 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMF-MedIT: An Efficient Align-Modulation-Fusion Framework for Medical Image-Tabular Data
Jun 24, 2025Multimodal medical analysis combining image and tabular data has gained increasing attention. However, effective fusion remains challenging due to cross-modal discrepancies in feature dimensions and modality contributions, as well as the noise from high-dimensional tabular inputs. To address these problems, we present AMF-MedIT, an efficient Align-Modulation-Fusion framework for medical image and tabular data integration, particularly under data-scarce conditions. To harmonize dimension discrepancies and dynamically adjust modality contributions, we propose the Adaptive Modulation and Fusion (AMF) module, a novel modulation-based fusion paradigm with a streamlined architecture. We first derive the modulation objectives and introduce a modality confidence ratio, enabling the incorporation of prior knowledge into the fusion process. Then, the feature masks, density and leakage losses are proposed to achieve the modulation objectives. Additionally, we introduce FT-Mamba, a powerful tabular encoder leveraging a selective mechanism to handle noisy medical tabular data efficiently. Furthermore, interpretability studies are conducted to explore how different tabular encoders supervise the imaging modality during contrastive pretraining for the first time. Extensive experiments demonstrate that AMF-MedIT achieves a superior balance between multimodal performance and data efficiency while showing strong adaptability to incomplete tabular data. Interpretability analysis also highlights FT-Mamba's capabilities in extracting distinct tabular features and guiding the image encoder toward more accurate and flexible attention patterns.
Duality and Policy Evaluation in Distributionally Robust Bayesian Diffusion Control
Jun 24, 2025We consider a Bayesian diffusion control problem of expected terminal utility maximization. The controller imposes a prior distribution on the unknown drift of an underlying diffusion. The Bayesian optimal control, tracking the posterior distribution of the unknown drift, can be characterized explicitly. However, in practice, the prior will generally be incorrectly specified, and the degree of model misspecification can have a significant impact on policy performance. To mitigate this and reduce overpessimism, we introduce a distributionally robust Bayesian control (DRBC) formulation in which the controller plays a game against an adversary who selects a prior in divergence neighborhood of a baseline prior. The adversarial approach has been studied in economics and efficient algorithms have been proposed in static optimization settings. We develop a strong duality result for our DRBC formulation. Combining these results together with tools from stochastic analysis, we are able to derive a loss that can be efficiently trained (as we demonstrate in our numerical experiments) using a suitable neural network architecture. As a result, we obtain an effective algorithm for computing the DRBC optimal strategy. The methodology for computing the DRBC optimal strategy is greatly simplified, as we show, in the important case in which the adversary chooses a prior from a Kullback-Leibler distributional uncertainty set.
Alleviating User-Sensitive bias with Fair Generative Sequential Recommendation Model
Jun 24, 2025Recommendation fairness has recently attracted much attention. In the real world, recommendation systems are driven by user behavior, and since users with the same sensitive feature (e.g., gender and age) tend to have the same patterns, recommendation models can easily capture the strong correlation preference of sensitive features and thus cause recommendation unfairness. Diffusion model (DM) as a new generative model paradigm has achieved great success in recommendation systems. DM's ability to model uncertainty and represent diversity, and its modeling mechanism has a high degree of adaptability with the real-world recommendation process with bias. Therefore, we use DM to effectively model the fairness of recommendation and enhance the diversity. This paper proposes a FairGENerative sequential Recommendation model based on DM, FairGENRec. In the training phase, we inject random noise into the original distribution under the guidance of the sensitive feature recognition model, and a sequential denoise model is designed for the reverse reconstruction of items. Simultaneously, recommendation fairness modeling is completed by injecting multi-interests representational information that eliminates the bias of sensitive user features into the generated results. In the inference phase, the model obtains the noise in the form of noise addition by using the history interactions which is followed by reverse iteration to reconstruct the target item representation. Finally, our extensive experiments on three datasets demonstrate the dual enhancement effect of FairGENRec on accuracy and fairness, while the statistical analysis of the cases visualizes the degree of improvement on the fairness of the recommendation.
