 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCE-MAE: Selective Correspondence Enhancement with Masked Autoencoder for Self-Supervised Landmark Estimation
May 28, 2024Self-supervised landmark estimation is a challenging task that demands the formation of locally distinct feature representations to identify sparse facial landmarks in the absence of annotated data. To tackle this task, existing state-of-the-art (SOTA) methods (1) extract coarse features from backbones that are trained with instance-level self-supervised learning (SSL) paradigms, which neglect the dense prediction nature of the task, (2) aggregate them into memory-intensive hypercolumn formations, and (3) supervise lightweight projector networks to naively establish full local correspondences among all pairs of spatial features. In this paper, we introduce SCE-MAE, a framework that (1) leverages the MAE, a region-level SSL method that naturally better suits the landmark prediction task, (2) operates on the vanilla feature map instead of on expensive hypercolumns, and (3) employs a Correspondence Approximation and Refinement Block (CARB) that utilizes a simple density peak clustering algorithm and our proposed Locality-Constrained Repellence Loss to directly hone only select local correspondences. We demonstrate through extensive experiments that SCE-MAE is highly effective and robust, outperforming existing SOTA methods by large margins of approximately 20%-44% on the landmark matching and approximately 9%-15% on the landmark detection tasks.
Decompose the Sounds and Pixels, Recompose the Events
Dec 21, 2021

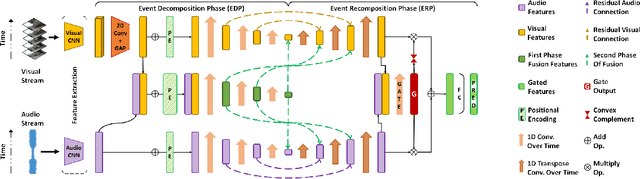
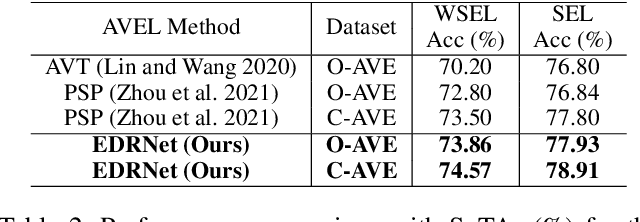
In this paper, we propose a framework centering around a novel architecture called the Event Decomposition Recomposition Network (EDRNet) to tackle the Audio-Visual Event (AVE) localization problem in the supervised and weakly supervised settings. AVEs in the real world exhibit common unravelling patterns (termed as Event Progress Checkpoints (EPC)), which humans can perceive through the cooperation of their auditory and visual senses. Unlike earlier methods which attempt to recognize entire event sequences, the EDRNet models EPCs and inter-EPC relationships using stacked temporal convolutions. Based on the postulation that EPC representations are theoretically consistent for an event category, we introduce the State Machine Based Video Fusion, a novel augmentation technique that blends source videos using different EPC template sequences. Additionally, we design a new loss function called the Land-Shore-Sea loss to compactify continuous foreground and background representations. Lastly, to alleviate the issue of confusing events during weak supervision, we propose a prediction stabilization method called Bag to Instance Label Correction. Experiments on the AVE dataset show that our collective framework outperforms the state-of-the-art by a sizable margin.