 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability Analysis and Generalization Bounds of Adversarial Training
Oct 03, 2022
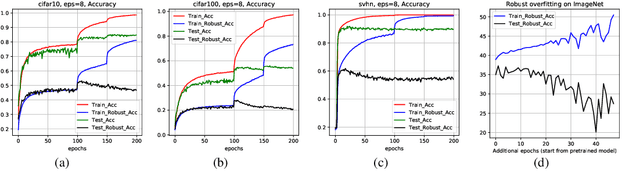
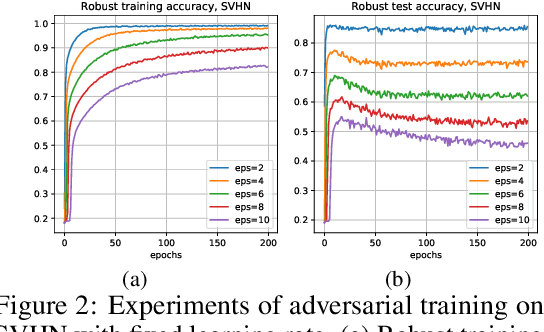
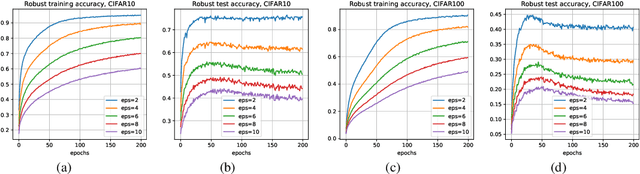
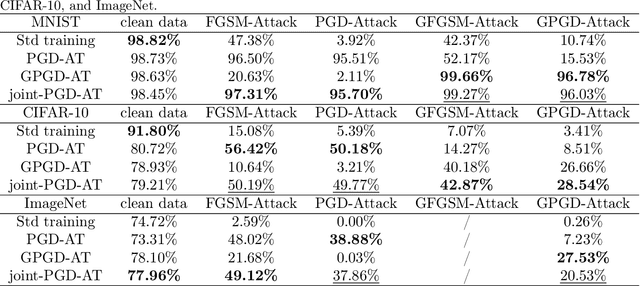
In adversarial machine learning, deep neural networks can fit the adversarial examples on the training dataset but have poor generalization ability on the test set. This phenomenon is called robust overfitting, and it can be observed when adversarially training neural nets on common datasets, including SVHN, CIFAR-10, CIFAR-100, and ImageNet. In this paper, we study the robust overfitting issue of adversarial training by using tools from uniform stability. One major challenge is that the outer function (as a maximization of the inner function) is nonsmooth, so the standard technique (e.g., hardt et al., 2016) cannot be applied. Our approach is to consider $\eta$-approximate smoothness: we show that the outer function satisfies this modified smoothness assumption with $\eta$ being a constant related to the adversarial perturbation. Based on this, we derive stability-based generalization bounds for stochastic gradient descent (SGD) on the general class of $\eta$-approximate smooth functions, which covers the adversarial loss. Our results provide a different understanding of robust overfitting from the perspective of uniform stability. Additionally, we show that a few popular techniques for adversarial training (\emph{e.g.,} early stopping, cyclic learning rate, and stochastic weight averaging) are stability-promoting in theory.
