 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerGenie: Analytically-Guided Evolutionary Discovery of Superior Reconfigurable Power Converters
Jan 29, 2026Discovering superior circuit topologies requires navigating an exponentially large design space-a challenge traditionally reserved for human experts. Existing AI methods either select from predefined templates or generate novel topologies at a limited scale without rigorous verification, leaving large-scale performance-driven discovery underexplored. We present PowerGenie, a framework for automated discovery of higher-performance reconfigurable power converters at scale. PowerGenie introduces: (1) an automated analytical framework that determines converter functionality and theoretical performance limits without component sizing or SPICE simulation, and (2) an evolutionary finetuning method that co-evolves a generative model with its training distribution through fitness selection and uniqueness verification. Unlike existing methods that suffer from mode collapse and overfitting, our approach achieves higher syntax validity, function validity, novelty rate, and figure-of-merit (FoM). PowerGenie discovers a novel 8-mode reconfigurable converter with 23% higher FoM than the best training topology. SPICE simulations confirm average absolute efficiency gains of 10% across 8 modes and up to 17% at a single mode. Code is available at https://github.com/xz-group/PowerGenie.
Just-In-Time Reinforcement Learning: Continual Learning in LLM Agents Without Gradient Updates
Jan 26, 2026While Large Language Model (LLM) agents excel at general tasks, they inherently struggle with continual adaptation due to the frozen weights after deployment. Conventional reinforcement learning (RL) offers a solution but incurs prohibitive computational costs and the risk of catastrophic forgetting. We introduce Just-In-Time Reinforcement Learning (JitRL), a training-free framework that enables test-time policy optimization without any gradient updates. JitRL maintains a dynamic, non-parametric memory of experiences and retrieves relevant trajectories to estimate action advantages on-the-fly. These estimates are then used to directly modulate the LLM's output logits. We theoretically prove that this additive update rule is the exact closed-form solution to the KL-constrained policy optimization objective. Extensive experiments on WebArena and Jericho demonstrate that JitRL establishes a new state-of-the-art among training-free methods. Crucially, JitRL outperforms the performance of computationally expensive fine-tuning methods (e.g., WebRL) while reducing monetary costs by over 30 times, offering a scalable path for continual learning agents. The code is available at https://github.com/liushiliushi/JitRL.
AnalogSAGE: Self-evolving Analog Design Multi-Agents with Stratified Memory and Grounded Experience
Dec 27, 2025Analog circuit design remains a knowledge- and experience-intensive process that relies heavily on human intuition for topology generation and device parameter tuning. Existing LLM-based approaches typically depend on prompt-driven netlist generation or predefined topology templates, limiting their ability to satisfy complex specification requirements. We propose AnalogSAGE, an open-source self-evolving multi-agent framework that coordinates three-stage agent explorations through four stratified memory layers, enabling iterative refinement with simulation-grounded feedback. To support reproducibility and generality, we release the source code. Our benchmark spans ten specification-driven operational amplifier design problems of varying difficulty, enabling quantitative and cross-task comparison under identical conditions. Evaluated under the open-source SKY130 PDK with ngspice, AnalogSAGE achieves a 10$\times$ overall pass rate, a 48$\times$ Pass@1, and a 4$\times$ reduction in parameter search space compared with existing frameworks, demonstrating that stratified memory and grounded reasoning substantially enhance the reliability and autonomy of analog design automation in practice.
MASim: Multilingual Agent-Based Simulation for Social Science
Dec 08, 2025



Multi-agent role-playing has recently shown promise for studying social behavior with language agents, but existing simulations are mostly monolingual and fail to model cross-lingual interaction, an essential property of real societies. We introduce MASim, the first multilingual agent-based simulation framework that supports multi-turn interaction among generative agents with diverse sociolinguistic profiles. MASim offers two key analyses: (i) global public opinion modeling, by simulating how attitudes toward open-domain hypotheses evolve across languages and cultures, and (ii) media influence and information diffusion, via autonomous news agents that dynamically generate content and shape user behavior. To instantiate simulations, we construct the MAPS benchmark, which combines survey questions and demographic personas drawn from global population distributions. Experiments on calibration, sensitivity, consistency, and cultural case studies show that MASim reproduces sociocultural phenomena and highlights the importance of multilingual simulation for scalable, controlled computational social science.
Synergy over Discrepancy: A Partition-Based Approach to Multi-Domain LLM Fine-Tuning
Nov 11, 2025



Large language models (LLMs) demonstrate impressive generalization abilities, yet adapting them effectively across multiple heterogeneous domains remains challenging due to inter-domain interference. To overcome this challenge, we propose a partition-based multi-stage fine-tuning framework designed to exploit inter-domain synergies while minimizing negative transfer. Our approach strategically partitions domains into subsets (stages) by balancing domain discrepancy, synergy, and model capacity constraints. We theoretically analyze the proposed framework and derive novel generalization bounds that justify our partitioning strategy. Extensive empirical evaluations on various language understanding tasks show that our method consistently outperforms state-of-the-art baselines.
