 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Metrics for Safety with LLM-as-Judges
Dec 17, 2025LLMs (Large Language Models) are increasingly used in text processing pipelines to intelligently respond to a variety of inputs and generation tasks. This raises the possibility of replacing human roles that bottleneck existing information flows, either due to insufficient staff or process complexity. However, LLMs make mistakes and some processing roles are safety critical. For example, triaging post-operative care to patients based on hospital referral letters, or updating site access schedules in nuclear facilities for work crews. If we want to introduce LLMs into critical information flows that were previously performed by humans, how can we make them safe and reliable? Rather than make performative claims about augmented generation frameworks or graph-based techniques, this paper argues that the safety argument should focus on the type of evidence we get from evaluation points in LLM processes, particularly in frameworks that employ LLM-as-Judges (LaJ) evaluators. This paper argues that although we cannot get deterministic evaluations from many natural language processing tasks, by adopting a basket of weighted metrics it may be possible to lower the risk of errors within an evaluation, use context sensitivity to define error severity and design confidence thresholds that trigger human review of critical LaJ judgments when concordance across evaluators is low.
MATRIX: Multi-Agent simulaTion fRamework for safe Interactions and conteXtual clinical conversational evaluation
Aug 26, 2025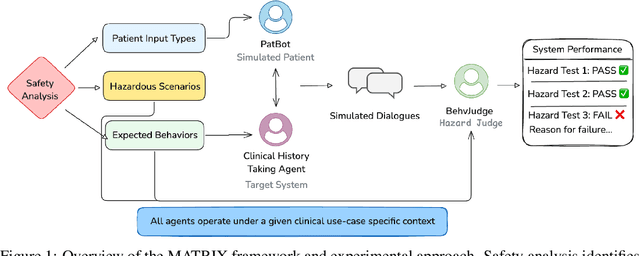


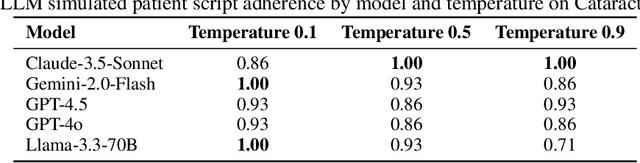
Despite the growing use of large language models (LLMs) in clinical dialogue systems, existing evaluations focus on task completion or fluency, offering little insight into the behavioral and risk management requirements essential for safety-critical systems. This paper presents MATRIX (Multi-Agent simulaTion fRamework for safe Interactions and conteXtual clinical conversational evaluation), a structured, extensible framework for safety-oriented evaluation of clinical dialogue agents. MATRIX integrates three components: (1) a safety-aligned taxonomy of clinical scenarios, expected system behaviors and failure modes derived through structured safety engineering methods; (2) BehvJudge, an LLM-based evaluator for detecting safety-relevant dialogue failures, validated against expert clinician annotations; and (3) PatBot, a simulated patient agent capable of producing diverse, scenario-conditioned responses, evaluated for realism and behavioral fidelity with human factors expertise, and a patient-preference study. Across three experiments, we show that MATRIX enables systematic, scalable safety evaluation. BehvJudge with Gemini 2.5-Pro achieves expert-level hazard detection (F1 0.96, sensitivity 0.999), outperforming clinicians in a blinded assessment of 240 dialogues. We also conducted one of the first realism analyses of LLM-based patient simulation, showing that PatBot reliably simulates realistic patient behavior in quantitative and qualitative evaluations. Using MATRIX, we demonstrate its effectiveness in benchmarking five LLM agents across 2,100 simulated dialogues spanning 14 hazard scenarios and 10 clinical domains. MATRIX is the first framework to unify structured safety engineering with scalable, validated conversational AI evaluation, enabling regulator-aligned safety auditing. We release all evaluation tools, prompts, structured scenarios, and datasets.
