 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Semantic Graphs for Efficient and Robust LiDAR SLAM
Mar 14, 2025



Accurate and robust simultaneous localization and mapping (SLAM) is crucial for autonomous mobile systems, typically achieved by leveraging the geometric features of the environment. Incorporating semantics provides a richer scene representation that not only enhances localization accuracy in SLAM but also enables advanced cognitive functionalities for downstream navigation and planning tasks. Existing point-wise semantic LiDAR SLAM methods often suffer from poor efficiency and generalization, making them less robust in diverse real-world scenarios. In this paper, we propose a semantic graph-enhanced SLAM framework, named SG-SLAM, which effectively leverages the geometric, semantic, and topological characteristics inherent in environmental structures. The semantic graph serves as a fundamental component that facilitates critical functionalities of SLAM, including robust relocalization during odometry failures, accurate loop closing, and semantic graph map construction. Our method employs a dual-threaded architecture, with one thread dedicated to online odometry and relocalization, while the other handles loop closure, pose graph optimization, and map update. This design enables our method to operate in real time and generate globally consistent semantic graph maps and point cloud maps. We extensively evaluate our method across the KITTI, MulRAN, and Apollo datasets, and the results demonstrate its superiority compared to state-of-the-art methods. Our method has been released at https://github.com/nubot-nudt/SG-SLAM.
BEVDiffLoc: End-to-End LiDAR Global Localization in BEV View based on Diffusion Model
Mar 14, 2025



Localization is one of the core parts of modern robotics. Classic localization methods typically follow the retrieve-then-register paradigm, achieving remarkable success. Recently, the emergence of end-to-end localization approaches has offered distinct advantages, including a streamlined system architecture and the elimination of the need to store extensive map data. Although these methods have demonstrated promising results, current end-to-end localization approaches still face limitations in robustness and accuracy. Bird's-Eye-View (BEV) image is one of the most widely adopted data representations in autonomous driving. It significantly reduces data complexity while preserving spatial structure and scale consistency, making it an ideal representation for localization tasks. However, research on BEV-based end-to-end localization remains notably insufficient. To fill this gap, we propose BEVDiffLoc, a novel framework that formulates LiDAR localization as a conditional generation of poses. Leveraging the properties of BEV, we first introduce a specific data augmentation method to significantly enhance the diversity of input data. Then, the Maximum Feature Aggregation Module and Vision Transformer are employed to learn robust features while maintaining robustness against significant rotational view variations. Finally, we incorporate a diffusion model that iteratively refines the learned features to recover the absolute pose. Extensive experiments on the Oxford Radar RobotCar and NCLT datasets demonstrate that BEVDiffLoc outperforms the baseline methods. Our code is available at https://github.com/nubot-nudt/BEVDiffLoc.
Enhancing Investment Analysis: Optimizing AI-Agent Collaboration in Financial Research
Nov 07, 2024



In recent years, the application of generative artificial intelligence (GenAI) in financial analysis and investment decision-making has gained significant attention. However, most existing approaches rely on single-agent systems, which fail to fully utilize the collaborative potential of multiple AI agents. In this paper, we propose a novel multi-agent collaboration system designed to enhance decision-making in financial investment research. The system incorporates agent groups with both configurable group sizes and collaboration structures to leverage the strengths of each agent group type. By utilizing a sub-optimal combination strategy, the system dynamically adapts to varying market conditions and investment scenarios, optimizing performance across different tasks. We focus on three sub-tasks: fundamentals, market sentiment, and risk analysis, by analyzing the 2023 SEC 10-K forms of 30 companies listed on the Dow Jones Index. Our findings reveal significant performance variations based on the configurations of AI agents for different tasks. The results demonstrate that our multi-agent collaboration system outperforms traditional single-agent models, offering improved accuracy, efficiency, and adaptability in complex financial environments. This study highlights the potential of multi-agent systems in transforming financial analysis and investment decision-making by integrating diverse analytical perspectives.
SGLC: Semantic Graph-Guided Coarse-Fine-Refine Full Loop Closing for LiDAR SLAM
Jul 11, 2024



