 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeep the Core: Adversarial Priors for Significance-Preserving Brain MRI Segmentation
Dec 17, 2025



Medical image segmentation is constrained by sparse pathological annotations. Existing augmentation strategies, from conventional transforms to random masking for self-supervision, are feature-agnostic: they often corrupt critical diagnostic semantics or fail to prioritize essential features. We introduce "Keep the Core," a novel data-centric paradigm that uses adversarial priors to guide both augmentation and masking in a significance-preserving manner. Our approach uses SAGE (Sparse Adversarial Gated Estimator), an offline module identifying minimal tokens whose micro-perturbation flips segmentation boundaries. SAGE forges the Token Importance Map $W$ by solving an adversarial optimization problem to maximally degrade performance, while an $\ell_1$ sparsity penalty encourages a compact set of sensitive tokens. The online KEEP (Key-region Enhancement \& Preservation) module uses $W$ for a two-pronged augmentation strategy: (1) Semantic-Preserving Augmentation: High-importance tokens are augmented, but their original pixel values are strictly restored. (2) Guided-Masking Augmentation: Low-importance tokens are selectively masked for an $\text{MAE}$-style reconstruction, forcing the model to learn robust representations from preserved critical features. "Keep the Core" is backbone-agnostic with no inference overhead. Extensive experiments show SAGE's structured priors and KEEP's region-selective mechanism are highly complementary, achieving state-of-the-art segmentation robustness and generalization on 2D medical datasets.
Minkowski-MambaNet: A Point Cloud Framework with Selective State Space Models for Forest Biomass Quantification
Oct 10, 2025Accurate forest biomass quantification is vital for carbon cycle monitoring. While airborne LiDAR excels at capturing 3D forest structure, directly estimating woody volume and Aboveground Biomass (AGB) from point clouds is challenging due to difficulties in modeling long-range dependencies needed to distinguish trees.We propose Minkowski-MambaNet, a novel deep learning framework that directly estimates volume and AGB from raw LiDAR. Its key innovation is integrating the Mamba model's Selective State Space Model (SSM) into a Minkowski network, enabling effective encoding of global context and long-range dependencies for improved tree differentiation. Skip connections are incorporated to enhance features and accelerate convergence.Evaluated on Danish National Forest Inventory LiDAR data, Minkowski-MambaNet significantly outperforms state-of-the-art methods, providing more accurate and robust estimates. Crucially, it requires no Digital Terrain Model (DTM) and is robust to boundary artifacts. This work offers a powerful tool for large-scale forest biomass analysis, advancing LiDAR-based forest inventories.
ZigzagPointMamba: Spatial-Semantic Mamba for Point Cloud Understanding
May 27, 2025State Space models (SSMs) such as PointMamba enable efficient feature extraction for point cloud self-supervised learning with linear complexity, outperforming Transformers in computational efficiency. However, existing PointMamba-based methods depend on complex token ordering and random masking, which disrupt spatial continuity and local semantic correlations. We propose ZigzagPointMamba to tackle these challenges. The core of our approach is a simple zigzag scan path that globally sequences point cloud tokens, enhancing spatial continuity by preserving the proximity of spatially adjacent point tokens. Nevertheless, random masking undermines local semantic modeling in self-supervised learning. To address this, we introduce a Semantic-Siamese Masking Strategy (SMS), which masks semantically similar tokens to facilitate reconstruction by integrating local features of original and similar tokens. This overcomes the dependence on isolated local features and enables robust global semantic modeling. Our pre-trained ZigzagPointMamba weights significantly improve downstream tasks, achieving a 1.59% mIoU gain on ShapeNetPart for part segmentation, a 0.4% higher accuracy on ModelNet40 for classification, and 0.19%, 1.22%, and 0.72% higher accuracies respectively for the classification tasks on the OBJ-BG, OBJ-ONLY, and PB-T50-RS subsets of ScanObjectNN. The code is available at: https://anonymous.4open.science/r/ZigzagPointMamba-1800/
Spiking PointNet: Spiking Neural Networks for Point Clouds
Oct 10, 2023



Recently, Spiking Neural Networks (SNNs), enjoying extreme energy efficiency, have drawn much research attention on 2D visual recognition and shown gradually increasing application potential. However, it still remains underexplored whether SNNs can be generalized to 3D recognition. To this end, we present Spiking PointNet in the paper, the first spiking neural model for efficient deep learning on point clouds. We discover that the two huge obstacles limiting the application of SNNs in point clouds are: the intrinsic optimization obstacle of SNNs that impedes the training of a big spiking model with large time steps, and the expensive memory and computation cost of PointNet that makes training a big spiking point model unrealistic. To solve the problems simultaneously, we present a trained-less but learning-more paradigm for Spiking PointNet with theoretical justifications and in-depth experimental analysis. In specific, our Spiking PointNet is trained with only a single time step but can obtain better performance with multiple time steps inference, compared to the one trained directly with multiple time steps. We conduct various experiments on ModelNet10, ModelNet40 to demonstrate the effectiveness of Spiking PointNet. Notably, our Spiking PointNet even can outperform its ANN counterpart, which is rare in the SNN field thus providing a potential research direction for the following work. Moreover, Spiking PointNet shows impressive speedup and storage saving in the training phase.