Adaptive Smoothness-weighted Adversarial Training for Multiple Perturbations with Its Stability Analysis
Oct 02, 2022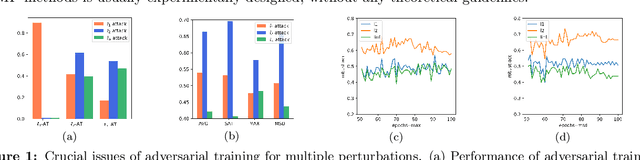
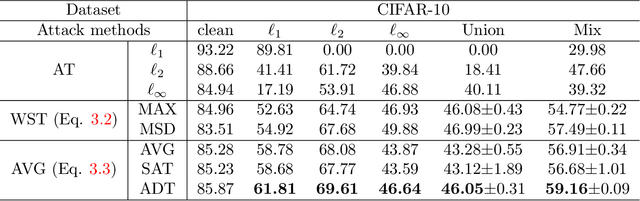
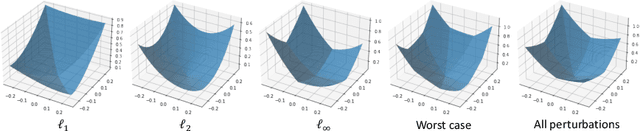
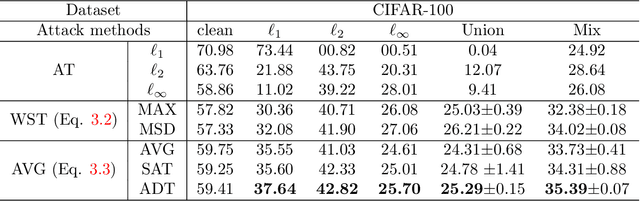
Adversarial Training (AT) has been demonstrated as one of the most effective methods against adversarial examples. While most existing works focus on AT with a single type of perturbation e.g., the $\ell_\infty$ attacks), DNNs are facing threats from different types of adversarial examples. Therefore, adversarial training for multiple perturbations (ATMP) is proposed to generalize the adversarial robustness over different perturbation types (in $\ell_1$, $\ell_2$, and $\ell_\infty$ norm-bounded perturbations). However, the resulting model exhibits trade-off between different attacks. Meanwhile, there is no theoretical analysis of ATMP, limiting its further development. In this paper, we first provide the smoothness analysis of ATMP and show that $\ell_1$, $\ell_2$, and $\ell_\infty$ adversaries give different contributions to the smoothness of the loss function of ATMP. Based on this, we develop the stability-based excess risk bounds and propose adaptive smoothness-weighted adversarial training for multiple perturbations. Theoretically, our algorithm yields better bounds. Empirically, our experiments on CIFAR10 and CIFAR100 achieve the state-of-the-art performance against the mixture of multiple perturbations attacks.
Understanding Adversarial Robustness Against On-manifold Adversarial Examples
Oct 02, 2022
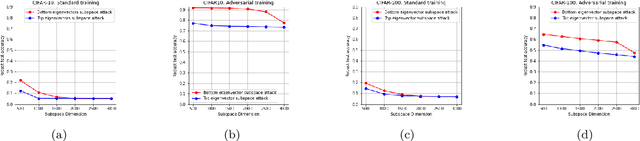
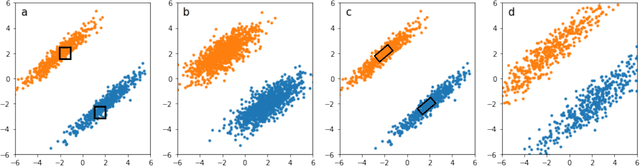
Deep neural networks (DNNs) are shown to be vulnerable to adversarial examples. A well-trained model can be easily attacked by adding small perturbations to the original data. One of the hypotheses of the existence of the adversarial examples is the off-manifold assumption: adversarial examples lie off the data manifold. However, recent research showed that on-manifold adversarial examples also exist. In this paper, we revisit the off-manifold assumption and want to study a question: at what level is the poor performance of neural networks against adversarial attacks due to on-manifold adversarial examples? Since the true data manifold is unknown in practice, we consider two approximated on-manifold adversarial examples on both real and synthesis datasets. On real datasets, we show that on-manifold adversarial examples have greater attack rates than off-manifold adversarial examples on both standard-trained and adversarially-trained models. On synthetic datasets, theoretically, We prove that on-manifold adversarial examples are powerful, yet adversarial training focuses on off-manifold directions and ignores the on-manifold adversarial examples. Furthermore, we provide analysis to show that the properties derived theoretically can also be observed in practice. Our analysis suggests that on-manifold adversarial examples are important, and we should pay more attention to on-manifold adversarial examples for training robust models.