Skywork-SWE: Unveiling Data Scaling Laws for Software Engineering in LLMs
Jun 24, 2025Software engineering (SWE) has recently emerged as a crucial testbed for next-generation LLM agents, demanding inherent capabilities in two critical dimensions: sustained iterative problem-solving (e.g., >50 interaction rounds) and long-context dependency resolution (e.g., >32k tokens). However, the data curation process in SWE remains notoriously time-consuming, as it heavily relies on manual annotation for code file filtering and the setup of dedicated runtime environments to execute and validate unit tests. Consequently, most existing datasets are limited to only a few thousand GitHub-sourced instances. To this end, we propose an incremental, automated data-curation pipeline that systematically scales both the volume and diversity of SWE datasets. Our dataset comprises 10,169 real-world Python task instances from 2,531 distinct GitHub repositories, each accompanied by a task specified in natural language and a dedicated runtime-environment image for automated unit-test validation. We have carefully curated over 8,000 successfully runtime-validated training trajectories from our proposed SWE dataset. When fine-tuning the Skywork-SWE model on these trajectories, we uncover a striking data scaling phenomenon: the trained model's performance for software engineering capabilities in LLMs continues to improve as the data size increases, showing no signs of saturation. Notably, our Skywork-SWE model achieves 38.0% pass@1 accuracy on the SWE-bench Verified benchmark without using verifiers or multiple rollouts, establishing a new state-of-the-art (SOTA) among the Qwen2.5-Coder-32B-based LLMs built on the OpenHands agent framework. Furthermore, with the incorporation of test-time scaling techniques, the performance further improves to 47.0% accuracy, surpassing the previous SOTA results for sub-32B parameter models. We release the Skywork-SWE-32B model checkpoint to accelerate future research.
TC-Light: Temporally Consistent Relighting for Dynamic Long Videos
Jun 23, 2025Editing illumination in long videos with complex dynamics has significant value in various downstream tasks, including visual content creation and manipulation, as well as data scaling up for embodied AI through sim2real and real2real transfer. Nevertheless, existing video relighting techniques are predominantly limited to portrait videos or fall into the bottleneck of temporal consistency and computation efficiency. In this paper, we propose TC-Light, a novel paradigm characterized by the proposed two-stage post optimization mechanism. Starting from the video preliminarily relighted by an inflated video relighting model, it optimizes appearance embedding in the first stage to align global illumination. Then it optimizes the proposed canonical video representation, i.e., Unique Video Tensor (UVT), to align fine-grained texture and lighting in the second stage. To comprehensively evaluate performance, we also establish a long and highly dynamic video benchmark. Extensive experiments show that our method enables physically plausible relighting results with superior temporal coherence and low computation cost. The code and video demos are available at https://dekuliutesla.github.io/tclight/.
Exploring Non-contrastive Self-supervised Representation Learning for Image-based Profiling
Jun 17, 2025Image-based cell profiling aims to create informative representations of cell images. This technique is critical in drug discovery and has greatly advanced with recent improvements in computer vision. Inspired by recent developments in non-contrastive Self-Supervised Learning (SSL), this paper provides an initial exploration into training a generalizable feature extractor for cell images using such methods. However, there are two major challenges: 1) There is a large difference between the distributions of cell images and natural images, causing the view-generation process in existing SSL methods to fail; and 2) Unlike typical scenarios where each representation is based on a single image, cell profiling often involves multiple input images, making it difficult to effectively combine all available information. To overcome these challenges, we propose SSLProfiler, a non-contrastive SSL framework specifically designed for cell profiling. We introduce specialized data augmentation and representation post-processing methods tailored to cell images, which effectively address the issues mentioned above and result in a robust feature extractor. With these improvements, SSLProfiler won the Cell Line Transferability challenge at CVPR 2025.
xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations
Jun 16, 2025


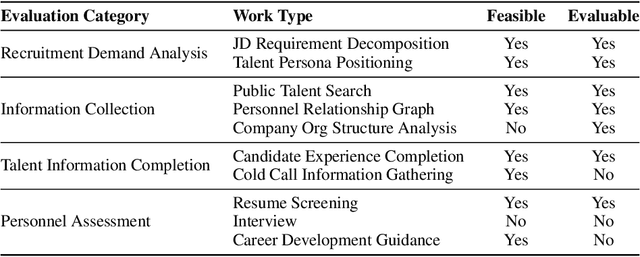
We introduce xbench, a dynamic, profession-aligned evaluation suite designed to bridge the gap between AI agent capabilities and real-world productivity. While existing benchmarks often focus on isolated technical skills, they may not accurately reflect the economic value agents deliver in professional settings. To address this, xbench targets commercially significant domains with evaluation tasks defined by industry professionals. Our framework creates metrics that strongly correlate with productivity value, enables prediction of Technology-Market Fit (TMF), and facilitates tracking of product capabilities over time. As our initial implementations, we present two benchmarks: Recruitment and Marketing. For Recruitment, we collect 50 tasks from real-world headhunting business scenarios to evaluate agents' abilities in company mapping, information retrieval, and talent sourcing. For Marketing, we assess agents' ability to match influencers with advertiser needs, evaluating their performance across 50 advertiser requirements using a curated pool of 836 candidate influencers. We present initial evaluation results for leading contemporary agents, establishing a baseline for these professional domains. Our continuously updated evalsets and evaluations are available at https://xbench.org.