Metrics that matter: Evaluating image quality metrics for medical image generation
May 12, 2025Evaluating generative models for synthetic medical imaging is crucial yet challenging, especially given the high standards of fidelity, anatomical accuracy, and safety required for clinical applications. Standard evaluation of generated images often relies on no-reference image quality metrics when ground truth images are unavailable, but their reliability in this complex domain is not well established. This study comprehensively assesses commonly used no-reference image quality metrics using brain MRI data, including tumour and vascular images, providing a representative exemplar for the field. We systematically evaluate metric sensitivity to a range of challenges, including noise, distribution shifts, and, critically, localised morphological alterations designed to mimic clinically relevant inaccuracies. We then compare these metric scores against model performance on a relevant downstream segmentation task, analysing results across both controlled image perturbations and outputs from different generative model architectures. Our findings reveal significant limitations: many widely-used no-reference image quality metrics correlate poorly with downstream task suitability and exhibit a profound insensitivity to localised anatomical details crucial for clinical validity. Furthermore, these metrics can yield misleading scores regarding distribution shifts, e.g. data memorisation. This reveals the risk of misjudging model readiness, potentially leading to the deployment of flawed tools that could compromise patient safety. We conclude that ensuring generative models are truly fit for clinical purpose requires a multifaceted validation framework, integrating performance on relevant downstream tasks with the cautious interpretation of carefully selected no-reference image quality metrics.
The case for delegated AI autonomy for Human AI teaming in healthcare