A Large-scale Multiple-objective Method for Black-box Attack against Object Detection
Sep 16, 2022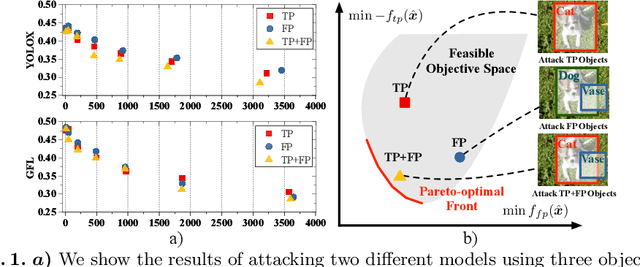
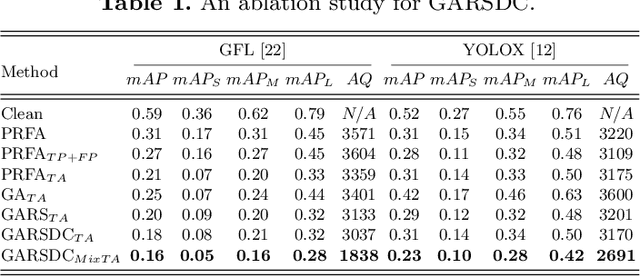
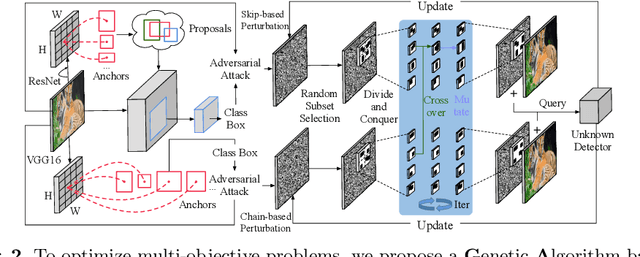
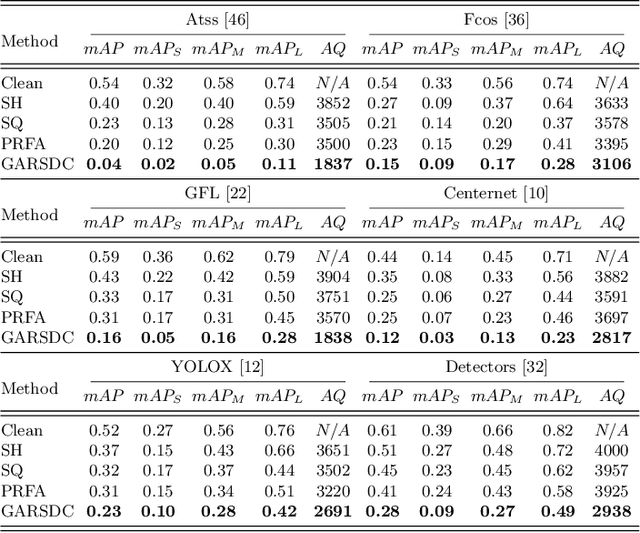
Recent studies have shown that detectors based on deep models are vulnerable to adversarial examples, even in the black-box scenario where the attacker cannot access the model information. Most existing attack methods aim to minimize the true positive rate, which often shows poor attack performance, as another sub-optimal bounding box may be detected around the attacked bounding box to be the new true positive one. To settle this challenge, we propose to minimize the true positive rate and maximize the false positive rate, which can encourage more false positive objects to block the generation of new true positive bounding boxes. It is modeled as a multi-objective optimization (MOP) problem, of which the generic algorithm can search the Pareto-optimal. However, our task has more than two million decision variables, leading to low searching efficiency. Thus, we extend the standard Genetic Algorithm with Random Subset selection and Divide-and-Conquer, called GARSDC, which significantly improves the efficiency. Moreover, to alleviate the sensitivity to population quality in generic algorithms, we generate a gradient-prior initial population, utilizing the transferability between different detectors with similar backbones. Compared with the state-of-art attack methods, GARSDC decreases by an average 12.0 in the mAP and queries by about 1000 times in extensive experiments. Our codes can be found at https://github.com/LiangSiyuan21/ GARSDC.