Aligning by Misaligning: Boundary-aware Curriculum Learning for Multimodal Alignment
Nov 11, 2025Most multimodal models treat every negative pair alike, ignoring the ambiguous negatives that differ from the positive by only a small detail. We propose Boundary-Aware Curriculum with Local Attention (BACL), a lightweight add-on that turns these borderline cases into a curriculum signal. A Boundary-aware Negative Sampler gradually raises difficulty, while a Contrastive Local Attention loss highlights where the mismatch occurs. The two modules are fully differentiable and work with any off-the-shelf dual encoder. Theory predicts a fast O(1/n) error rate; practice shows up to +32% R@1 over CLIP and new SOTA on four large-scale benchmarks, all without extra labels.
ZeroSim: Zero-Shot Analog Circuit Evaluation with Unified Transformer Embeddings
Nov 10, 2025Although recent advancements in learning-based analog circuit design automation have tackled tasks such as topology generation, device sizing, and layout synthesis, efficient performance evaluation remains a major bottleneck. Traditional SPICE simulations are time-consuming, while existing machine learning methods often require topology-specific retraining or manual substructure segmentation for fine-tuning, hindering scalability and adaptability. In this work, we propose ZeroSim, a transformer-based performance modeling framework designed to achieve robust in-distribution generalization across trained topologies under novel parameter configurations and zero-shot generalization to unseen topologies without any fine-tuning. We apply three key enabling strategies: (1) a diverse training corpus of 3.6 million instances covering over 60 amplifier topologies, (2) unified topology embeddings leveraging global-aware tokens and hierarchical attention to robustly generalize to novel circuits, and (3) a topology-conditioned parameter mapping approach that maintains consistent structural representations independent of parameter variations. Our experimental results demonstrate that ZeroSim significantly outperforms baseline models such as multilayer perceptrons, graph neural networks and transformers, delivering accurate zero-shot predictions across different amplifier topologies. Additionally, when integrated into a reinforcement learning-based parameter optimization pipeline, ZeroSim achieves a remarkable speedup (13x) compared to conventional SPICE simulations, underscoring its practical value for a wide range of analog circuit design automation tasks.
CircuitSense: A Hierarchical Circuit System Benchmark Bridging Visual Comprehension and Symbolic Reasoning in Engineering Design Process
Sep 26, 2025Engineering design operates through hierarchical abstraction from system specifications to component implementations, requiring visual understanding coupled with mathematical reasoning at each level. While Multi-modal Large Language Models (MLLMs) excel at natural image tasks, their ability to extract mathematical models from technical diagrams remains unexplored. We present \textbf{CircuitSense}, a comprehensive benchmark evaluating circuit understanding across this hierarchy through 8,006+ problems spanning component-level schematics to system-level block diagrams. Our benchmark uniquely examines the complete engineering workflow: Perception, Analysis, and Design, with a particular emphasis on the critical but underexplored capability of deriving symbolic equations from visual inputs. We introduce a hierarchical synthetic generation pipeline consisting of a grid-based schematic generator and a block diagram generator with auto-derived symbolic equation labels. Comprehensive evaluation of six state-of-the-art MLLMs, including both closed-source and open-source models, reveals fundamental limitations in visual-to-mathematical reasoning. Closed-source models achieve over 85\% accuracy on perception tasks involving component recognition and topology identification, yet their performance on symbolic derivation and analytical reasoning falls below 19\%, exposing a critical gap between visual parsing and symbolic reasoning. Models with stronger symbolic reasoning capabilities consistently achieve higher design task accuracy, confirming the fundamental role of mathematical understanding in circuit synthesis and establishing symbolic reasoning as the key metric for engineering competence.
