 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointSee: Image Enhances Point Cloud
Nov 03, 2022



There is a trend to fuse multi-modal information for 3D object detection (3OD). However, the challenging problems of low lightweightness, poor flexibility of plug-and-play, and inaccurate alignment of features are still not well-solved, when designing multi-modal fusion newtorks. We propose PointSee, a lightweight, flexible and effective multi-modal fusion solution to facilitate various 3OD networks by semantic feature enhancement of LiDAR point clouds assembled with scene images. Beyond the existing wisdom of 3OD, PointSee consists of a hidden module (HM) and a seen module (SM): HM decorates LiDAR point clouds using 2D image information in an offline fusion manner, leading to minimal or even no adaptations of existing 3OD networks; SM further enriches the LiDAR point clouds by acquiring point-wise representative semantic features, leading to enhanced performance of existing 3OD networks. Besides the new architecture of PointSee, we propose a simple yet efficient training strategy, to ease the potential inaccurate regressions of 2D object detection networks. Extensive experiments on the popular outdoor/indoor benchmarks show numerical improvements of our PointSee over twenty-two state-of-the-arts.
Semi-UFormer: Semi-supervised Uncertainty-aware Transformer for Image Dehazing
Oct 28, 2022



Image dehazing is fundamental yet not well-solved in computer vision. Most cutting-edge models are trained in synthetic data, leading to the poor performance on real-world hazy scenarios. Besides, they commonly give deterministic dehazed images while neglecting to mine their uncertainty. To bridge the domain gap and enhance the dehazing performance, we propose a novel semi-supervised uncertainty-aware transformer network, called Semi-UFormer. Semi-UFormer can well leverage both the real-world hazy images and their uncertainty guidance information. Specifically, Semi-UFormer builds itself on the knowledge distillation framework. Such teacher-student networks effectively absorb real-world haze information for quality dehazing. Furthermore, an uncertainty estimation block is introduced into the model to estimate the pixel uncertainty representations, which is then used as a guidance signal to help the student network produce haze-free images more accurately. Extensive experiments demonstrate that Semi-UFormer generalizes well from synthetic to real-world images.
TogetherNet: Bridging Image Restoration and Object Detection Together via Dynamic Enhancement Learning
Sep 03, 2022
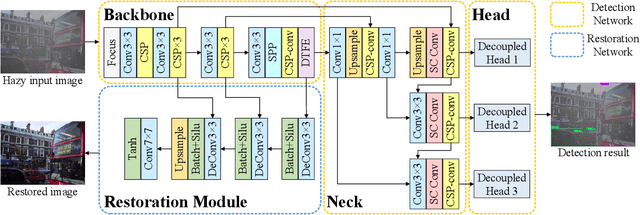
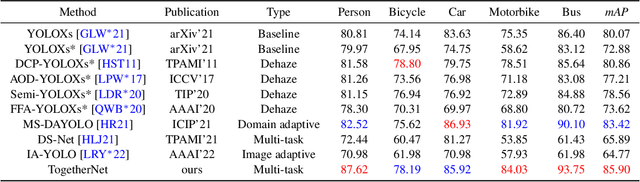
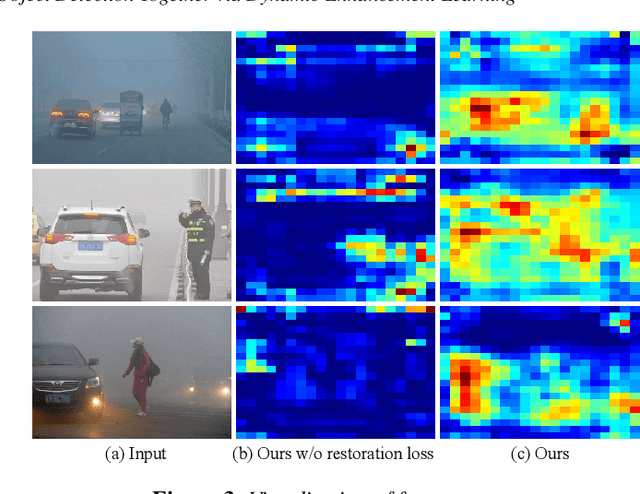
Adverse weather conditions such as haze, rain, and snow often impair the quality of captured images, causing detection networks trained on normal images to generalize poorly in these scenarios. In this paper, we raise an intriguing question - if the combination of image restoration and object detection, can boost the performance of cutting-edge detectors in adverse weather conditions. To answer it, we propose an effective yet unified detection paradigm that bridges these two subtasks together via dynamic enhancement learning to discern objects in adverse weather conditions, called TogetherNet. Different from existing efforts that intuitively apply image dehazing/deraining as a pre-processing step, TogetherNet considers a multi-task joint learning problem. Following the joint learning scheme, clean features produced by the restoration network can be shared to learn better object detection in the detection network, thus helping TogetherNet enhance the detection capacity in adverse weather conditions. Besides the joint learning architecture, we design a new Dynamic Transformer Feature Enhancement module to improve the feature extraction and representation capabilities of TogetherNet. Extensive experiments on both synthetic and real-world datasets demonstrate that our TogetherNet outperforms the state-of-the-art detection approaches by a large margin both quantitatively and qualitatively. Source code is available at https://github.com/yz-wang/TogetherNet.