Towards Real-World Video Deblurring by Exploring Blur Formation Process
Aug 28, 2022

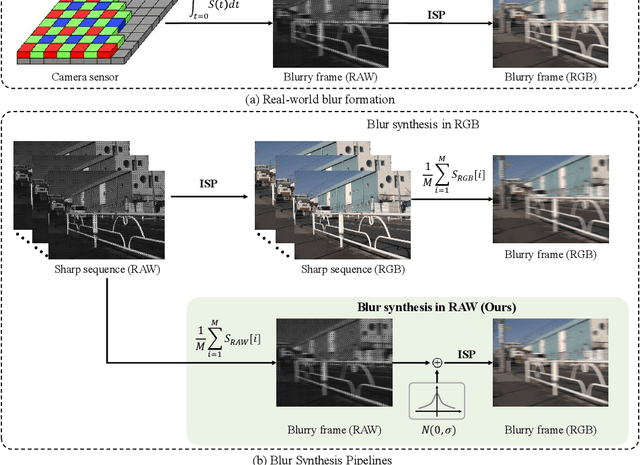
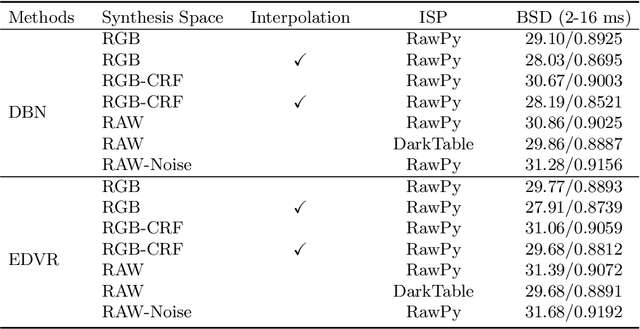
This paper aims at exploring how to synthesize close-to-real blurs that existing video deblurring models trained on them can generalize well to real-world blurry videos. In recent years, deep learning-based approaches have achieved promising success on video deblurring task. However, the models trained on existing synthetic datasets still suffer from generalization problems over real-world blurry scenarios with undesired artifacts. The factors accounting for the failure remain unknown. Therefore, we revisit the classical blur synthesis pipeline and figure out the possible reasons, including shooting parameters, blur formation space, and image signal processor~(ISP). To analyze the effects of these potential factors, we first collect an ultra-high frame-rate (940 FPS) RAW video dataset as the data basis to synthesize various kinds of blurs. Then we propose a novel realistic blur synthesis pipeline termed as RAW-Blur by leveraging blur formation cues. Through numerous experiments, we demonstrate that synthesizing blurs in the RAW space and adopting the same ISP as the real-world testing data can effectively eliminate the negative effects of synthetic data. Furthermore, the shooting parameters of the synthesized blurry video, e.g., exposure time and frame-rate play significant roles in improving the performance of deblurring models. Impressively, the models trained on the blurry data synthesized by the proposed RAW-Blur pipeline can obtain more than 5dB PSNR gain against those trained on the existing synthetic blur datasets. We believe the novel realistic synthesis pipeline and the corresponding RAW video dataset can help the community to easily construct customized blur datasets to improve real-world video deblurring performance largely, instead of laboriously collecting real data pairs.
