 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Improving Layer Normalization
Nov 16, 2019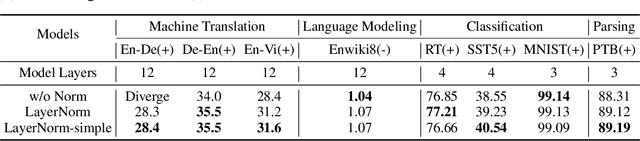
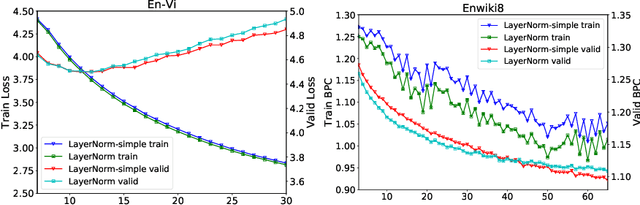
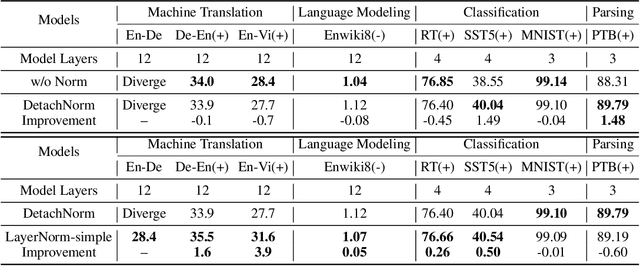
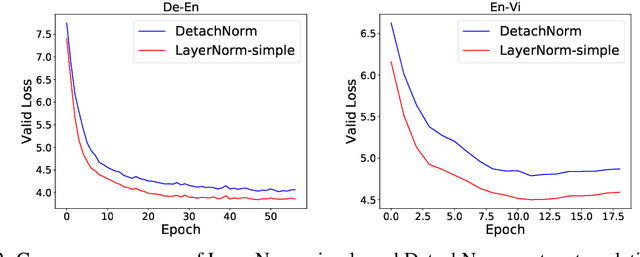
Layer normalization (LayerNorm) is a technique to normalize the distributions of intermediate layers. It enables smoother gradients, faster training, and better generalization accuracy. However, it is still unclear where the effectiveness stems from. In this paper, our main contribution is to take a step further in understanding LayerNorm. Many of previous studies believe that the success of LayerNorm comes from forward normalization. Unlike them, we find that the derivatives of the mean and variance are more important than forward normalization by re-centering and re-scaling backward gradients. Furthermore, we find that the parameters of LayerNorm, including the bias and gain, increase the risk of over-fitting and do not work in most cases. Experiments show that a simple version of LayerNorm (LayerNorm-simple) without the bias and gain outperforms LayerNorm on four datasets. It obtains the state-of-the-art performance on En-Vi machine translation. To address the over-fitting problem, we propose a new normalization method, Adaptive Normalization (AdaNorm), by replacing the bias and gain with a new transformation function. Experiments show that AdaNorm demonstrates better results than LayerNorm on seven out of eight datasets.