Contrastive Semantic-Guided Image Smoothing Network
Sep 02, 2022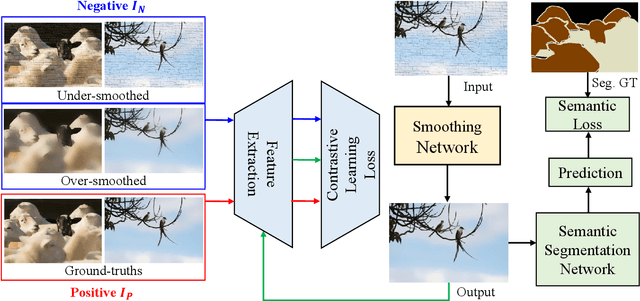
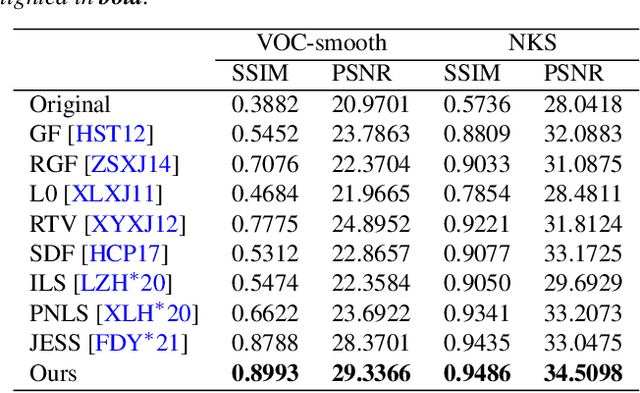
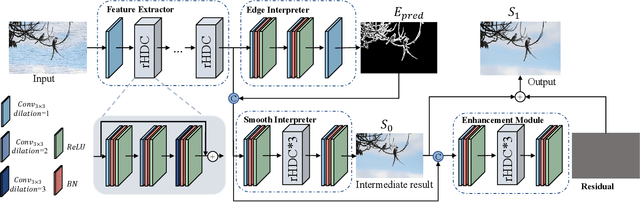

Image smoothing is a fundamental low-level vision task that aims to preserve salient structures of an image while removing insignificant details. Deep learning has been explored in image smoothing to deal with the complex entanglement of semantic structures and trivial details. However, current methods neglect two important facts in smoothing: 1) naive pixel-level regression supervised by the limited number of high-quality smoothing ground-truth could lead to domain shift and cause generalization problems towards real-world images; 2) texture appearance is closely related to object semantics, so that image smoothing requires awareness of semantic difference to apply adaptive smoothing strengths. To address these issues, we propose a novel Contrastive Semantic-Guided Image Smoothing Network (CSGIS-Net) that combines both contrastive prior and semantic prior to facilitate robust image smoothing. The supervision signal is augmented by leveraging undesired smoothing effects as negative teachers, and by incorporating segmentation tasks to encourage semantic distinctiveness. To realize the proposed network, we also enrich the original VOC dataset with texture enhancement and smoothing labels, namely VOC-smooth, which first bridges image smoothing and semantic segmentation. Extensive experiments demonstrate that the proposed CSGIS-Net outperforms state-of-the-art algorithms by a large margin. Code and dataset are available at https://github.com/wangjie6866/CSGIS-Net.