HyP$^2$ Loss: Beyond Hypersphere Metric Space for Multi-label Image Retrieval
Aug 14, 2022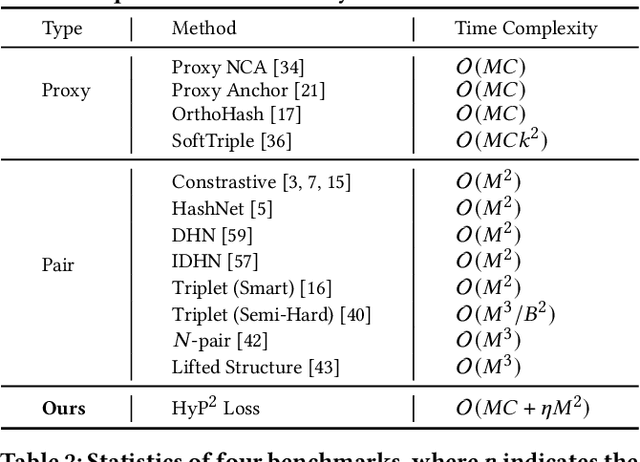
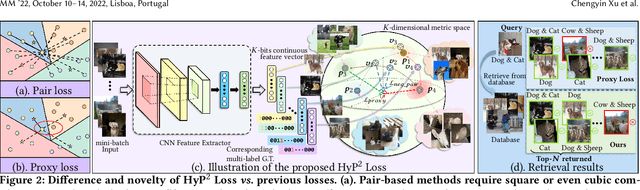
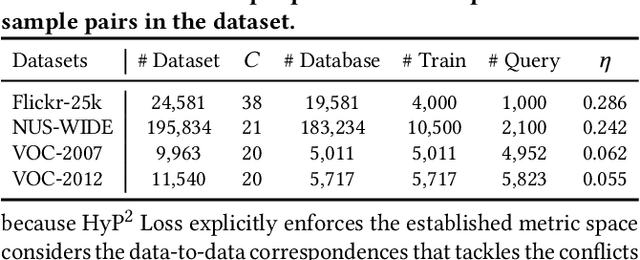
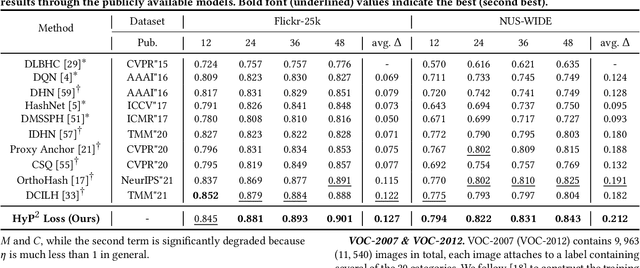
Image retrieval has become an increasingly appealing technique with broad multimedia application prospects, where deep hashing serves as the dominant branch towards low storage and efficient retrieval. In this paper, we carried out in-depth investigations on metric learning in deep hashing for establishing a powerful metric space in multi-label scenarios, where the pair loss suffers high computational overhead and converge difficulty, while the proxy loss is theoretically incapable of expressing the profound label dependencies and exhibits conflicts in the constructed hypersphere space. To address the problems, we propose a novel metric learning framework with Hybrid Proxy-Pair Loss (HyP$^2$ Loss) that constructs an expressive metric space with efficient training complexity w.r.t. the whole dataset. The proposed HyP$^2$ Loss focuses on optimizing the hypersphere space by learnable proxies and excavating data-to-data correlations of irrelevant pairs, which integrates sufficient data correspondence of pair-based methods and high-efficiency of proxy-based methods. Extensive experiments on four standard multi-label benchmarks justify the proposed method outperforms the state-of-the-art, is robust among different hash bits and achieves significant performance gains with a faster, more stable convergence speed. Our code is available at https://github.com/JerryXu0129/HyP2-Loss.
