 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking E-Commerce Search
Dec 06, 2023



E-commerce search and recommendation usually operate on structured data such as product catalogs and taxonomies. However, creating better search and recommendation systems often requires a large variety of unstructured data including customer reviews and articles on the web. Traditionally, the solution has always been converting unstructured data into structured data through information extraction, and conducting search over the structured data. However, this is a costly approach that often has low quality. In this paper, we envision a solution that does entirely the opposite. Instead of converting unstructured data (web pages, customer reviews, etc) to structured data, we instead convert structured data (product inventory, catalogs, taxonomies, etc) into textual data, which can be easily integrated into the text corpus that trains LLMs. Then, search and recommendation can be performed through a Q/A mechanism through an LLM instead of using traditional information retrieval methods over structured data.
Mitigating Pooling Bias in E-commerce Search via False Negative Estimation
Nov 18, 2023



Efficient and accurate product relevance assessment is critical for user experiences and business success. Training a proficient relevance assessment model requires high-quality query-product pairs, often obtained through negative sampling strategies. Unfortunately, current methods introduce pooling bias by mistakenly sampling false negatives, diminishing performance and business impact. To address this, we present Bias-mitigating Hard Negative Sampling (BHNS), a novel negative sampling strategy tailored to identify and adjust for false negatives, building upon our original False Negative Estimation algorithm. Our experiments in the Instacart search setting confirm BHNS as effective for practical e-commerce use. Furthermore, comparative analyses on public dataset showcase its domain-agnostic potential for diverse applications.
An Embedding-Based Grocery Search Model at Instacart
Sep 12, 2022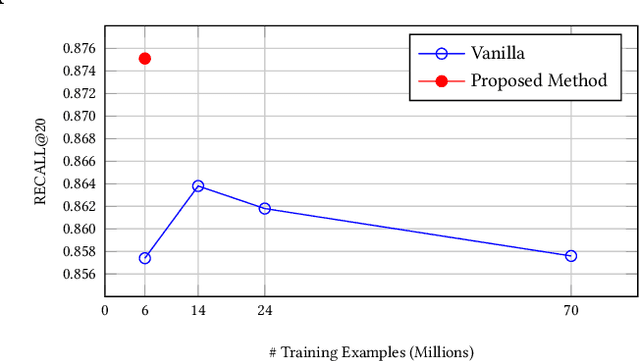

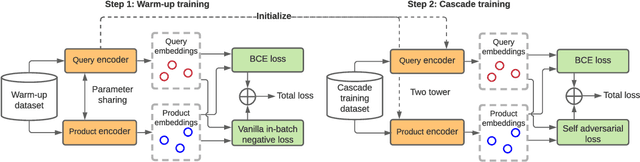
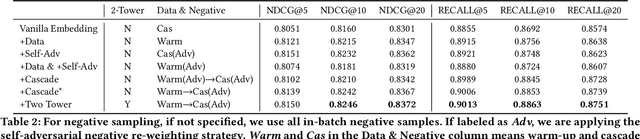
The key to e-commerce search is how to best utilize the large yet noisy log data. In this paper, we present our embedding-based model for grocery search at Instacart. The system learns query and product representations with a two-tower transformer-based encoder architecture. To tackle the cold-start problem, we focus on content-based features. To train the model efficiently on noisy data, we propose a self-adversarial learning method and a cascade training method. AccOn an offline human evaluation dataset, we achieve 10% relative improvement in RECALL@20, and for online A/B testing, we achieve 4.1% cart-adds per search (CAPS) and 1.5% gross merchandise value (GMV) improvement. We describe how we train and deploy the embedding based search model and give a detailed analysis of the effectiveness of our method.
Mixture of Pre-processing Experts Model for Noise Robust Deep Learning on Resource Constrained Platforms
Apr 29, 2019
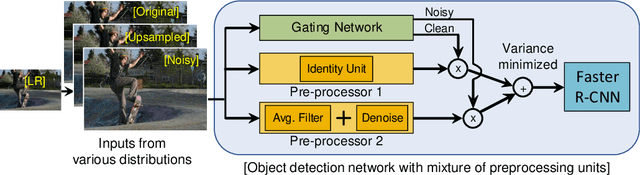


Deep learning on an edge device requires energy efficient operation due to ever diminishing power budget. Intentional low quality data during the data acquisition for longer battery life, and natural noise from the low cost sensor degrade the quality of target output which hinders adoption of deep learning on an edge device. To overcome these problems, we propose simple yet efficient mixture of pre-processing experts (MoPE) model to handle various image distortions including low resolution and noisy images. We also propose to use adversarially trained auto encoder as a pre-processing expert for the noisy images. We evaluate our proposed method for various machine learning tasks including object detection on MS-COCO 2014 dataset, multiple object tracking problem on MOT-Challenge dataset, and human activity classification on UCF 101 dataset. Experimental results show that the proposed method achieves better detection, tracking and activity classification accuracies under noise without sacrificing accuracies for the clean images. The overheads of our proposed MoPE are 0.67% and 0.17% in terms of memory and computation compared to the baseline object detection network.
Cascade Adversarial Machine Learning Regularized with a Unified Embedding
Mar 17, 2018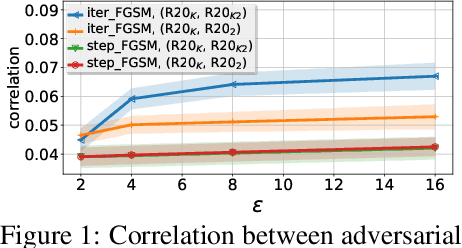