PV-RCNN++: Semantical Point-Voxel Feature Interaction for 3D Object Detection
Aug 29, 2022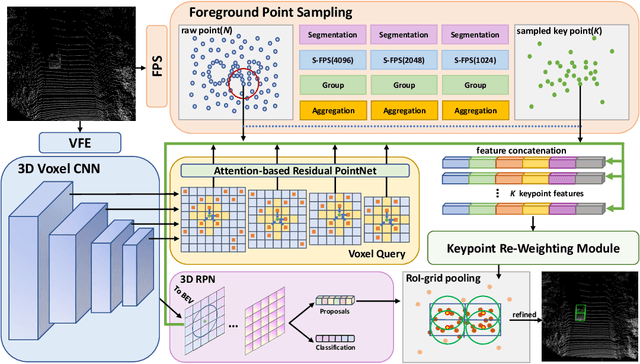
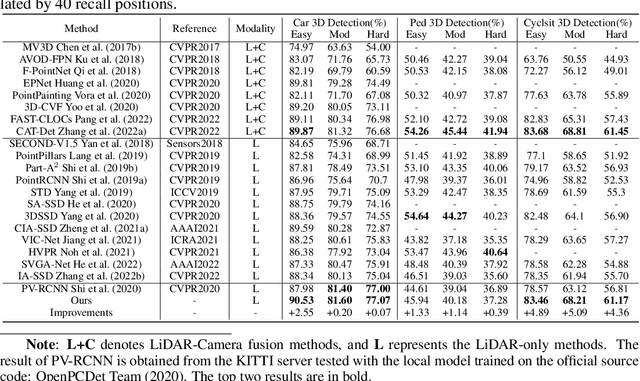
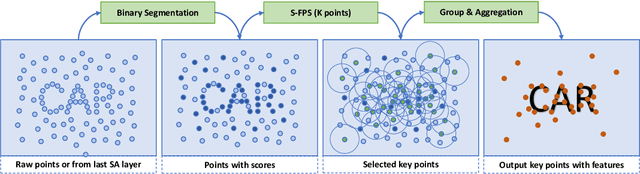
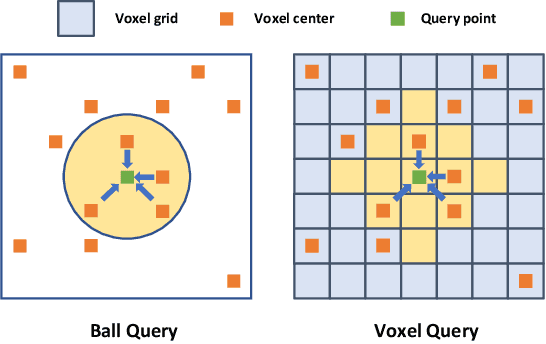
Large imbalance often exists between the foreground points (i.e., objects) and the background points in outdoor LiDAR point clouds. It hinders cutting-edge detectors from focusing on informative areas to produce accurate 3D object detection results. This paper proposes a novel object detection network by semantical point-voxel feature interaction, dubbed PV-RCNN++. Unlike most of existing methods, PV-RCNN++ explores the semantic information to enhance the quality of object detection. First, a semantic segmentation module is proposed to retain more discriminative foreground keypoints. Such a module will guide our PV-RCNN++ to integrate more object-related point-wise and voxel-wise features in the pivotal areas. Then, to make points and voxels interact efficiently, we utilize voxel query based on Manhattan distance to quickly sample voxel-wise features around keypoints. Such the voxel query will reduce the time complexity from O(N) to O(K), compared to the ball query. Further, to avoid being stuck in learning only local features, an attention-based residual PointNet module is designed to expand the receptive field to adaptively aggregate the neighboring voxel-wise features into keypoints. Extensive experiments on the KITTI dataset show that PV-RCNN++ achieves 81.60$\%$, 40.18$\%$, 68.21$\%$ 3D mAP on Car, Pedestrian, and Cyclist, achieving comparable or even better performance to the state-of-the-arts.