Fast Adversarial Training with Adaptive Step Size
Jun 06, 2022
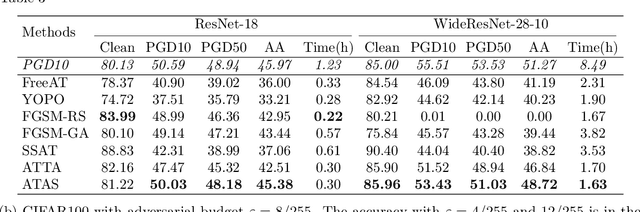
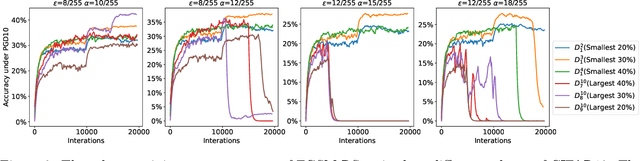
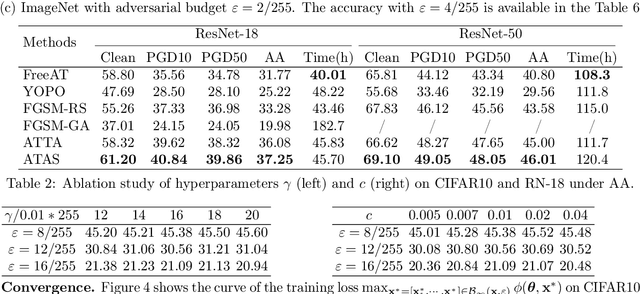
While adversarial training and its variants have shown to be the most effective algorithms to defend against adversarial attacks, their extremely slow training process makes it hard to scale to large datasets like ImageNet. The key idea of recent works to accelerate adversarial training is to substitute multi-step attacks (e.g., PGD) with single-step attacks (e.g., FGSM). However, these single-step methods suffer from catastrophic overfitting, where the accuracy against PGD attack suddenly drops to nearly 0% during training, destroying the robustness of the networks. In this work, we study the phenomenon from the perspective of training instances. We show that catastrophic overfitting is instance-dependent and fitting instances with larger gradient norm is more likely to cause catastrophic overfitting. Based on our findings, we propose a simple but effective method, Adversarial Training with Adaptive Step size (ATAS). ATAS learns an instancewise adaptive step size that is inversely proportional to its gradient norm. The theoretical analysis shows that ATAS converges faster than the commonly adopted non-adaptive counterparts. Empirically, ATAS consistently mitigates catastrophic overfitting and achieves higher robust accuracy on CIFAR10, CIFAR100 and ImageNet when evaluated on various adversarial budgets.
Improving the Latent Space of Image Style Transfer
May 24, 2022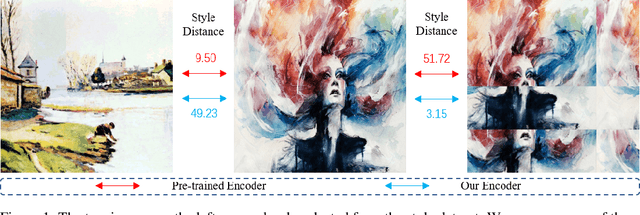
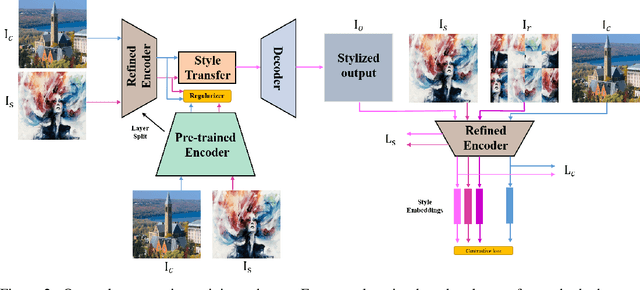
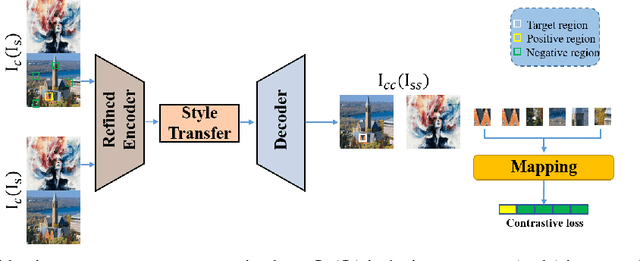

Existing neural style transfer researches have studied to match statistical information between the deep features of content and style images, which were extracted by a pre-trained VGG, and achieved significant improvement in synthesizing artistic images. However, in some cases, the feature statistics from the pre-trained encoder may not be consistent with the visual style we perceived. For example, the style distance between images of different styles is less than that of the same style. In such an inappropriate latent space, the objective function of the existing methods will be optimized in the wrong direction, resulting in bad stylization results. In addition, the lack of content details in the