Mar 24, 2025In this paper we propose an advanced approach to integrating artificial intelligence (AI) into healthcare: autonomous decision support. This approach allows the AI algorithm to act autonomously for a subset of patient cases whilst serving a supportive role in other subsets of patient cases based on defined delegation criteria. By leveraging the complementary strengths of both humans and AI, it aims to deliver greater overall performance than existing human-AI teaming models. It ensures safe handling of patient cases and potentially reduces clinician review time, whilst being mindful of AI tool limitations. After setting the approach within the context of current human-AI teaming models, we outline the delegation criteria and apply them to a specific AI-based tool used in histopathology. The potential impact of the approach and the regulatory requirements for its successful implementation are then discussed.
The Role of Explainability in Assuring Safety of Machine Learning in Healthcare
Sep 01, 2021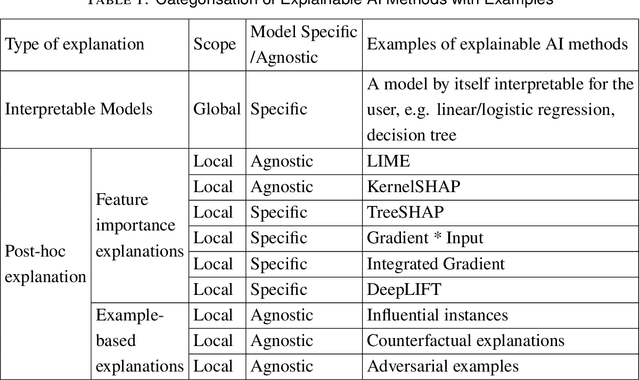
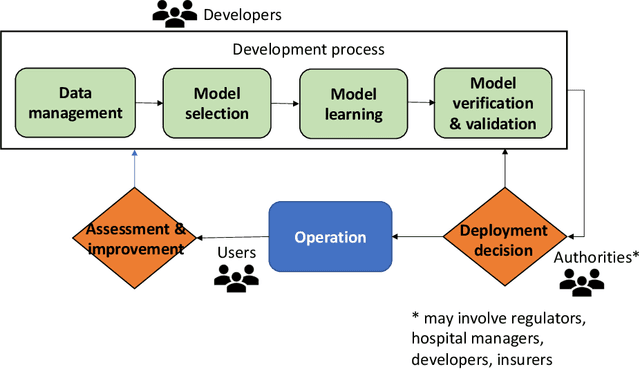
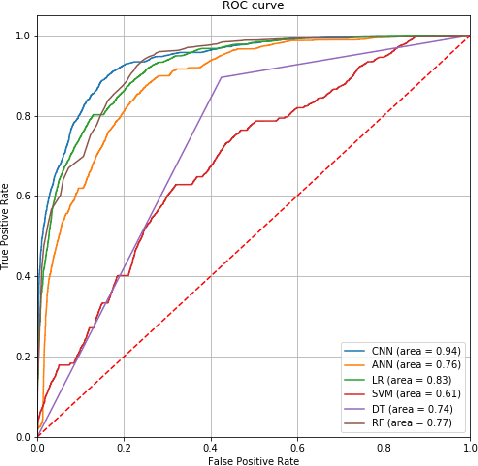
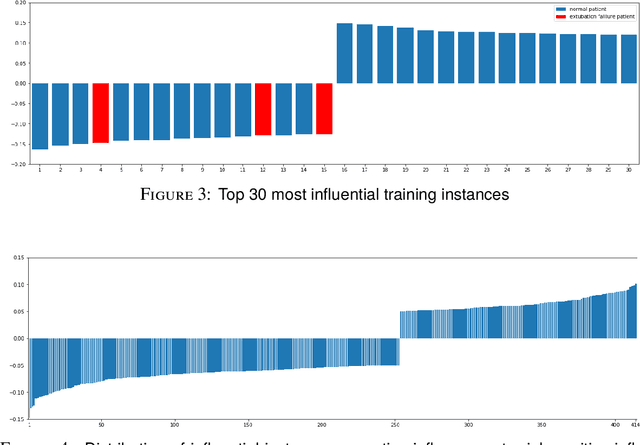
Established approaches to assuring safety-critical systems and software are difficult to apply to systems employing machine learning (ML). In many cases, ML is used on ill-defined problems, e.g. optimising sepsis treatment, where there is no clear, pre-defined specification against which to assess validity. This problem is exacerbated by the "opaque" nature of ML where the learnt model is not amenable to human scrutiny. Explainable AI methods have been proposed to tackle this issue by producing human-interpretable representations of ML models which can help users to gain confidence and build trust in the ML system. However, there is not much work explicitly investigating the role of explainability for safety assurance in the context of ML development. This paper identifies ways in which explainable AI methods can contribute to safety assurance of