 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeking Certainty In Uncertainty: Dual-Stage Unified Framework Solving Uncertainty in Dynamic Facial Expression Recognition
Jun 24, 2024



The contemporary state-of-the-art of Dynamic Facial Expression Recognition (DFER) technology facilitates remarkable progress by deriving emotional mappings of facial expressions from video content, underpinned by training on voluminous datasets. Yet, the DFER datasets encompass a substantial volume of noise data. Noise arises from low-quality captures that defy logical labeling, and instances that suffer from mislabeling due to annotation bias, engendering two principal types of uncertainty: the uncertainty regarding data usability and the uncertainty concerning label reliability. Addressing the two types of uncertainty, we have meticulously crafted a two-stage framework aiming at \textbf{S}eeking \textbf{C}ertain data \textbf{I}n extensive \textbf{U}ncertain data (SCIU). This initiative aims to purge the DFER datasets of these uncertainties, thereby ensuring that only clean, verified data is employed in training processes. To mitigate the issue of low-quality samples, we introduce the Coarse-Grained Pruning (CGP) stage, which assesses sample weights and prunes those deemed unusable due to their low weight. For samples with incorrect annotations, the Fine-Grained Correction (FGC) stage evaluates prediction stability to rectify mislabeled data. Moreover, SCIU is conceived as a universally compatible, plug-and-play framework, tailored to integrate seamlessly with prevailing DFER methodologies. Rigorous experiments across prevalent DFER datasets and against numerous benchmark methods substantiates SCIU's capacity to markedly elevate performance metrics.
On the Transformations across Reward Model, Parameter Update, and In-Context Prompt
Jun 24, 2024Despite the general capabilities of pre-trained large language models (LLMs), they still need further adaptation to better serve practical applications. In this paper, we demonstrate the interchangeability of three popular and distinct adaptation tools: parameter updating, reward modeling, and in-context prompting. This interchangeability establishes a triangular framework with six transformation directions, each of which facilitates a variety of applications. Our work offers a holistic view that unifies numerous existing studies and suggests potential research directions. We envision our work as a useful roadmap for future research on LLMs.
Asynchronous Large Language Model Enhanced Planner for Autonomous Driving
Jun 20, 2024



Despite real-time planners exhibiting remarkable performance in autonomous driving, the growing exploration of Large Language Models (LLMs) has opened avenues for enhancing the interpretability and controllability of motion planning. Nevertheless, LLM-based planners continue to encounter significant challenges, including elevated resource consumption and extended inference times, which pose substantial obstacles to practical deployment. In light of these challenges, we introduce AsyncDriver, a new asynchronous LLM-enhanced closed-loop framework designed to leverage scene-associated instruction features produced by LLM to guide real-time planners in making precise and controllable trajectory predictions. On one hand, our method highlights the prowess of LLMs in comprehending and reasoning with vectorized scene data and a series of routing instructions, demonstrating its effective assistance to real-time planners. On the other hand, the proposed framework decouples the inference processes of the LLM and real-time planners. By capitalizing on the asynchronous nature of their inference frequencies, our approach have successfully reduced the computational cost introduced by LLM, while maintaining comparable performance. Experiments show that our approach achieves superior closed-loop evaluation performance on nuPlan's challenging scenarios.
MCAD: Multi-modal Conditioned Adversarial Diffusion Model for High-Quality PET Image Reconstruction
Jun 19, 2024Radiation hazards associated with standard-dose positron emission tomography (SPET) images remain a concern, whereas the quality of low-dose PET (LPET) images fails to meet clinical requirements. Therefore, there is great interest in reconstructing SPET images from LPET images. However, prior studies focus solely on image data, neglecting vital complementary information from other modalities, e.g., patients' clinical tabular, resulting in compromised reconstruction with limited diagnostic utility. Moreover, they often overlook the semantic consistency between real SPET and reconstructed images, leading to distorted semantic contexts. To tackle these problems, we propose a novel Multi-modal Conditioned Adversarial Diffusion model (MCAD) to reconstruct SPET images from multi-modal inputs, including LPET images and clinical tabular. Specifically, our MCAD incorporates a Multi-modal conditional Encoder (Mc-Encoder) to extract multi-modal features, followed by a conditional diffusion process to blend noise with multi-modal features and gradually map blended features to the target SPET images. To balance multi-modal inputs, the Mc-Encoder embeds Optimal Multi-modal Transport co-Attention (OMTA) to narrow the heterogeneity gap between image and tabular while capturing their interactions, providing sufficient guidance for reconstruction. In addition, to mitigate semantic distortions, we introduce the Multi-Modal Masked Text Reconstruction (M3TRec), which leverages semantic knowledge extracted from denoised PET images to restore the masked clinical tabular, thereby compelling the network to maintain accurate semantics during reconstruction. To expedite the diffusion process, we further introduce an adversarial diffusive network with a reduced number of diffusion steps. Experiments show that our method achieves the state-of-the-art performance both qualitatively and quantitatively.
AlignMMBench: Evaluating Chinese Multimodal Alignment in Large Vision-Language Models
Jun 14, 2024Evaluating the alignment capabilities of large Vision-Language Models (VLMs) is essential for determining their effectiveness as helpful assistants. However, existing benchmarks primarily focus on basic abilities using nonverbal methods, such as yes-no and multiple-choice questions. In this paper, we address this gap by introducing AlignMMBench, a comprehensive alignment benchmark specifically designed for emerging Chinese VLMs. This benchmark is meticulously curated from real-world scenarios and Chinese Internet sources, encompassing thirteen specific tasks across three categories, and includes both single-turn and multi-turn dialogue scenarios. Incorporating a prompt rewrite strategy, AlignMMBench encompasses 1,054 images and 4,978 question-answer pairs. To facilitate the evaluation pipeline, we propose CritiqueVLM, a rule-calibrated evaluator that exceeds GPT-4's evaluation ability. Finally, we report the performance of representative VLMs on AlignMMBench, offering insights into the capabilities and limitations of different VLM architectures. All evaluation codes and data are available on https://alignmmbench.github.io.
AdaRevD: Adaptive Patch Exiting Reversible Decoder Pushes the Limit of Image Deblurring
Jun 13, 2024