features extracted by the pre-trained encoder also leads to the content leak problem. In order to solve these issues in the latent space used by style transfer, we propose two contrastive training schemes to get a refined encoder that is more suitable for this task. The style contrastive loss pulls the stylized result closer to the same visual style image and pushes it away from the content image. The content contrastive loss enables the encoder to retain more available details. We can directly add our training scheme to some existing style transfer methods and significantly improve their results. Extensive experimental results demonstrate the effectiveness and superiority of our methods.
VDTR: Video Deblurring with Transformer
Apr 17, 2022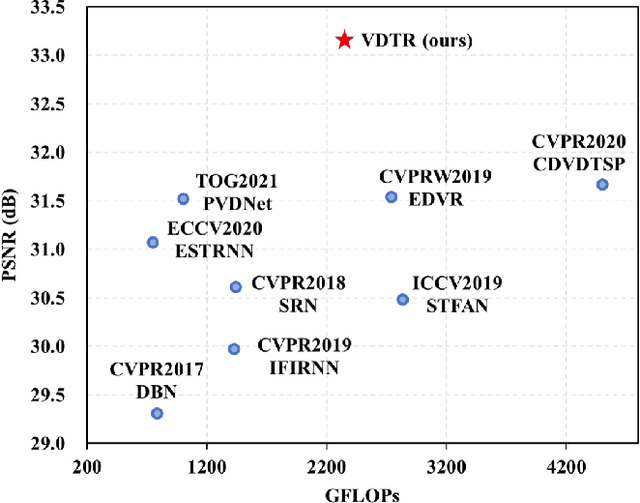


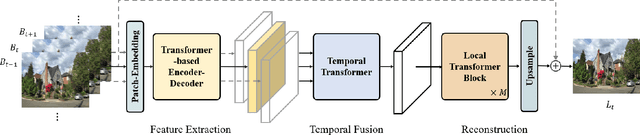
Video deblurring is still an unsolved problem due to the challenging spatio-temporal modeling process. While existing convolutional neural network-based methods show a limited capacity for effective spatial and temporal modeling for video deblurring. This paper presents VDTR, an effective Transformer-based model that makes the first attempt to adapt Transformer for video deblurring. VDTR exploits the superior long-range and relation modeling capabilities of Transformer for both spatial and temporal modeling. However, it is challenging to design an appropriate Transformer-based model for video deblurring due to the complicated non-uniform blurs, misalignment across multiple frames and the high computational costs for high-resolution spatial modeling. To address these problems, VDTR advocates performing attention within non-overlapping windows and exploiting the hierarchical structure for long-range dependencies modeling. For frame-level spatial modeling, we propose an encoder-decoder Transformer that utilizes multi-scale features for deblurring. For multi-frame temporal modeling, we adapt Transformer to fuse multiple spatial features efficiently. Compared with CNN-based methods, the proposed method achieves highly competitive results on both synthetic and real-world video deblurring benchmarks, including DVD, GOPRO, REDS and BSD. We hope such a Transformer-based architecture can serve as a powerful alternative baseline for video deblurring and other video restoration tasks. The source code will be available at \url{https://github.com/ljzycmd/VDTR}.