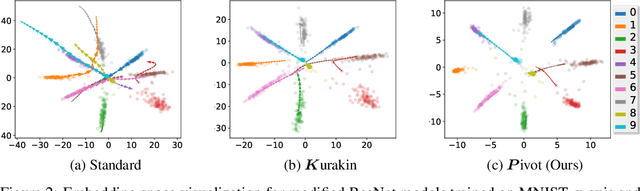
Injecting adversarial examples during training, known as adversarial training, can improve robustness against one-step attacks, but not for unknown iterative attacks. To address this challenge, we first show iteratively generated adversarial images easily transfer between networks trained with the same strategy. Inspired by this observation, we propose cascade adversarial training, which transfers the knowledge of the end results of adversarial training. We train a network from scratch by injecting iteratively generated adversarial images crafted from already defended networks in addition to one-step adversarial images from the network being trained. We also propose to utilize embedding space for both classification and low-level (pixel-level) similarity learning to ignore unknown pixel level perturbation. During training, we inject adversarial images without replacing their corresponding clean images and penalize the distance between the two embeddings (clean and adversarial). Experimental results show that cascade adversarial training together with our proposed low-level similarity learning efficiently enhances the robustness against iterative attacks, but at the expense of decreased robustness against one-step attacks. We show that combining those two techniques can also improve robustness under the worst case black box attack scenario.
Edge-Host Partitioning of Deep Neural Networks with Feature Space Encoding for Resource-Constrained Internet-of-Things Platforms
Feb 11, 2018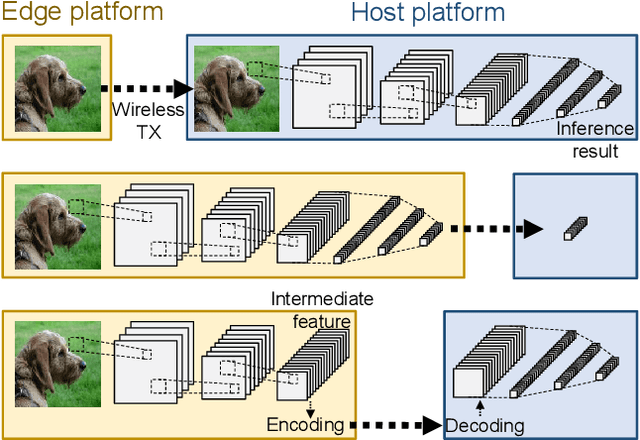
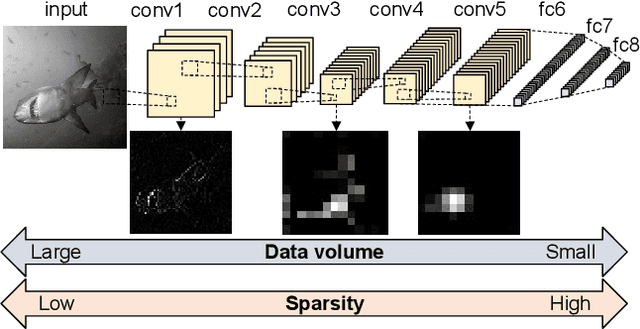
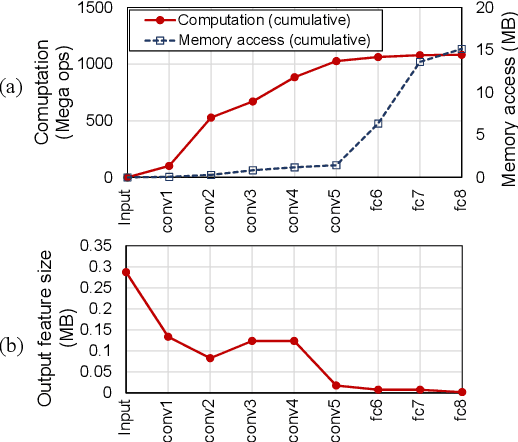
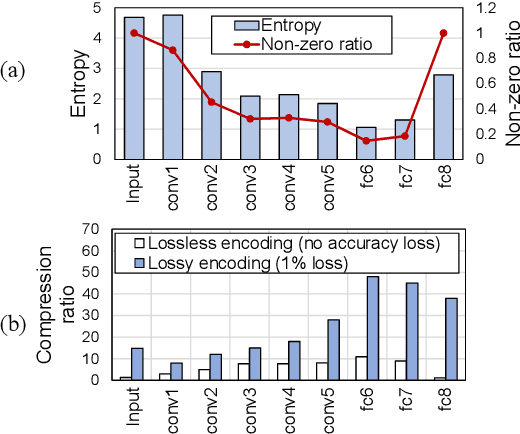
This paper introduces partitioning an inference task of a deep neural network between an edge and a host platform in the IoT environment. We present a DNN as an encoding pipeline, and propose to transmit the output feature space of an intermediate layer to the host. The lossless or lossy encoding of the feature space is proposed to enhance the maximum input rate supported by the edge platform and/or reduce the energy of the edge platform. Simulation results show that partitioning a DNN at the end of convolutional (feature extraction) layers coupled with feature space encoding enables significant improvement in the energy-efficiency and throughput over the baseline configurations that perform the entire inference at the edge or at the host.