 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecAttn: Co-Designing Sparse Attention with Self-Speculative Decoding
Feb 06, 2026Long-context large language model (LLM) inference has become the norm for today's AI applications. However, it is severely bottlenecked by the increasing memory demands of its KV cache. Previous works have shown that self-speculative decoding with sparse attention, where tokens are drafted using a subset of the KV cache and verified in parallel with full KV cache, speeds up inference in a lossless way. However, this approach relies on standalone KV selection algorithms to select the KV entries used for drafting and overlooks that the criticality of each KV entry is inherently computed during verification. In this paper, we propose SpecAttn, a self-speculative decoding method with verification-guided sparse attention. SpecAttn identifies critical KV entries as a byproduct of verification and only loads these entries when drafting subsequent tokens. This not only improves draft token acceptance rate but also incurs low KV selection overhead, thereby improving decoding throughput. SpecAttn achieves 2.81$\times$ higher throughput over vanilla auto-regressive decoding and 1.29$\times$ improvement over state-of-the-art sparsity-based self-speculative decoding methods.
GreedySnake: Accelerating SSD-Offloaded LLM Training with Efficient Scheduling and Optimizer Step Overlapping
Dec 19, 2025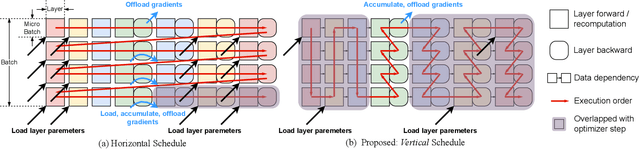
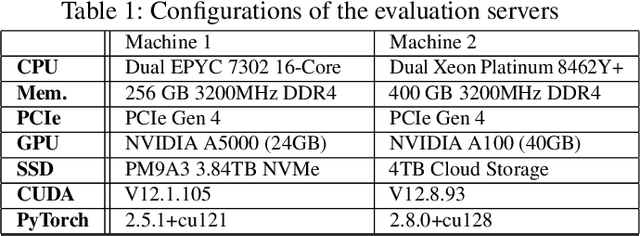
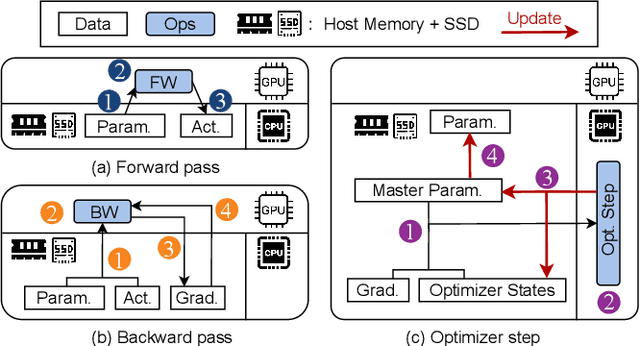
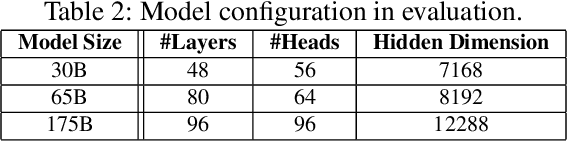
SSD-offloaded training offers a practical and promising approach to making LLM training cost-effective. Building on gradient accumulation with micro-batches, this paper introduces GreedySnake, a new SSD-offloaded training system that employs vertical scheduling, which executes all microbatches of a layer before proceeding to the next. Compared to existing systems that use horizontal scheduling (i.e., executing micro-batches sequentially), GreedySnake achieves higher training throughput with smaller batch sizes, bringing the system much closer to the ideal scenario predicted by the roofline model. To further mitigate the I/O bottleneck, GreedySnake overlaps part of the optimization step with the forward pass of the next iteration. Experimental results on A100 GPUs show that GreedySnake achieves saturated training throughput improvements over ZeRO-Infinity: 1.96x on 1 GPU and 1.93x on 4 GPUs for GPT-65B, and 2.53x on 1 GPU for GPT-175B. The code is open-sourced at https://github.com/npz7yyk/GreedySnake