Loop closing is a crucial component in SLAM that helps eliminate accumulated errors through two main steps: loop detection and loop pose correction. The first step determines whether loop closing should be performed, while the second estimates the 6-DoF pose to correct odometry drift. Current methods mostly focus on developing robust descriptors for loop closure detection, often neglecting loop pose estimation. A few methods that do include pose estimation either suffer from low accuracy or incur high computational costs. To tackle this problem, we introduce SGLC, a real-time semantic graph-guided full loop closing method, with robust loop closure detection and 6-DoF pose estimation capabilities. SGLC takes into account the distinct characteristics of foreground and background points. For foreground instances, it builds a semantic graph that not only abstracts point cloud representation for fast descriptor generation and matching but also guides the subsequent loop verification and initial pose estimation. Background points, meanwhile, are exploited to provide more geometric features for scan-wise descriptor construction and stable planar information for further pose refinement. Loop pose estimation employs a coarse-fine-refine registration scheme that considers the alignment of both instance points and background points, offering high efficiency and accuracy. We evaluate the loop closing performance of SGLC through extensive experiments on the KITTI and KITTI-360 datasets, demonstrating its superiority over existing state-of-the-art methods. Additionally, we integrate SGLC into a SLAM system, eliminating accumulated errors and improving overall SLAM performance. The implementation of SGLC will be released at https://github.com/nubot-nudt/SGLC.
SegNet4D: Effective and Efficient 4D LiDAR Semantic Segmentation in Autonomous Driving Environments
Jun 24, 2024



4D LiDAR semantic segmentation, also referred to as multi-scan semantic segmentation, plays a crucial role in enhancing the environmental understanding capabilities of autonomous vehicles. It entails identifying the semantic category of each point in the LiDAR scan and distinguishing whether it is dynamic, a critical aspect in downstream tasks such as path planning and autonomous navigation. Existing methods for 4D semantic segmentation often rely on computationally intensive 4D convolutions for multi-scan input, resulting in poor real-time performance. In this article, we introduce SegNet4D, a novel real-time multi-scan semantic segmentation method leveraging a projection-based approach for fast motion feature encoding, showcasing outstanding performance. SegNet4D treats 4D semantic segmentation as two distinct tasks: single-scan semantic segmentation and moving object segmentation, each addressed by dedicated head. These results are then fused in the proposed motion-semantic fusion module to achieve comprehensive multi-scan semantic segmentation. Besides, we propose extracting instance information from the current scan and incorporating it into the network for instance-aware segmentation. Our approach exhibits state-of-the-art performance across multiple datasets and stands out as a real-time multi-scan semantic segmentation method. The implementation of SegNet4D will be made available at \url{https://github.com/nubot-nudt/SegNet4D}.
FinRobot: An Open-Source AI Agent Platform for Financial Applications using Large Language Models
May 23, 2024