ML-based systems. It then uses a concrete ML-based clinical decision support system, concerning weaning of patients from mechanical ventilation, to demonstrate how explainable AI methods can be employed to produce evidence to support safety assurance. The results are also represented in a safety argument to show where, and in what way, explainable AI methods can contribute to a safety case. Overall, we conclude that explainable AI methods have a valuable role in safety assurance of ML-based systems in healthcare but that they are not sufficient in themselves to assure safety.
A Framework for Assurance of Medication Safety using Machine Learning
Jan 11, 2021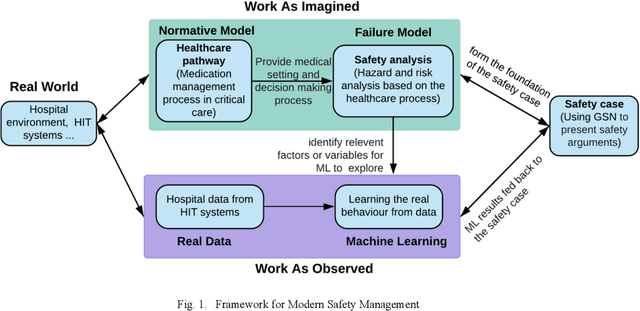
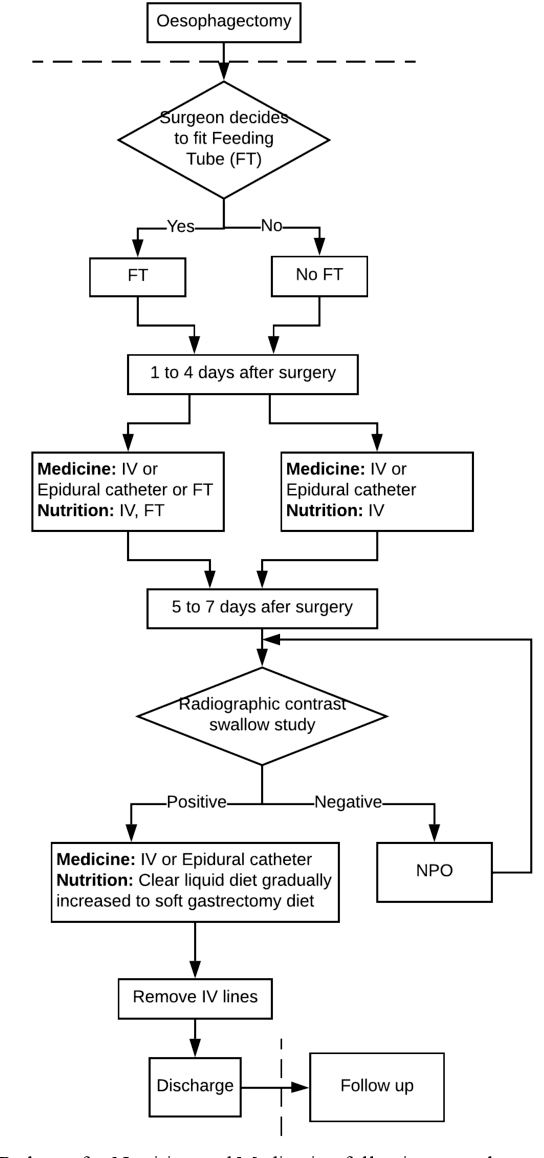
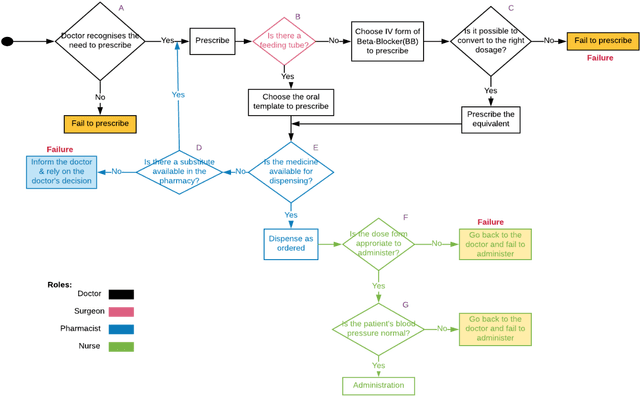
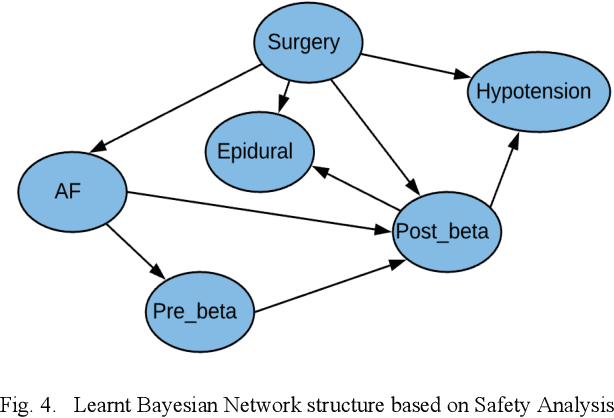
Medication errors continue to be the leading cause of avoidable patient harm in hospitals. This paper sets out a framework to assure medication safety that combines machine learning and safety engineering methods. It uses safety analysis to proactively identify potential causes of medication error, based on expert opinion. As healthcare is now data rich, it is possible to augment safety analysis with machine learning to discover actual causes of medication error from the data, and to identify where they deviate from what was predicted in the safety analysis. Combining these two views has the potential to enable the risk of medication errors to be managed proactively and dynamically. We apply the framework to a case study involving thoracic surgery, e.g. oesophagectomy, where errors in giving beta-blockers can be critical to control atrial fibrillation. This case study combines a HAZOP-based safety analysis method known as SHARD with Bayesian network structure learning and process mining to produce the analysis results, showing the potential of the framework for ensuring patient safety, and for transforming the way that safety is managed in complex healthcare environments.