 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFireRedASR2S: A State-of-the-Art Industrial-Grade All-in-One Automatic Speech Recognition System
Mar 11, 2026We present FireRedASR2S, a state-of-the-art industrial-grade all-in-one automatic speech recognition (ASR) system. It integrates four modules in a unified pipeline: ASR, Voice Activity Detection (VAD), Spoken Language Identification (LID), and Punctuation Prediction (Punc). All modules achieve SOTA performance on the evaluated benchmarks: FireRedASR2: An ASR module with two variants, FireRedASR2-LLM (8B+ parameters) and FireRedASR2-AED (1B+ parameters), supporting speech and singing transcription for Mandarin, Chinese dialects and accents, English, and code-switching. Compared to FireRedASR, FireRedASR2 delivers improved recognition accuracy and broader dialect and accent coverage. FireRedASR2-LLM achieves 2.89% average CER on 4 public Mandarin benchmarks and 11.55% on 19 public Chinese dialects and accents benchmarks, outperforming competitive baselines including Doubao-ASR, Qwen3-ASR, and Fun-ASR. FireRedVAD: An ultra-lightweight module (0.6M parameters) based on the Deep Feedforward Sequential Memory Network (DFSMN), supporting streaming VAD, non-streaming VAD, and multi-label VAD (mVAD). On the FLEURS-VAD-102 benchmark, it achieves 97.57% frame-level F1 and 99.60% AUC-ROC, outperforming Silero-VAD, TEN-VAD, FunASR-VAD, and WebRTC-VAD. FireRedLID: An Encoder-Decoder LID module supporting 100+ languages and 20+ Chinese dialects and accents. On FLEURS (82 languages), it achieves 97.18% utterance-level accuracy, outperforming Whisper and SpeechBrain. FireRedPunc: A BERT-style punctuation prediction module for Chinese and English. On multi-domain benchmarks, it achieves 78.90% average F1, outperforming FunASR-Punc (62.77%). To advance research in speech processing, we release model weights and code at https://github.com/FireRedTeam/FireRedASR2S.
Parameter-Efficient Conformers via Sharing Sparsely-Gated Experts for End-to-End Speech Recognition
Sep 17, 2022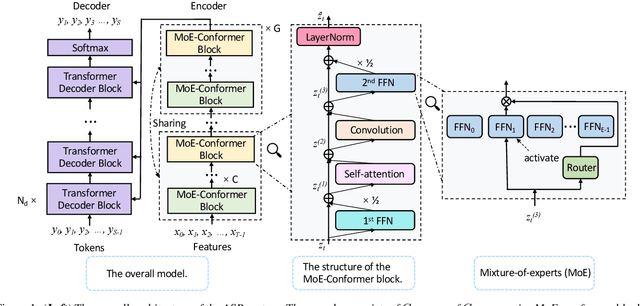
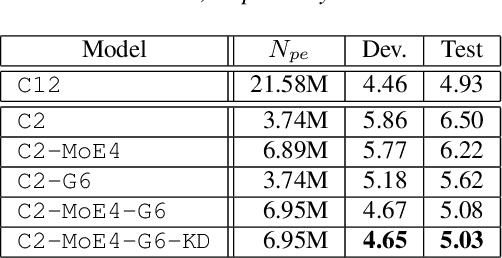
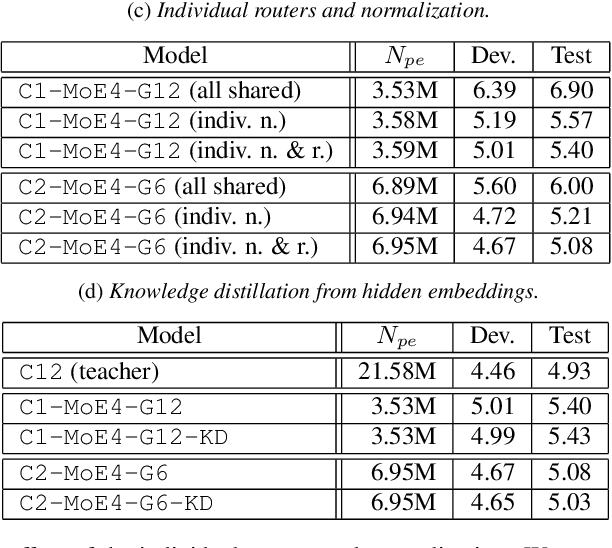
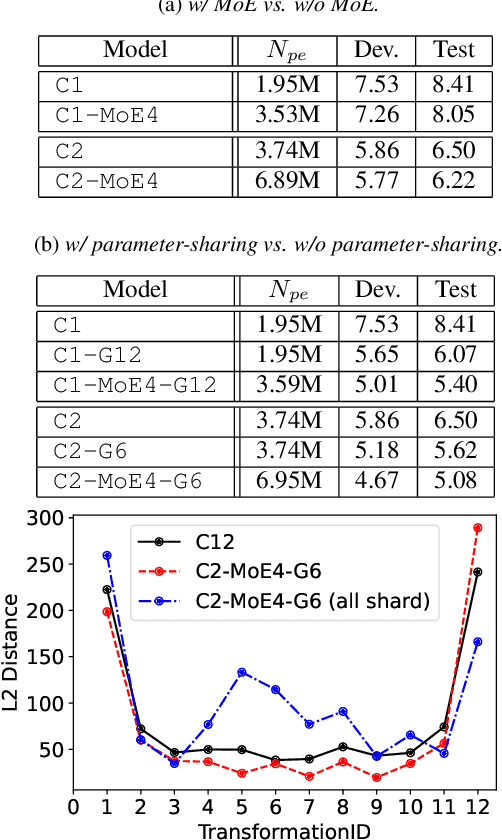
While transformers and their variant conformers show promising performance in speech recognition, the parameterized property leads to much memory cost during training and inference. Some works use cross-layer weight-sharing to reduce the parameters of the model. However, the inevitable loss of capacity harms the model performance. To address this issue, this paper proposes a parameter-efficient conformer via sharing sparsely-gated experts. Specifically, we use sparsely-gated mixture-of-experts (MoE) to extend the capacity of a conformer block without increasing computation. Then, the parameters of the grouped conformer blocks are shared so that the number of parameters is reduced. Next, to ensure the shared blocks with the flexibility of adapting representations at different levels, we design the MoE routers and normalization individually. Moreover, we use knowledge distillation to further improve the performance. Experimental results show that the proposed model achieves competitive performance with 1/3 of the parameters of the encoder, compared with the full-parameter model.