SO-Pose: SO-Equivariance Learning for 6D Object Pose Estimation
Aug 17, 2022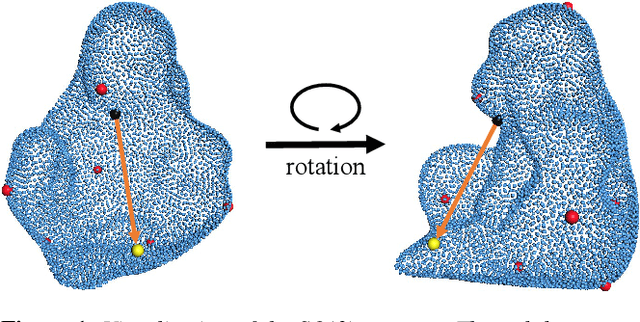
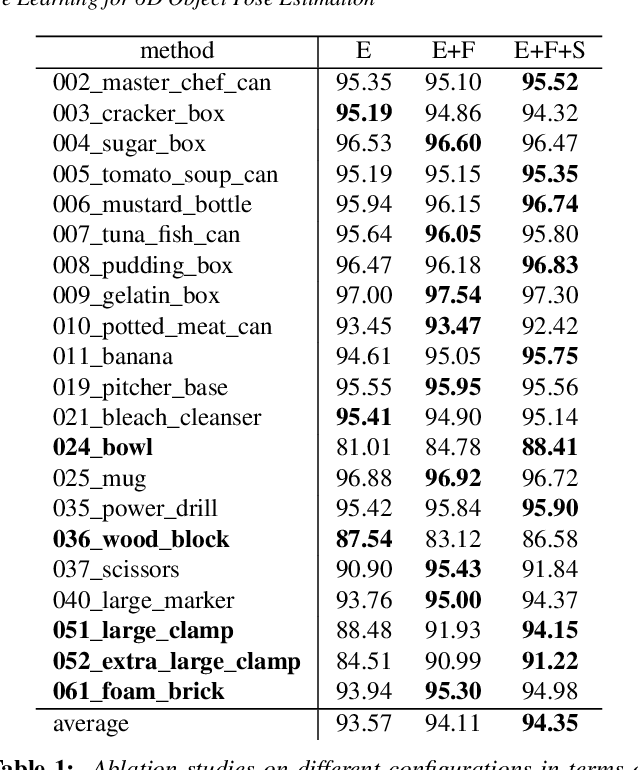

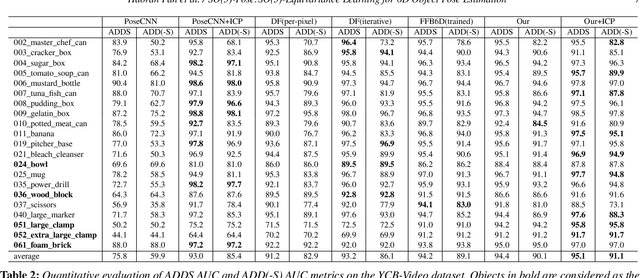
6D pose estimation of rigid objects from RGB-D images is crucial for object grasping and manipulation in robotics. Although RGB channels and the depth (D) channel are often complementary, providing respectively the appearance and geometry information, it is still non-trivial how to fully benefit from the two cross-modal data. From the simple yet new observation, when an object rotates, its semantic label is invariant to the pose while its keypoint offset direction is variant to the pose. To this end, we present SO(3)-Pose, a new representation learning network to explore SO(3)-equivariant and SO(3)-invariant features from the depth channel for pose estimation. The SO(3)-invariant features facilitate to learn more distinctive representations for segmenting objects with similar appearance from RGB channels. The SO(3)-equivariant features communicate with RGB features to deduce the (missed) geometry for detecting keypoints of an object with the reflective surface from the depth channel. Unlike most of existing pose estimation methods, our SO(3)-Pose not only implements the information communication between the RGB and depth channels, but also naturally absorbs the SO(3)-equivariance geometry knowledge from depth images, leading to better appearance and geometry representation learning. Comprehensive experiments show that our method achieves the state-of-the-art performance on three benchmarks.