Sampling-based Fast Gradient Rescaling Method for Highly Transferable Adversarial Attacks
Apr 06, 2022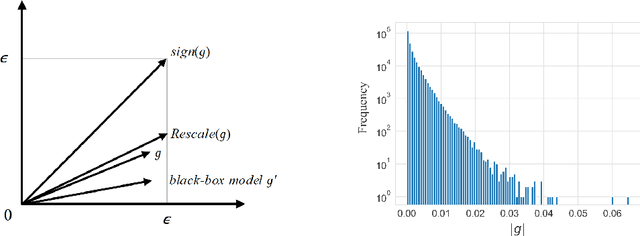
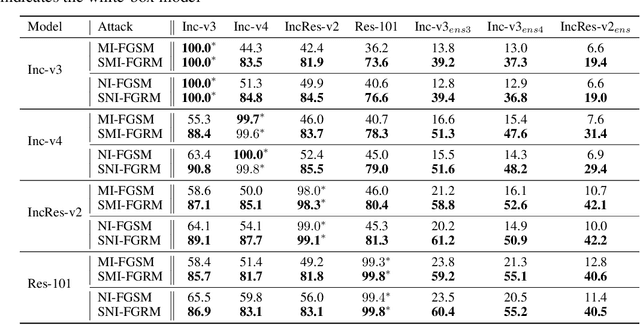
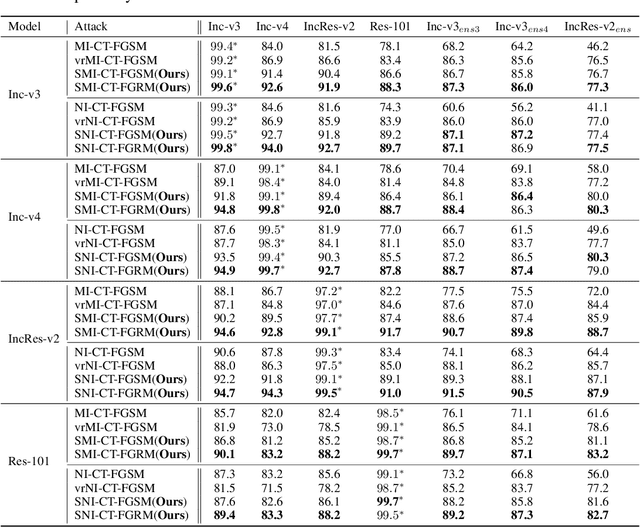
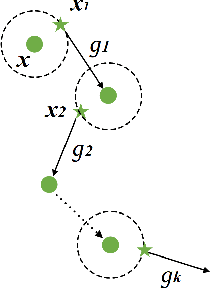
Deep neural networks have shown to be very vulnerable to adversarial examples crafted by adding human-imperceptible perturbations to benign inputs. After achieving impressive attack success rates in the white-box setting, more focus is shifted to black-box attacks. In either case, the common gradient-based approaches generally use the $sign$ function to generate perturbations at the end of the process. However, only a few works pay attention to the limitation of the $sign$ function. Deviation between the original gradient and the generated noises may lead to inaccurate gradient update estimation and suboptimal solutions for adversarial transferability, which is crucial for black-box attacks. To address this issue, we propose a Sampling-based Fast Gradient Rescaling Method (S-FGRM) to improve the transferability of the crafted adversarial examples. Specifically, we use data rescaling to substitute the inefficient $sign$ function in gradient-based attacks without extra computational cost. We also propose a Depth First Sampling method to eliminate the fluctuation of rescaling and stabilize the gradient update. Our method can be used in any gradient-based optimizations and is extensible to be integrated with various input transformation or ensemble methods for further improving the adversarial transferability. Extensive experiments on the standard ImageNet dataset show that our S-FGRM could significantly boost the transferability of gradient-based attacks and outperform the state-of-the-art baselines.