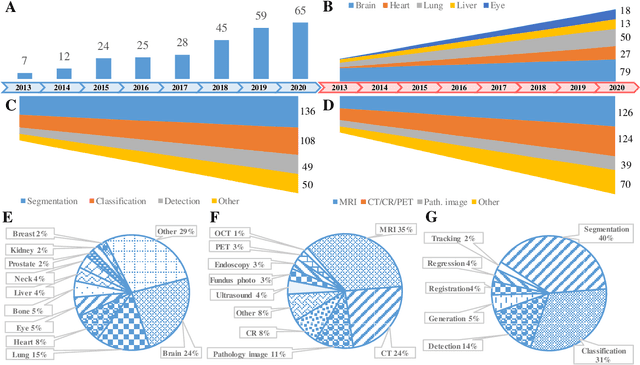
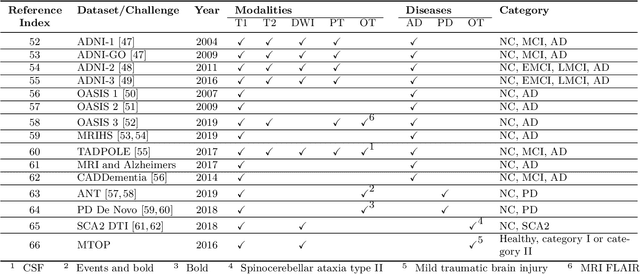
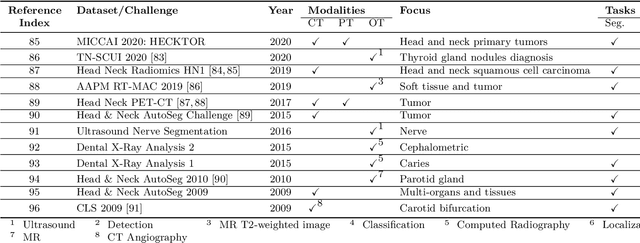
The astounding success made by artificial intelligence (AI) in healthcare and other fields proves that AI can achieve human-like performance. However, success always comes with challenges. Deep learning algorithms are data-dependent and require large datasets for training. The lack of data in the medical imaging field creates a bottleneck for the application of deep learning to medical image analysis. Medical image acquisition, annotation, and analysis are costly, and their usage is constrained by ethical restrictions. They also require many resources, such as human expertise and funding. That makes it difficult for non-medical researchers to have access to useful and large medical data. Thus, as comprehensive as possible, this paper provides a collection of medical image datasets with their associated challenges for deep learning research. We have collected information of around three hundred datasets and challenges mainly reported between 2013 and 2020 and categorized them into four categories: head & neck, chest & abdomen, pathology & blood, and ``others''. Our paper has three purposes: 1) to provide a most up to date and complete list that can be used as a universal reference to easily find the datasets for clinical image analysis, 2) to guide researchers on the methodology to test and evaluate their methods' performance and robustness on relevant datasets, 3) to provide a ``route'' to relevant algorithms for the relevant medical topics, and challenge leaderboards.