UTOPIC: Uncertainty-aware Overlap Prediction Network for Partial Point Cloud Registration
Aug 12, 2022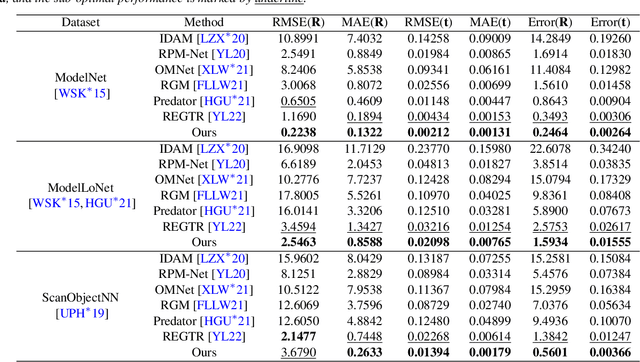
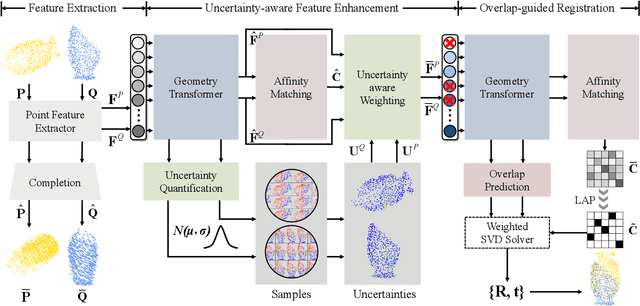
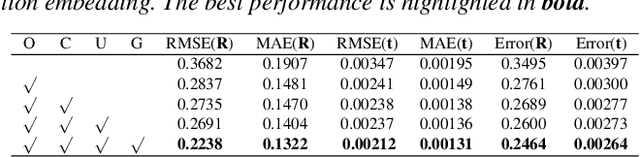
High-confidence overlap prediction and accurate correspondences are critical for cutting-edge models to align paired point clouds in a partial-to-partial manner. However, there inherently exists uncertainty between the overlapping and non-overlapping regions, which has always been neglected and significantly affects the registration performance. Beyond the current wisdom, we propose a novel uncertainty-aware overlap prediction network, dubbed UTOPIC, to tackle the ambiguous overlap prediction problem; to our knowledge, this is the first to explicitly introduce overlap uncertainty to point cloud registration. Moreover, we induce the feature extractor to implicitly perceive the shape knowledge through a completion decoder, and present a geometric relation embedding for Transformer to obtain transformation-invariant geometry-aware feature representations. With the merits of more reliable overlap scores and more precise dense correspondences, UTOPIC can achieve stable and accurate registration results, even for the inputs with limited overlapping areas. Extensive quantitative and qualitative experiments on synthetic and real benchmarks demonstrate the superiority of our approach over state-of-the-art methods.
GeoSegNet: Point Cloud Semantic Segmentation via Geometric Encoder-Decoder Modeling
Jul 14, 2022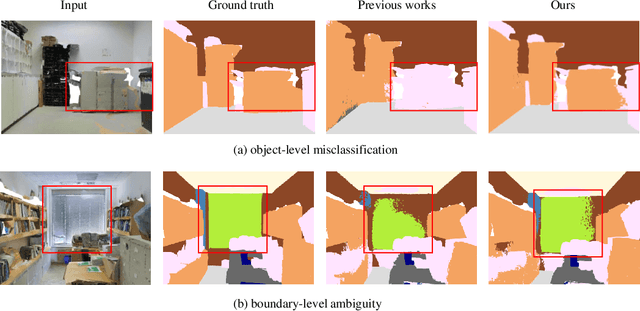
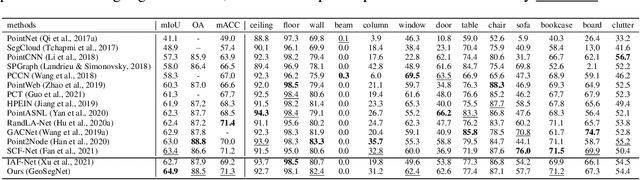
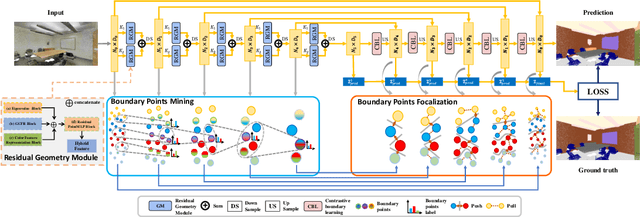
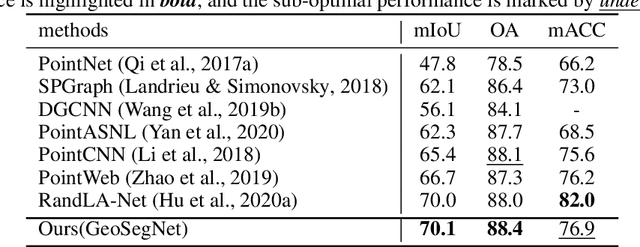
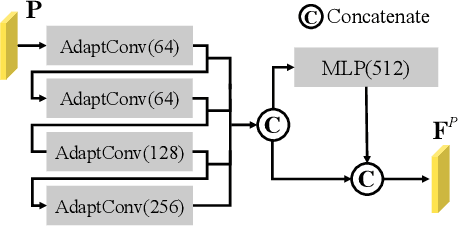
Semantic segmentation of point clouds, aiming to assign each point a semantic category, is critical to 3D scene understanding.Despite of significant advances in recent years, most of existing methods still suffer from either the object-level misclassification or the boundary-level ambiguity. In this paper, we present a robust semantic segmentation network by deeply exploring the geometry of point clouds, dubbed GeoSegNet. Our GeoSegNet consists of a multi-geometry based encoder and