GeoSegNet: Point Cloud Semantic Segmentation via Geometric Encoder-Decoder Modeling
Jul 14, 2022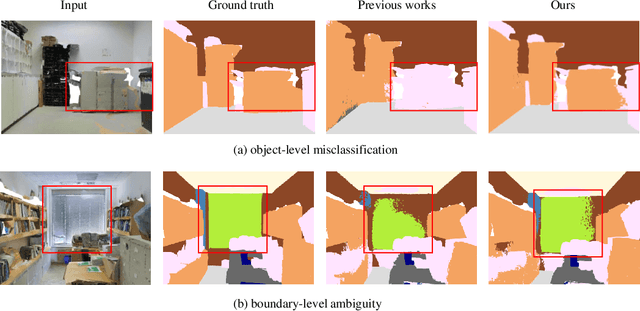
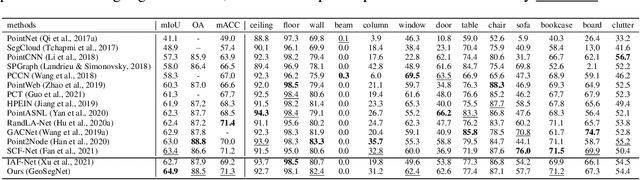
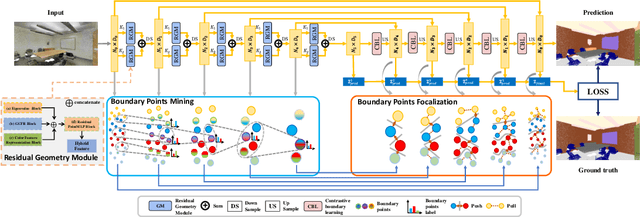
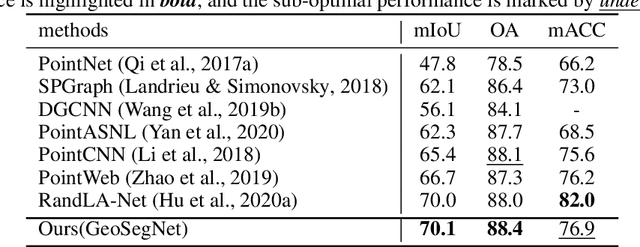
Semantic segmentation of point clouds, aiming to assign each point a semantic category, is critical to 3D scene understanding.Despite of significant advances in recent years, most of existing methods still suffer from either the object-level misclassification or the boundary-level ambiguity. In this paper, we present a robust semantic segmentation network by deeply exploring the geometry of point clouds, dubbed GeoSegNet. Our GeoSegNet consists of a multi-geometry based encoder and a boundary-guided decoder. In the encoder, we develop a new residual geometry module from multi-geometry perspectives to extract object-level features. In the decoder, we introduce a contrastive boundary learning module to enhance the geometric representation of boundary points. Benefiting from the geometric encoder-decoder modeling, our GeoSegNet can infer the segmentation of objects effectively while making the intersections (boundaries) of two or more objects clear. Experiments show obvious improvements of our method over its competitors in terms of the overall segmentation accuracy and object boundary clearness. Code is available at https://github.com/Chen-yuiyui/GeoSegNet.