Learn the Ropes, Then Trust the Wins: Self-imitation with Progressive Exploration for Agentic Reinforcement Learning
Sep 26, 2025
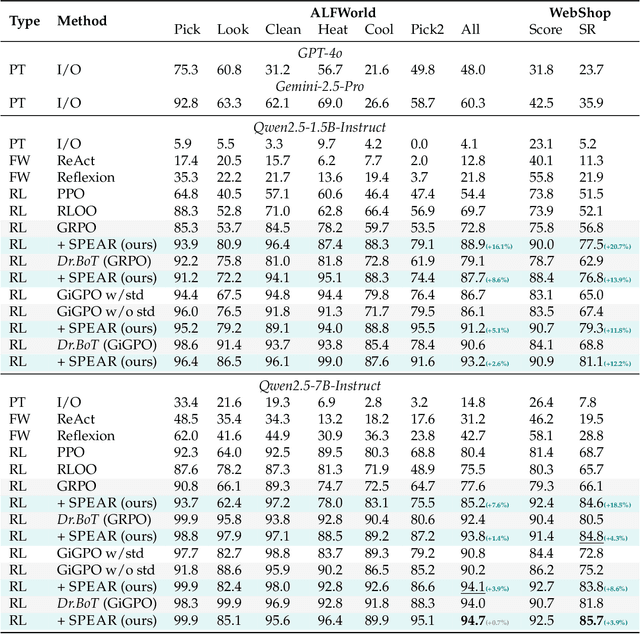
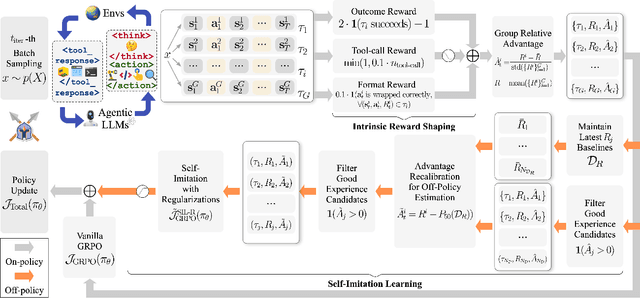
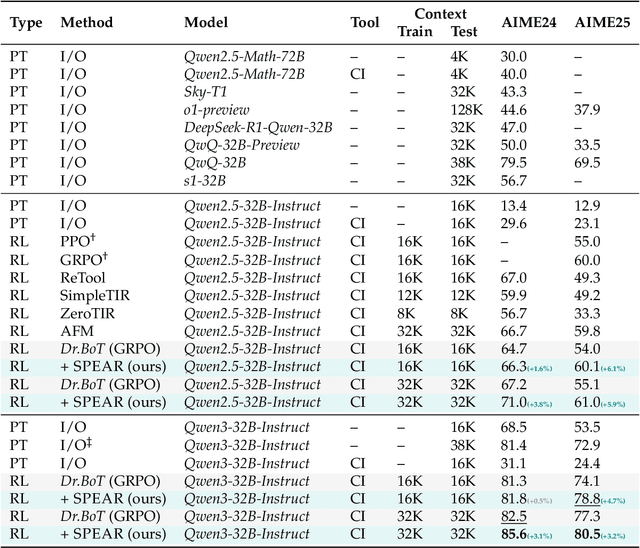
Reinforcement learning (RL) is the dominant paradigm for sharpening strategic tool use capabilities of LLMs on long-horizon, sparsely-rewarded agent tasks, yet it faces a fundamental challenge of exploration-exploitation trade-off. Existing studies stimulate exploration through the lens of policy entropy, but such mechanical entropy maximization is prone to RL training instability due to the multi-turn distribution shifting. In this paper, we target the progressive exploration-exploitation balance under the guidance of the agent own experiences without succumbing to either entropy collapsing or runaway divergence. We propose SPEAR, a curriculum-based self-imitation learning (SIL) recipe for training agentic LLMs. It extends the vanilla SIL framework, where a replay buffer stores self-generated promising trajectories for off-policy update, by gradually steering the policy evolution within a well-balanced range of entropy across stages. Specifically, our approach incorporates a curriculum to manage the exploration process, utilizing intrinsic rewards to foster skill-level exploration and facilitating action-level exploration through SIL. At first, the auxiliary tool call reward plays a critical role in the accumulation of tool-use skills, enabling broad exposure to the unfamiliar distributions of the environment feedback with an upward entropy trend. As training progresses, self-imitation gets strengthened to exploit existing successful patterns from replayed experiences for comparative action-level exploration, accelerating solution iteration without unbounded entropy growth. To further stabilize training, we recalibrate the advantages of experiences in the replay buffer to address the potential policy drift. Reugularizations such as the clipping of tokens with high covariance between probability and advantage are introduced to the trajectory-level entropy control to curb over-confidence.
Visual-CoG: Stage-Aware Reinforcement Learning with Chain of Guidance for Text-to-Image Generation
Aug 25, 2025



Despite the promising progress of recent autoregressive models in text-to-image (T2I) generation, their ability to handle multi-attribute and ambiguous prompts remains limited. To address these limitations, existing works have applied chain-of-thought (CoT) to enable stage-aware visual synthesis and employed reinforcement learning (RL) to improve reasoning capabilities. However, most models provide reward signals only at the end of the generation stage. This monolithic final-only guidance makes it difficult to identify which stages contribute positively to the final outcome and may lead to suboptimal policies. To tackle this issue, we propose a Visual-Chain of Guidance (Visual-CoG) paradigm consisting of three stages: semantic reasoning, process refining, and outcome evaluation, with stage-aware rewards providing immediate guidance throughout the image generation pipeline. We further construct a visual cognition benchmark, VisCog-Bench, which comprises four subtasks to evaluate the effectiveness of semantic reasoning. Comprehensive evaluations on GenEval, T2I-CompBench, and the proposed VisCog-Bench show improvements of 15%, 5%, and 19%, respectively, demonstrating the superior performance of the proposed Visual-CoG. We will release all the resources soon.