Improving Node Classification by Co-training Node Pair Classification: A Novel Training Framework for General Graph Neural Networks
Nov 10, 2019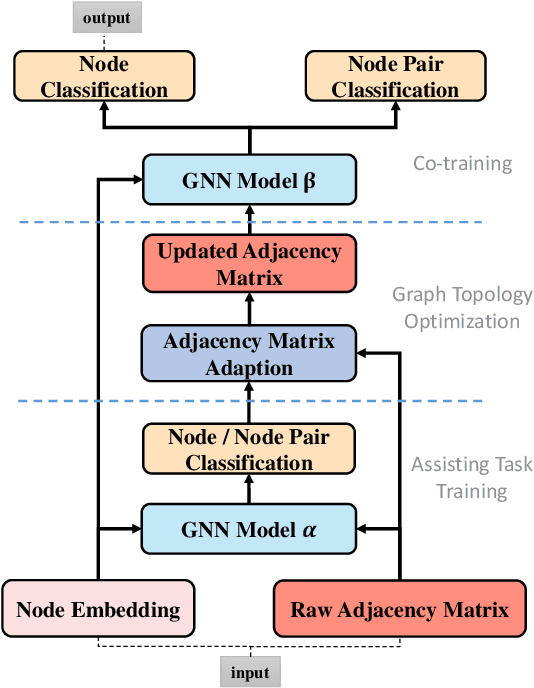

Semi-supervised learning is a widely used training framework for graph node classification. However, there are two problems existing in this learning method: (1) the original graph topology may not be perfectly aligned with the node classification task; (2) the supervision information in the training set has not been fully used. To tackle these two problems, we design a new task: node pair classification, to assist in training GNN models for the target node classification task. We further propose a novel training framework named Adaptive Co-training, which jointly trains the node classification and the node pair classification after the optimization of graph topology. Extensive experimental results on four representative GNN models have demonstrated that our proposed training framework significantly outperforms baseline methods across three benchmark graph datasets.
An Adaptive and Momental Bound Method for Stochastic Learning
Oct 27, 2019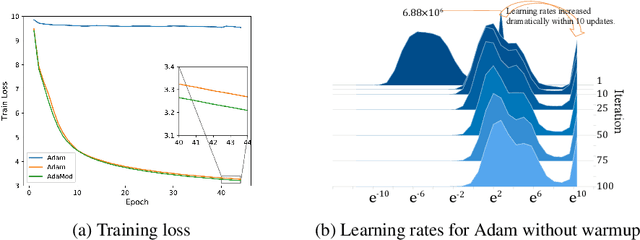
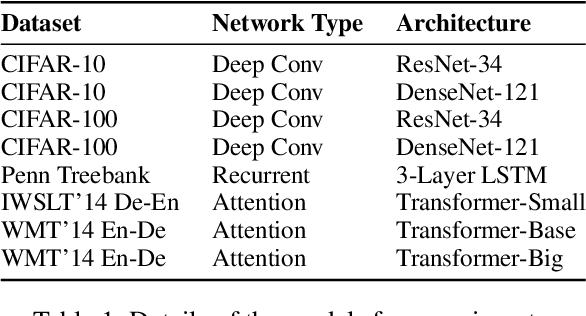
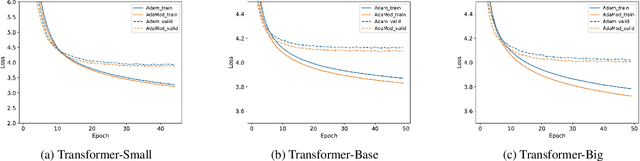

Training deep neural networks requires intricate initialization and careful selection of learning rates. The emergence of stochastic gradient optimization methods that use adaptive learning rates based on squared past gradients, e.g., AdaGrad, AdaDelta, and Adam, eases the job slightly. However, such methods have also been proven problematic in recent studies with their own pitfalls including non-convergence issues and so on. Alternative variants have been proposed for enhancement, such as AMSGrad, AdaShift and AdaBound. In this work, we identify a new problem of adaptive learning rate methods