Despite the recent progress in enhancing the efficacy of image deblurring, the limited decoding capability constrains the upper limit of State-Of-The-Art (SOTA) methods. This paper proposes a pioneering work, Adaptive Patch Exiting Reversible Decoder (AdaRevD), to explore their insufficient decoding capability. By inheriting the weights of the well-trained encoder, we refactor a reversible decoder which scales up the single-decoder training to multi-decoder training while remaining GPU memory-friendly. Meanwhile, we show that our reversible structure gradually disentangles high-level degradation degree and low-level blur pattern (residual of the blur image and its sharp counterpart) from compact degradation representation. Besides, due to the spatially-variant motion blur kernels, different blur patches have various deblurring difficulties. We further introduce a classifier to learn the degradation degree of image patches, enabling them to exit at different sub-decoders for speedup. Experiments show that our AdaRevD pushes the limit of image deblurring, e.g., achieving 34.60 dB in PSNR on GoPro dataset.
Joint Power Allocation and Beamforming Design for Active IRS-Aided Directional Modulation Secure Systems
Jun 13, 2024



Since the secrecy rate (SR) performance improvement obtained by secure directional modulation (DM) network is limited, an active intelligent reflective surface (IRS)-assisted DM network is considered to attain a high SR. To address the SR maximization problem, a novel method based on Lagrangian dual transform and closed-form fractional programming algorithm (LDT-CFFP) is proposed, where the solutions to base station (BS) beamforming vectors and IRS reflection coefficient matrix are achieved. However, the computational complexity of LDT-CFFP method is high . To reduce its complexity, a blocked IRS-assisted DM network is designed. To meet the requirements of the network performance, a power allocation (PA) strategy is proposed and adopted in the system. Specifically, the system power between BS and IRS, as well as the transmission power for confidential messages (CM) and artificial noise (AN) from the BS, are allocated separately. Then we put forward null-space projection (NSP) method, maximum-ratio-reflecting (MRR) algorithm and PA strategy (NSP-MRR-PA) to solve the SR maximization problem. The CF solutions to BS beamforming vectors and IRS reflection coefficient matrix are respectively attained via NSP and MRR algorithms. For the PA factors, we take advantage of exhaustive search (ES) algorithm, particle swarm optimization (PSO) and simulated annealing (SA) algorithm to search for the solutions. From simulation results, it is verified that the LDT-CFFP method derives a higher SR gain over NSP-MRR-PA method. For NSP-MRR-PA method, the number of IRS units in each block possesses a significant SR performance. In addition, the application PA strategies, namely ES, PSO, SA methods outperforms the other PA strategies with fixed PA factors.
SRFUND: A Multi-Granularity Hierarchical Structure Reconstruction Benchmark in Form Understanding
Jun 13, 2024Accurately identifying and organizing textual content is crucial for the automation of document processing in the field of form understanding. Existing datasets, such as FUNSD and XFUND, support entity classification and relationship prediction tasks but are typically limited to local and entity-level annotations. This limitation overlooks the hierarchically structured representation of documents, constraining comprehensive understanding of complex forms. To address this issue, we present the SRFUND, a hierarchically structured multi-task form understanding benchmark. SRFUND provides refined annotations on top of the original FUNSD and XFUND datasets, encompassing five tasks: (1) word to text-line merging, (2) text-line to entity merging, (3) entity category classification, (4) item table localization, and (5) entity-based full-document hierarchical structure recovery. We meticulously supplemented the original dataset with missing annotations at various levels of granularity and added detailed annotations for multi-item table regions within the forms. Additionally, we introduce global hierarchical structure dependencies for entity relation prediction tasks, surpassing traditional local key-value associations. The SRFUND dataset includes eight languages including English, Chinese, Japanese, German, French, Spanish, Italian, and Portuguese, making it a powerful tool for cross-lingual form understanding. Extensive experimental results demonstrate that the SRFUND dataset presents new challenges and significant opportunities in handling diverse layouts and global hierarchical structures of forms, thus providing deep insights into the field of form understanding. The original dataset and implementations of baseline methods are available at https://sprateam-ustc.github.io/SRFUND
OUS: Scene-Guided Dynamic Facial Expression Recognition
May 29, 2024