As financial institutions and professionals increasingly incorporate Large Language Models (LLMs) into their workflows, substantial barriers, including proprietary data and specialized knowledge, persist between the finance sector and the AI community. These challenges impede the AI community's ability to enhance financial tasks effectively. Acknowledging financial analysis's critical role, we aim to devise financial-specialized LLM-based toolchains and democratize access to them through open-source initiatives, promoting wider AI adoption in financial decision-making. In this paper, we introduce FinRobot, a novel open-source AI agent platform supporting multiple financially specialized AI agents, each powered by LLM. Specifically, the platform consists of four major layers: 1) the Financial AI Agents layer that formulates Financial Chain-of-Thought (CoT) by breaking sophisticated financial problems down into logical sequences; 2) the Financial LLM Algorithms layer dynamically configures appropriate model application strategies for specific tasks; 3) the LLMOps and DataOps layer produces accurate models by applying training/fine-tuning techniques and using task-relevant data; 4) the Multi-source LLM Foundation Models layer that integrates various LLMs and enables the above layers to access them directly. Finally, FinRobot provides hands-on for both professional-grade analysts and laypersons to utilize powerful AI techniques for advanced financial analysis. We open-source FinRobot at \url{https://github.com/AI4Finance-Foundation/FinRobot}.
Diffusion-Based Point Cloud Super-Resolution for mmWave Radar Data
Apr 09, 2024The millimeter-wave radar sensor maintains stable performance under adverse environmental conditions, making it a promising solution for all-weather perception tasks, such as outdoor mobile robotics. However, the radar point clouds are relatively sparse and contain massive ghost points, which greatly limits the development of mmWave radar technology. In this paper, we propose a novel point cloud super-resolution approach for 3D mmWave radar data, named Radar-diffusion. Our approach employs the diffusion model defined by mean-reverting stochastic differential equations(SDE). Using our proposed new objective function with supervision from corresponding LiDAR point clouds, our approach efficiently handles radar ghost points and enhances the sparse mmWave radar point clouds to dense LiDAR-like point clouds. We evaluate our approach on two different datasets, and the experimental results show that our method outperforms the state-of-the-art baseline methods in 3D radar super-resolution tasks. Furthermore, we demonstrate that our enhanced radar point cloud is capable of downstream radar point-based registration tasks.
FinGPT: Instruction Tuning Benchmark for Open-Source Large Language Models in Financial Datasets
Oct 07, 2023



In the swiftly expanding domain of Natural Language Processing (NLP), the potential of GPT-based models for the financial sector is increasingly evident. However, the integration of these models with financial datasets presents challenges, notably in determining their adeptness and relevance. This paper introduces a distinctive approach anchored in the Instruction Tuning paradigm for open-source large language models, specifically adapted for financial contexts. Through this methodology, we capitalize on the interoperability of open-source models, ensuring a seamless and transparent integration. We begin by explaining the Instruction Tuning paradigm, highlighting its effectiveness for immediate integration. The paper presents a benchmarking scheme designed for end-to-end training and testing, employing a cost-effective progression. Firstly, we assess basic competencies and fundamental tasks, such as Named Entity Recognition (NER) and sentiment analysis to enhance specialization. Next, we delve into a comprehensive model, executing multi-task operations by amalgamating all instructional tunings to examine versatility. Finally, we explore the zero-shot capabilities by earmarking unseen tasks and incorporating novel datasets to understand adaptability in uncharted terrains. Such a paradigm fortifies the principles of openness and reproducibility, laying a robust foundation for future investigations in open-source financial large language models (FinLLMs).
InsMOS: Instance-Aware Moving Object Segmentation in LiDAR Data
Mar 07, 2023



