 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLemonHarness Technical Report
Jun 23, 2026As large language model (LLM) agents are applied to longer tasks, they increasingly modify workspace state across multiple rounds of iteration. However, agents typically observe only tool outputs and log fragments, while the actual state changes occur in the file system. Without explicit workspace boundaries, state-changing operations such as file writes and temporary artifact generation may scatter changes across paths. Over time, these weakly constrained changes accumulate, making states such as modified files difficult to track. This paper presents LemonHarness, an integrated execution framework for long-horizon agents. LemonHarness establishes an explicit execution boundary by constraining state-changing operations within a clearly defined workspace and bringing model invocation, tool execution, and rule knowledge within a single controlled boundary. State-changing operations, including file writes, dependency installation, and temporary artifact creation, are executed through structured tool interfaces, with execution feedback recorded as observations available to subsequent model decisions. The system also introduces a reusable rule knowledge base, which turns recurring execution rules and acceptance criteria into runtime knowledge. LemonHarness further adds a time-aware execution mechanism that exposes elapsed and remaining budget to the model, so it can rebalance exploration, implementation, and validation effort as time pressure shifts and avoid timeouts from long waits or excessive verification. On Terminal-Bench 2.0, LemonHarness_GPT-5.3-CodeX reached 84.49% accuracy over 445 trials; pairing the same framework with the stronger GPT-5.5 backbone raised the average accuracy to 86.52% across five jobs. The results suggest that a unified runtime boundary, callable rule knowledge, and time-aware execution can improve the stability of long-horizon agent execution.
Lemon Agent Technical Report
Feb 06, 2026Recent advanced LLM-powered agent systems have exhibited their remarkable capabilities in tackling complex, long-horizon tasks. Nevertheless, they still suffer from inherent limitations in resource efficiency, context management, and multimodal perception. Based on these observations, Lemon Agent is introduced, a multi-agent orchestrator-worker system built on a newly proposed AgentCortex framework, which formalizes the classic Planner-Executor-Memory paradigm through an adaptive task execution mechanism. Our system integrates a hierarchical self-adaptive scheduling mechanism that operates at both the overall orchestrator layer and workers layer. This mechanism can dynamically adjust computational intensity based on task complexity. It enables orchestrator to allocate one or more workers for parallel subtask execution, while workers can further improve operational efficiency by invoking tools concurrently. By virtue of this two-tier architecture, the system achieves synergistic balance between global task coordination and local task execution, thereby optimizing resource utilization and task processing efficiency in complex scenarios. To reduce context redundancy and increase information density during parallel steps, we adopt a three-tier progressive context management strategy. To make fuller use of historical information, we propose a self-evolving memory system, which can extract multi-dimensional valid information from all historical experiences to assist in completing similar tasks. Furthermore, we provide an enhanced MCP toolset. Empirical evaluations on authoritative benchmarks demonstrate that our Lemon Agent can achieve a state-of-the-art 91.36% overall accuracy on GAIA and secures the top position on the xbench-DeepSearch leaderboard with a score of 77+.
LeVoice ASR Systems for the ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge
Oct 17, 2022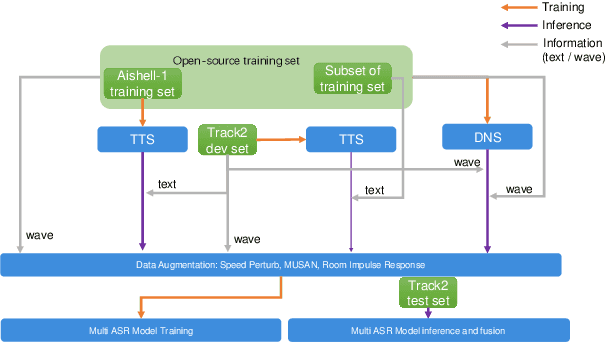
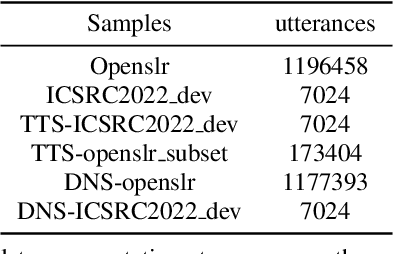
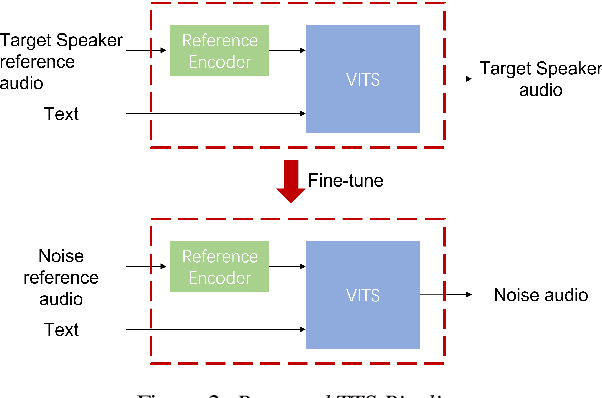
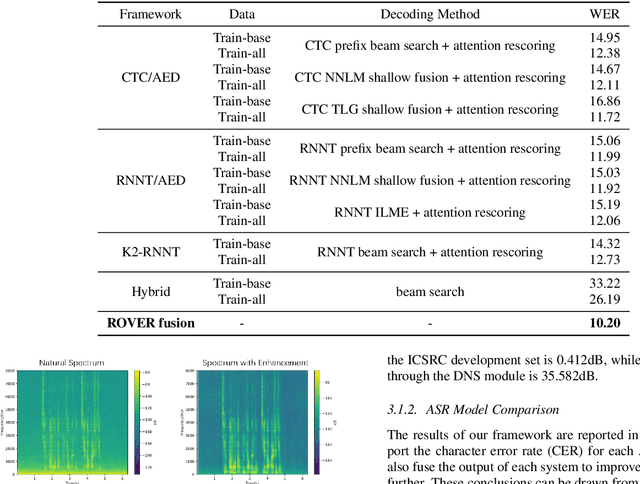
This paper describes LeVoice automatic speech recognition systems to track2 of intelligent cockpit speech recognition challenge 2022. Track2 is a speech recognition task without limits on the scope of model size. Our main points include deep learning based speech enhancement, text-to-speech based speech generation, training data augmentation via various techniques and speech recognition model fusion. We compared and fused the hybrid architecture and two kinds of end-to-end architecture. For end-to-end modeling, we used models based on connectionist temporal classification/attention-based encoder-decoder architecture and recurrent neural network transducer/attention-based encoder-decoder architecture. The performance of these models is evaluated with an additional language model to improve word error rates. As a result, our system achieved 10.2\% character error rate on the challenge test set data and ranked third place among the submitted systems in the challenge.