a boundary-guided decoder. In the encoder, we develop a new residual geometry module from multi-geometry perspectives to extract object-level features. In the decoder, we introduce a contrastive boundary learning module to enhance the geometric representation of boundary points. Benefiting from the geometric encoder-decoder modeling, our GeoSegNet can infer the segmentation of objects effectively while making the intersections (boundaries) of two or more objects clear. Experiments show obvious improvements of our method over its competitors in terms of the overall segmentation accuracy and object boundary clearness. Code is available at https://github.com/Chen-yuiyui/GeoSegNet.
AGConv: Adaptive Graph Convolution on 3D Point Clouds
Jun 09, 2022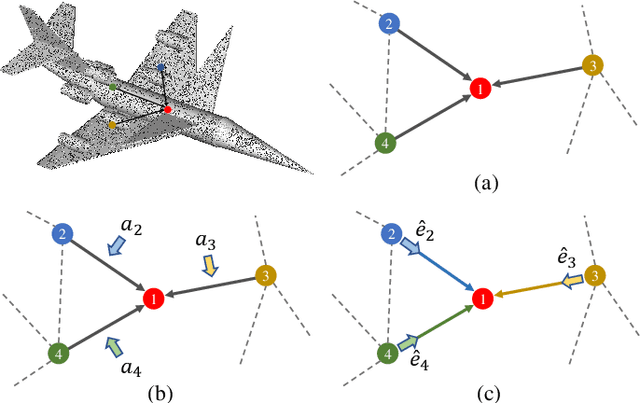

Convolution on 3D point clouds is widely researched yet far from perfect in geometric deep learning. The traditional wisdom of convolution characterises feature correspondences indistinguishably among 3D points, arising an intrinsic limitation of poor distinctive feature learning. In this paper, we propose Adaptive Graph Convolution (AGConv) for wide applications of point cloud analysis. AGConv generates adaptive kernels for points according to their dynamically learned features. Compared with the solution of using fixed/isotropic kernels, AGConv improves the flexibility of point cloud convolutions, effectively and precisely capturing the diverse relations between points from different semantic parts. Unlike the popular attentional weight schemes, AGConv implements the adaptiveness inside the convolution operation instead of simply assigning different weights to the neighboring points. Extensive evaluations clearly show that our method outperforms state-of-the-arts of point cloud classification and segmentation on various benchmark datasets.Meanwhile, AGConv can flexibly serve more point cloud analysis approaches to boost their performance. To validate its flexibility and effectiveness, we explore AGConv-based paradigms of completion, denoising, upsampling, registration and circle extraction, which are comparable or even superior to their competitors. Our code is available at https://github.com/hrzhou2/AdaptConv-master.