that exhibits at the beginning of learning where Adam produces extremely large learning rates that inhibit the start of learning. We propose the Adaptive and Momental Bound (AdaMod) method to restrict the adaptive learning rates with adaptive and momental upper bounds. The dynamic learning rate bounds are based on the exponential moving averages of the adaptive learning rates themselves, which smooth out unexpected large learning rates and stabilize the training of deep neural networks. Our experiments verify that AdaMod eliminates the extremely large learning rates throughout the training and brings significant improvements especially on complex networks such as DenseNet and Transformer, compared to Adam. Our implementation is available at: https://github.com/lancopku/AdaMod
Pun-GAN: Generative Adversarial Network for Pun Generation
Oct 24, 2019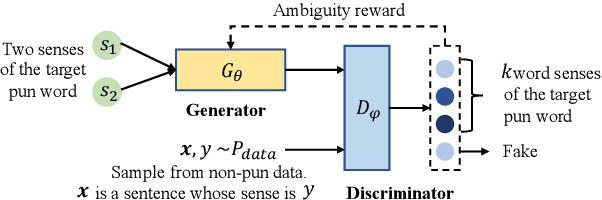
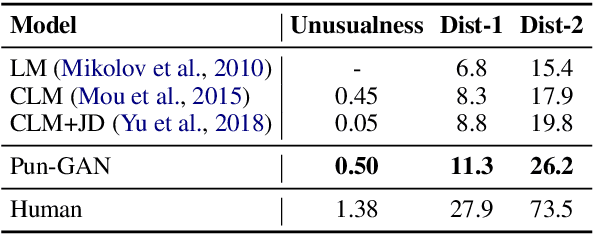
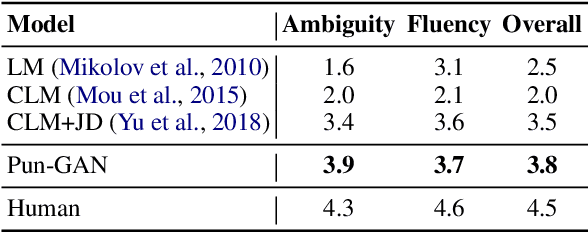
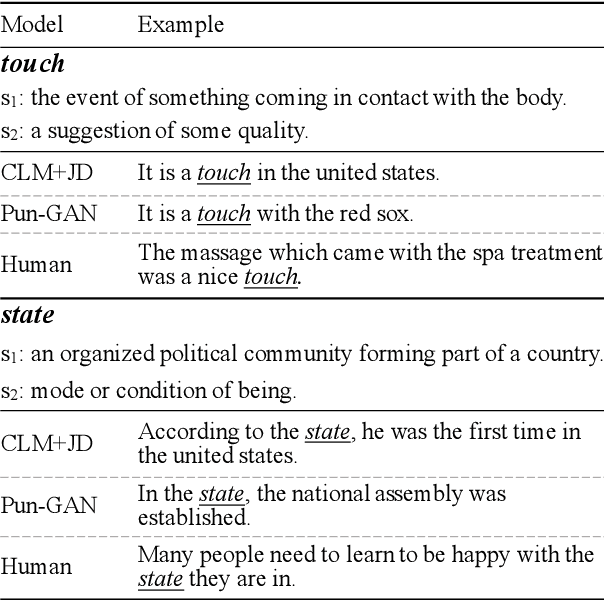
In this paper, we focus on the task of generating a pun sentence given a pair of word senses. A major challenge for pun generation is the lack of large-scale pun corpus to guide the supervised learning. To remedy this, we propose an adversarial generative network for pun generation (Pun-GAN), which does not require any pun corpus. It consists of a generator to produce pun sentences, and a discriminator to distinguish between the generated pun sentences and the real sentences with specific word senses. The output of the discriminator is then used as a reward to train the generator via reinforcement learning, encouraging it to produce pun sentences that can support two word senses simultaneously. Experiments show that the proposed Pun-GAN can generate sentences that are more ambiguous and diverse in both automatic and human evaluation.