Dynamic Facial Expression Recognition (DFER) is crucial for affective computing but often overlooks the impact of scene context. We have identified a significant issue in current DFER tasks: human annotators typically integrate emotions from various angles, including environmental cues and body language, whereas existing DFER methods tend to consider the scene as noise that needs to be filtered out, focusing solely on facial information. We refer to this as the Rigid Cognitive Problem. The Rigid Cognitive Problem can lead to discrepancies between the cognition of annotators and models in some samples. To align more closely with the human cognitive paradigm of emotions, we propose an Overall Understanding of the Scene DFER method (OUS). OUS effectively integrates scene and facial features, combining scene-specific emotional knowledge for DFER. Extensive experiments on the two largest datasets in the DFER field, DFEW and FERV39k, demonstrate that OUS significantly outperforms existing methods. By analyzing the Rigid Cognitive Problem, OUS successfully understands the complex relationship between scene context and emotional expression, closely aligning with human emotional understanding in real-world scenarios.
DiffuBox: Refining 3D Object Detection with Point Diffusion
May 25, 2024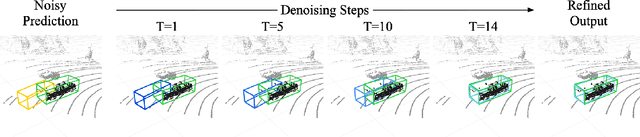
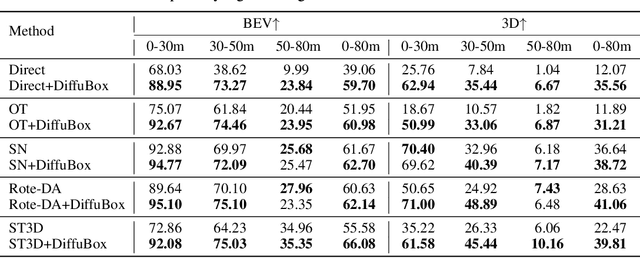
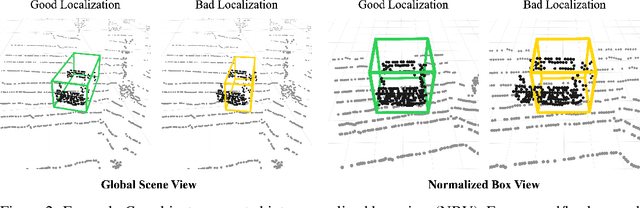
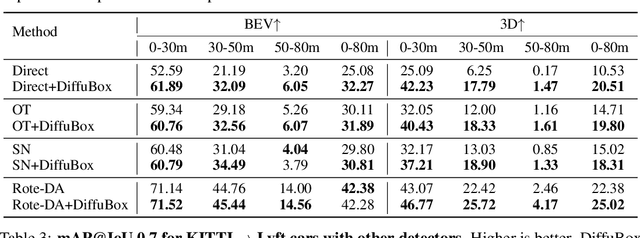
Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.