CF-YOLO: Cross Fusion YOLO for Object Detection in Adverse Weather with a High-quality Real Snow Dataset
Jun 03, 2022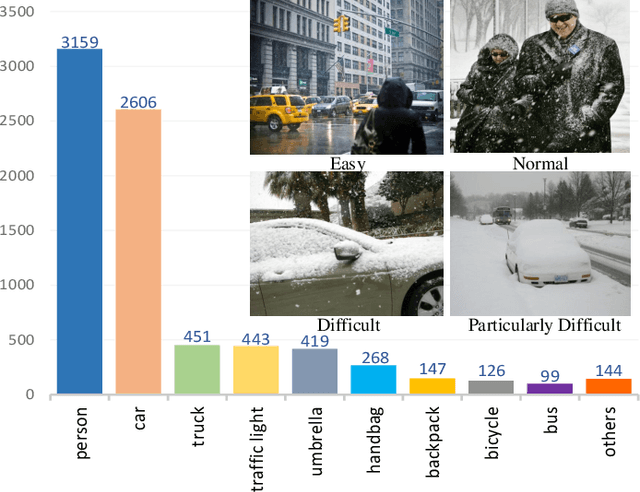
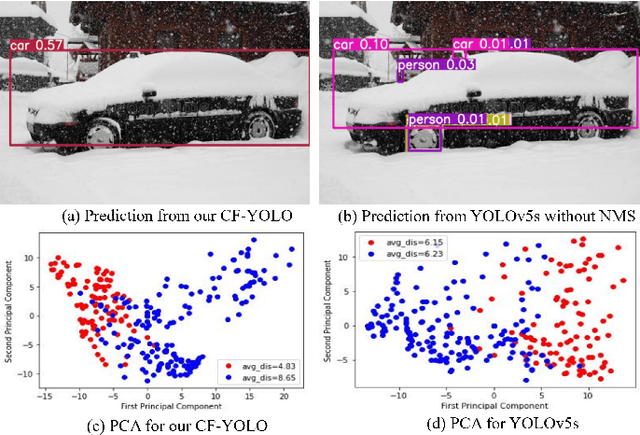
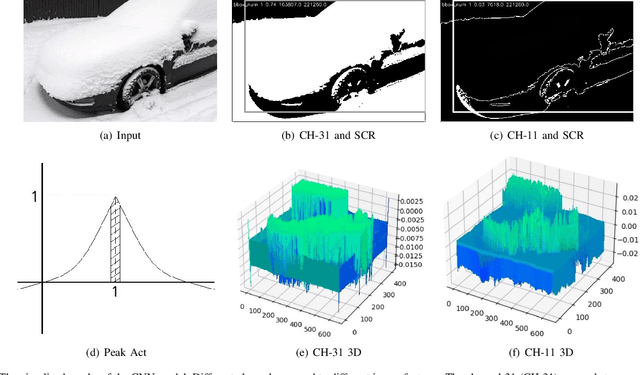
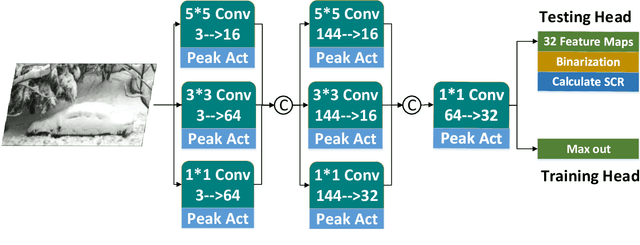
Snow is one of the toughest adverse weather conditions for object detection (OD). Currently, not only there is a lack of snowy OD datasets to train cutting-edge detectors, but also these detectors have difficulties learning latent information beneficial for detection in snow. To alleviate the two above problems, we first establish a real-world snowy OD dataset, named RSOD. Besides, we develop an unsupervised training strategy with a distinctive activation function, called $Peak \ Act$, to quantitatively evaluate the effect of snow on each object. Peak Act helps grading the images in RSOD into four-difficulty levels. To our knowledge, RSOD is the first quantitatively evaluated and graded snowy OD dataset. Then, we propose a novel Cross Fusion (CF) block to construct a lightweight OD network based on YOLOv5s (call CF-YOLO). CF is a plug-and-play feature aggregation module, which integrates the advantages of Feature Pyramid Network and Path Aggregation Network in a simpler yet more flexible form. Both RSOD and CF lead our CF-YOLO to possess an optimization ability for OD in real-world snow. That is, CF-YOLO can handle unfavorable detection problems of vagueness, distortion and covering of snow. Experiments show that our CF-YOLO achieves better detection results on RSOD, compared to SOTAs. The code and dataset are available at https://github.com/qqding77/CF-YOLO-and-RSOD.