Aligning Cross-Lingual Entities with Multi-Aspect Information
Oct 15, 2019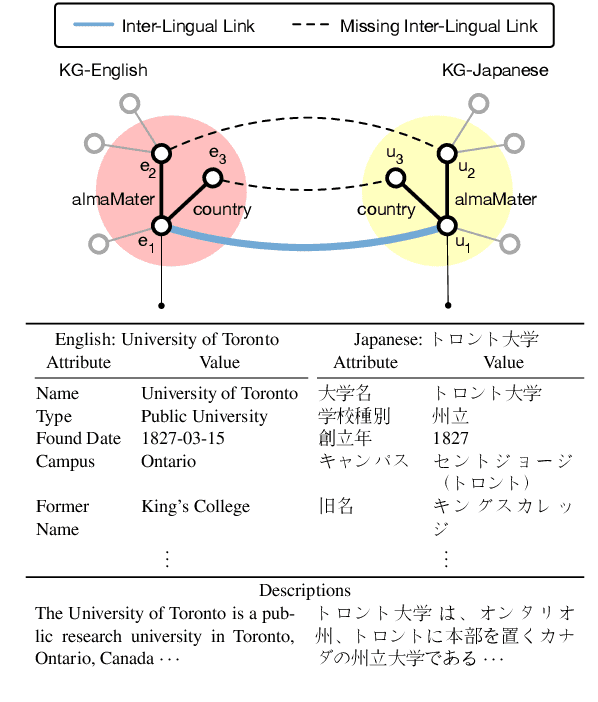
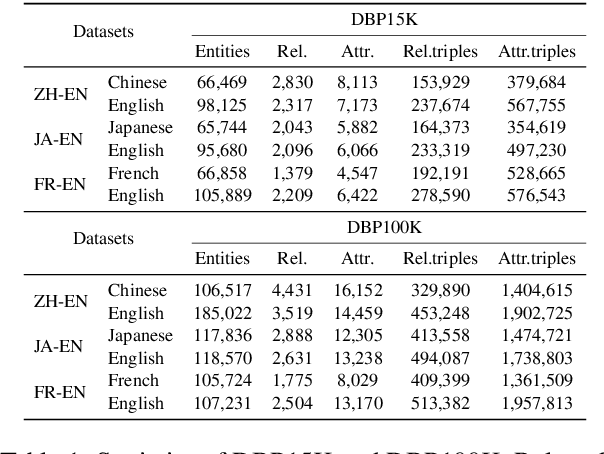
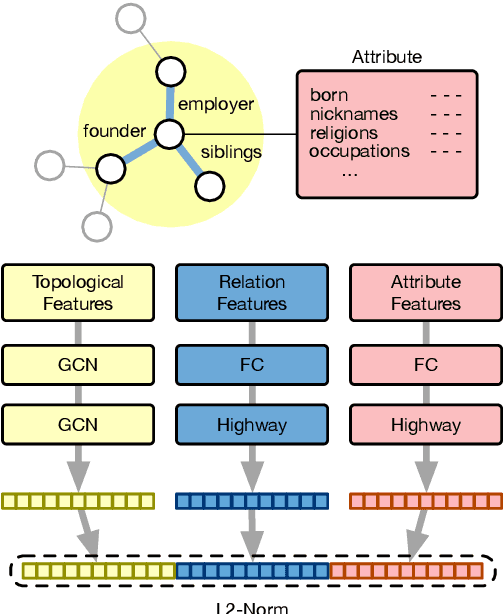
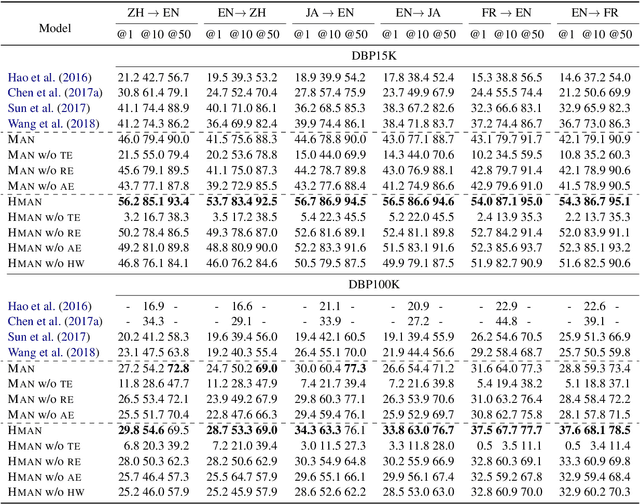
Multilingual knowledge graphs (KGs), such as YAGO and DBpedia, represent entities in different languages. The task of cross-lingual entity alignment is to match entities in a source language with their counterparts in target languages. In this work, we investigate embedding-based approaches to encode entities from multilingual KGs into the same vector space, where equivalent entities are close to each other. Specifically, we apply graph convolutional networks (GCNs) to combine multi-aspect information of entities, including topological connections, relations, and attributes of entities, to learn entity embeddings. To exploit the literal descriptions of entities expressed in different languages, we propose two uses of a pretrained multilingual BERT model to bridge cross-lingual gaps. We further propose two strategies to integrate GCN-based and BERT-based modules to boost performance. Extensive experiments on two benchmark datasets demonstrate that our method significantly outperforms existing systems.
