 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing Spatial Reasoning in Multimodal Large Language Models via Textual Representation Guided Reasoning
Mar 24, 2026Existing Multimodal Large Language Models (MLLMs) struggle with 3D spatial reasoning, as they fail to construct structured abstractions of the 3D environment depicted in video inputs. To bridge this gap, drawing inspiration from cognitive theories of allocentric spatial reasoning, we investigate how to enable MLLMs to model and reason over text-based spatial representations of video. Specifically, we introduce Textual Representation of Allocentric Context from Egocentric Video (TRACE), a prompting method that induces MLLMs to generate text-based representations of 3D environments as intermediate reasoning traces for more accurate spatial question answering. TRACE encodes meta-context, camera trajectories, and detailed object entities to support structured spatial reasoning over egocentric videos. Extensive experiments on VSI-Bench and OST-Bench demonstrate that TRACE yields notable and consistent improvements over prior prompting strategies across a diverse range of MLLM backbones, spanning different parameter scales and training schemas. We further present ablation studies to validate our design choices, along with detailed analyses that probe the bottlenecks of 3D spatial reasoning in MLLMs.
GreedySnake: Accelerating SSD-Offloaded LLM Training with Efficient Scheduling and Optimizer Step Overlapping
Dec 19, 2025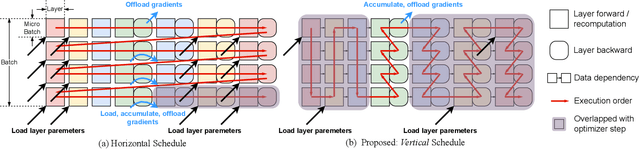
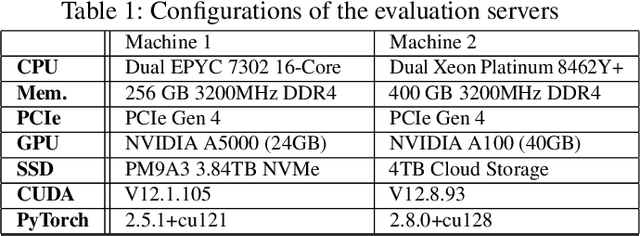
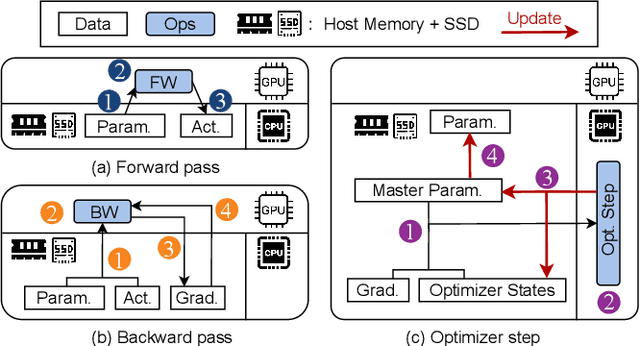
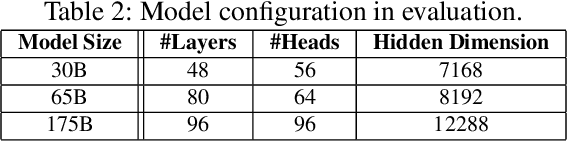
SSD-offloaded training offers a practical and promising approach to making LLM training cost-effective. Building on gradient accumulation with micro-batches, this paper introduces GreedySnake, a new SSD-offloaded training system that employs vertical scheduling, which executes all microbatches of a layer before proceeding to the next. Compared to existing systems that use horizontal scheduling (i.e., executing micro-batches sequentially), GreedySnake achieves higher training throughput with smaller batch sizes, bringing the system much closer to the ideal scenario predicted by the roofline model. To further mitigate the I/O bottleneck, GreedySnake overlaps part of the optimization step with the forward pass of the next iteration. Experimental results on A100 GPUs show that GreedySnake achieves saturated training throughput improvements over ZeRO-Infinity: 1.96x on 1 GPU and 1.93x on 4 GPUs for GPT-65B, and 2.53x on 1 GPU for GPT-175B. The code is open-sourced at https://github.com/npz7yyk/GreedySnake