 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Optimize Permutation Flow Shop Scheduling via Graph-based Imitation Learning
Oct 31, 2022



The permutation flow shop scheduling (PFSS), aiming at finding the optimal permutation of jobs, is widely used in manufacturing systems. When solving the large-scale PFSS problems, traditional optimization algorithms such as heuristics could hardly meet the demands of both solution accuracy and computational efficiency. Thus learning-based methods have recently garnered more attention. Some work attempts to solve the problems by reinforcement learning methods, which suffer from slow convergence issues during training and are still not accurate enough regarding the solutions. To that end, we train the model via expert-driven imitation learning, which accelerates the convergence more stably and accurately. Moreover, in order to extract better feature representations of input jobs, we incorporate the graph structure as the encoder. The extensive experiments reveal that our proposed model obtains significant promotion and presents excellent generalizability in large-scale problems with up to 1000 jobs. Compared to the state-of-the-art reinforcement learning method, our model's network parameters are reduced to only 37\% of theirs, and the solution gap of our model towards the expert solutions decreases from 6.8\% to 1.3\% on average.
A Large-scale Multiple-objective Method for Black-box Attack against Object Detection
Sep 16, 2022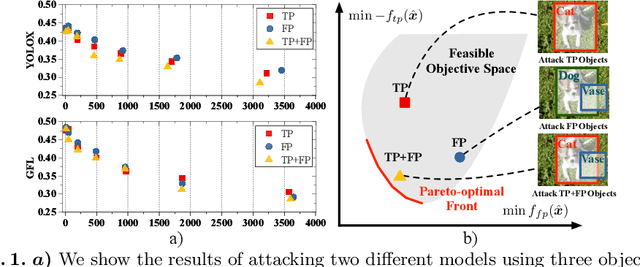
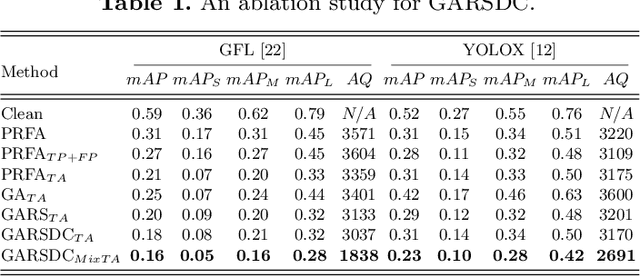
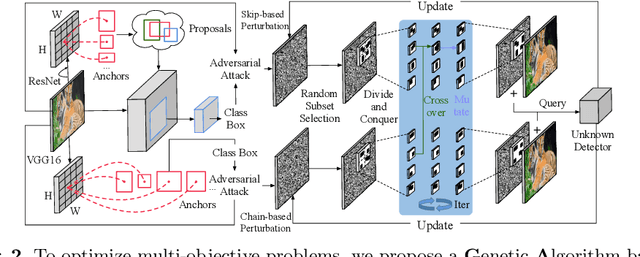
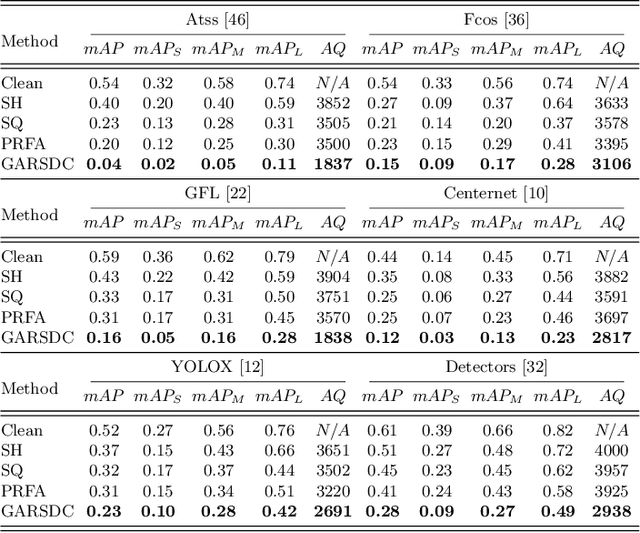
Recent studies have shown that detectors based on deep models are vulnerable to adversarial examples, even in the black-box scenario where the attacker cannot access the model information. Most existing attack methods aim to minimize the true positive rate, which often shows poor attack performance, as another sub-optimal bounding box may be detected around the attacked bounding box to be the new true positive one. To settle this challenge, we propose to minimize the true positive rate and maximize the false positive rate, which can encourage more false positive objects to block the generation of new true positive bounding boxes. It is modeled as a multi-objective optimization (MOP) problem, of which the generic algorithm can search the Pareto-optimal. However, our task has more than two million decision variables, leading to low searching efficiency. Thus, we extend the standard Genetic Algorithm with Random Subset selection and Divide-and-Conquer, called GARSDC, which significantly improves the efficiency. Moreover, to alleviate the sensitivity to population quality in generic algorithms, we generate a gradient-prior initial population, utilizing the transferability between different detectors with similar backbones. Compared with the state-of-art attack methods, GARSDC decreases by an average 12.0 in the mAP and queries by about 1000 times in extensive experiments. Our codes can be found at https://github.com/LiangSiyuan21/ GARSDC.