Identifying moving objects is a crucial capability for autonomous navigation, consistent map generation, and future trajectory prediction of objects. In this paper, we propose a novel network that addresses the challenge of segmenting moving objects in 3D LiDAR scans. Our approach not only predicts point-wise moving labels but also detects instance information of main traffic participants. Such a design helps determine which instances are actually moving and which ones are temporarily static in the current scene. Our method exploits a sequence of point clouds as input and quantifies them into 4D voxels. We use 4D sparse convolutions to extract motion features from the 4D voxels and inject them into the current scan. Then, we extract spatio-temporal features from the current scan for instance detection and feature fusion. Finally, we design an upsample fusion module to output point-wise labels by fusing the spatio-temporal features and predicted instance information. We evaluated our approach on the LiDAR-MOS benchmark based on SemanticKITTI and achieved better moving object segmentation performance compared to state-of-the-art methods, demonstrating the effectiveness of our approach in integrating instance information for moving object segmentation. Furthermore, our method shows superior performance on the Apollo dataset with a pre-trained model on SemanticKITTI, indicating that our method generalizes well in different scenes.The code and pre-trained models of our method will be released at https://github.com/nubot-nudt/InsMOS.
Adaptive Frequency Learning in Two-branch Face Forgery Detection
Mar 27, 2022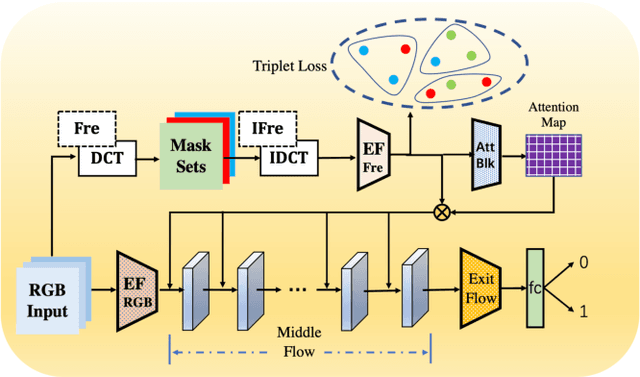
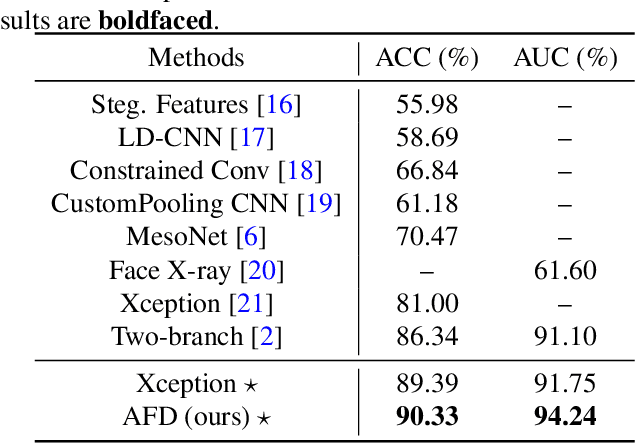
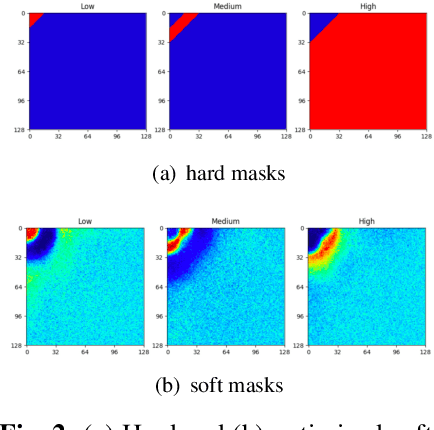
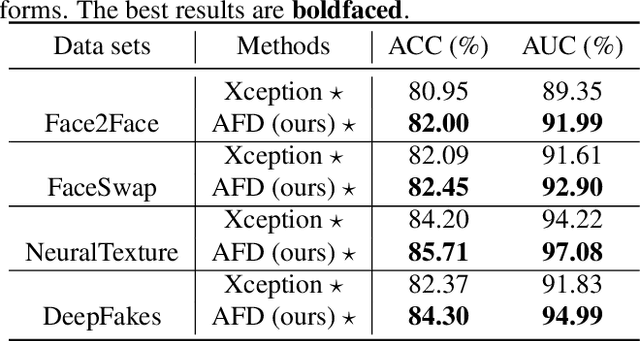
Face forgery has attracted increasing attention in recent applications of computer vision. Existing detection techniques using the two-branch framework benefit a lot from a frequency perspective, yet are restricted by their fixed frequency decomposition and transform. In this paper, we propose to Adaptively learn Frequency information in the two-branch Detection framework, dubbed AFD. To be specific, we automatically learn decomposition in the frequency domain by introducing heterogeneity constraints, and propose an attention-based module to adaptively incorporate frequency features into spatial clues. Then we liberate our network from the fixed frequency transforms, and achieve better performance with our data- and task-dependent transform layers. Extensive experiments show that AFD generally outperforms.