AgentOrchestra: A Hierarchical Multi-Agent Framework for General-Purpose Task Solving
Jun 14, 2025



Recent advances in agent systems based on large language models (LLMs) have demonstrated strong capabilities in solving complex tasks. However, most current methods lack mechanisms for coordinating specialized agents and have limited ability to generalize to new or diverse domains. We introduce \projectname, a hierarchical multi-agent framework for general-purpose task solving that integrates high-level planning with modular agent collaboration. Inspired by the way a conductor orchestrates a symphony and guided by the principles of \textit{extensibility}, \textit{multimodality}, \textit{modularity}, and \textit{coordination}, \projectname features a central planning agent that decomposes complex objectives and delegates sub-tasks to a team of specialized agents. Each sub-agent is equipped with general programming and analytical tools, as well as abilities to tackle a wide range of real-world specific tasks, including data analysis, file operations, web navigation, and interactive reasoning in dynamic multimodal environments. \projectname supports flexible orchestration through explicit sub-goal formulation, inter-agent communication, and adaptive role allocation. We evaluate the framework on three widely used benchmark datasets covering various real-world tasks, searching web pages, reasoning over heterogeneous modalities, etc. Experimental results demonstrate that \projectname consistently outperforms flat-agent and monolithic baselines in task success rate and adaptability. These findings highlight the effectiveness of hierarchical organization and role specialization in building scalable and general-purpose LLM-based agent systems.
OmniFluids: Unified Physics Pre-trained Modeling of Fluid Dynamics
Jun 12, 2025High-fidelity and efficient simulation of fluid dynamics drive progress in various scientific and engineering applications. Traditional computational fluid dynamics methods offer strong interpretability and guaranteed convergence, but rely on fine spatial and temporal meshes, incurring prohibitive computational costs. Physics-informed neural networks (PINNs) and neural operators aim to accelerate PDE solvers using deep learning techniques. However, PINNs require extensive retraining and careful tuning, and purely data-driven operators demand large labeled datasets. Hybrid physics-aware methods embed numerical discretizations into network architectures or loss functions, but achieve marginal speed gains and become unstable when balancing coarse priors against high-fidelity measurements. To this end, we introduce OmniFluids, a unified physics pre-trained operator learning framework that integrates physics-only pre-training, coarse-grid operator distillation, and few-shot fine-tuning, which enables fast inference and accurate prediction under limited or zero data supervision. For architectural design, the key components of OmniFluids include a mixture of operators, a multi-frame decoder, and factorized Fourier layers, which enable efficient and scalable modeling of diverse physical tasks while maintaining seamless integration with physics-based supervision. Across a broad range of two- and three-dimensional benchmarks, OmniFluids significantly outperforms state-of-the-art AI-driven methods in flow field reconstruction and turbulence statistics accuracy, delivering 10-100x speedups compared to classical solvers, and accurately recovers unknown physical parameters from sparse, noisy data. This work establishes a new paradigm for efficient and generalizable surrogate modeling in complex fluid systems under limited data availability.
DART: Differentiable Dynamic Adaptive Region Tokenizer for Vision Transformer and Mamba
Jun 12, 2025Recently, non-convolutional models such as the Vision Transformer (ViT) and Vision Mamba (Vim) have achieved remarkable performance in computer vision tasks. However, their reliance on fixed-size patches often results in excessive encoding of background regions and omission of critical local details, especially when informative objects are sparsely distributed. To address this, we introduce a fully differentiable Dynamic Adaptive Region Tokenizer (DART), which adaptively partitions images into content-dependent patches of varying sizes. DART combines learnable region scores with piecewise differentiable quantile operations to allocate denser tokens to information-rich areas. Despite introducing only approximately 1 million (1M) additional parameters, DART improves accuracy by 2.1% on DeiT (ImageNet-1K). Unlike methods that uniformly increase token density to capture fine-grained details, DART offers a more efficient alternative, achieving 45% FLOPs reduction with superior performance. Extensive experiments on DeiT, Vim, and VideoMamba confirm that DART consistently enhances accuracy while incurring minimal or even reduced computational overhead. Code is available at https://github.com/HCPLab-SYSU/DART.