Learning to Accelerate Approximate Methods for Solving Integer Programming via Early Fixing
Jul 05, 2022
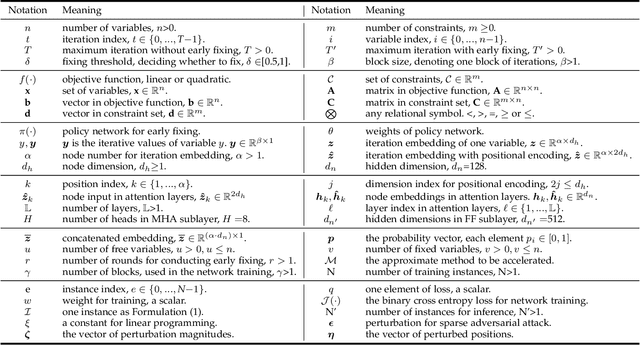
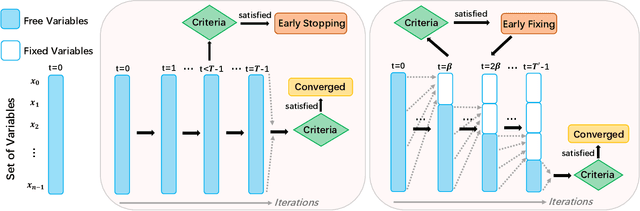

Integer programming (IP) is an important and challenging problem. Approximate methods have shown promising performance on both effectiveness and efficiency for solving the IP problem. However, we observed that a large fraction of variables solved by some iterative approximate methods fluctuate around their final converged discrete states in very long iterations. Inspired by this observation, we aim to accelerate these approximate methods by early fixing these fluctuated variables to their converged states while not significantly harming the solution accuracy. To this end, we propose an early fixing framework along with the approximate method. We formulate the whole early fixing process as a Markov decision process, and train it using imitation learning. A policy network will evaluate the posterior probability of each free variable concerning its discrete candidate states in each block of iterations. Specifically, we adopt the powerful multi-headed attention mechanism in the policy network. Extensive experiments on our proposed early fixing framework are conducted to three different IP applications: constrained linear programming, MRF energy minimization and sparse adversarial attack. The former one is linear IP problem, while the latter two are quadratic IP problems. We extend the problem scale from regular size to significantly large size. The extensive experiments reveal the competitiveness of our early fixing framework: the runtime speeds up significantly, while the solution quality does not degrade much, even in some cases it is available to obtain better solutions. Our proposed early fixing framework can be regarded as an acceleration extension of ADMM methods for solving integer programming. The source codes are available at \url{https://github.com/SCLBD/Accelerated-Lpbox-ADMM}.
Bilevel Learning Model Towards Industrial Scheduling
Aug 10, 2020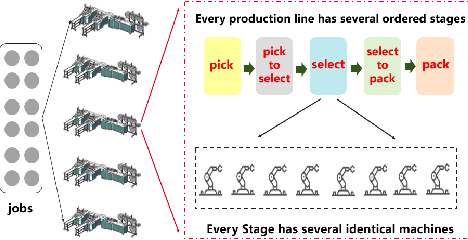
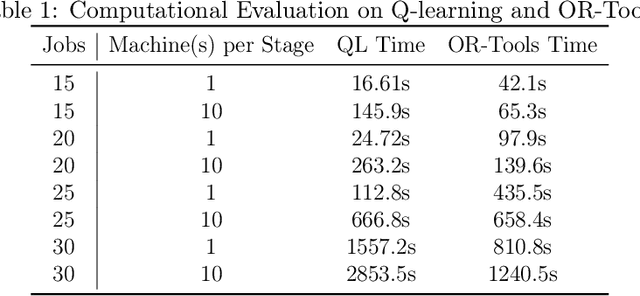
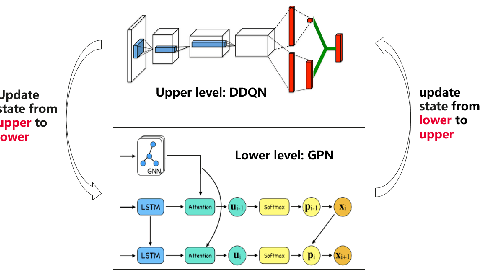
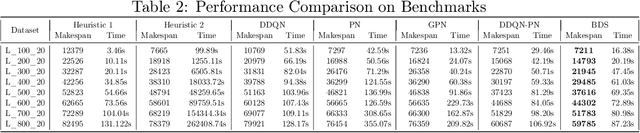
Automatic industrial scheduling, aiming at optimizing the sequence of jobs over limited resources, is widely needed in manufacturing industries. However, existing scheduling systems heavily rely on heuristic algorithms, which either generate ineffective solutions or compute inefficiently when job scale increases. Thus, it is of great importance to develop new large-scale algorithms that are not only efficient and effective, but also capable of satisfying complex constraints in practice. In this paper, we propose a Bilevel Deep reinforcement learning Scheduler, \textit{BDS}, in which the higher level is responsible for exploring an initial global sequence, whereas the lower level is aiming at exploitation for partial sequence refinements, and the two levels are connected by a sliding-window sampling mechanism. In the implementation, a Double Deep Q Network (DDQN) is used in the upper level and Graph Pointer Network (GPN) lies within the lower level. After the theoretical guarantee for the convergence of BDS, we evaluate it in an industrial automatic warehouse scenario, with job number up to $5000$ in each production line. It is shown that our proposed BDS significantly outperforms two most used heuristics, three strong deep networks, and another bilevel baseline approach. In particular, compared with the most used greedy-based heuristic algorithm in real world which takes nearly an hour, our BDS can decrease the makespan by 27.5\%, 28.6\% and 22.1\% for 3 largest datasets respectively, with computational time less than 200 seconds.