Group, Extract and Aggregate: Summarizing a Large Amount of Finance News for Forex Movement Prediction
Oct 11, 2019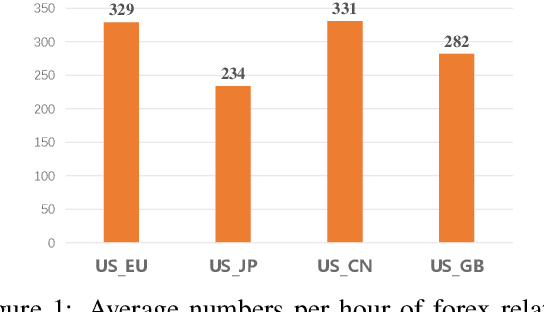
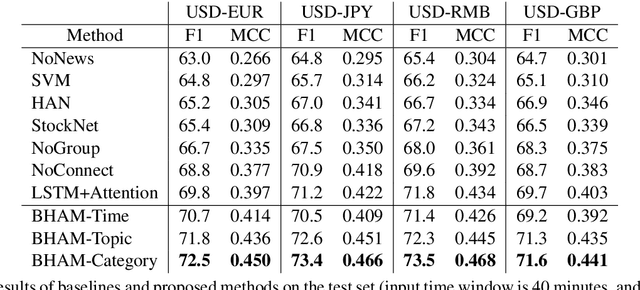
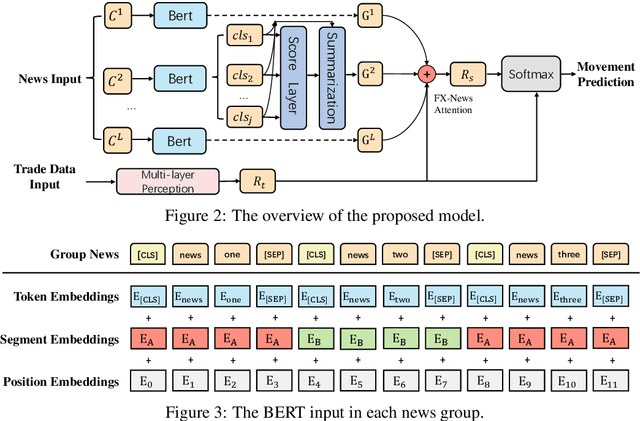
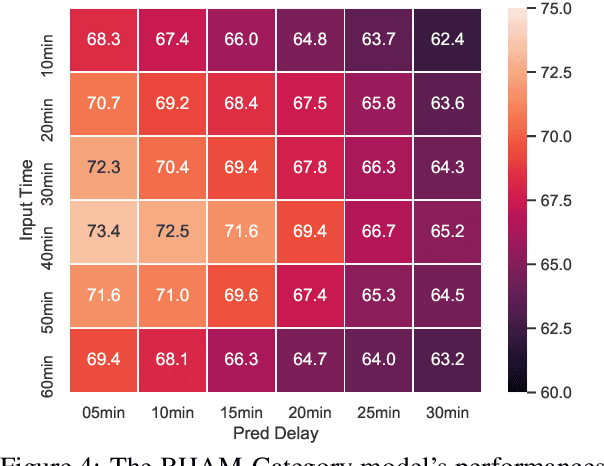
Incorporating related text information has proven successful in stock market prediction. However, it is a huge challenge to utilize texts in the enormous forex (foreign currency exchange) market because the associated texts are too redundant. In this work, we propose a BERT-based Hierarchical Aggregation Model to summarize a large amount of finance news to predict forex movement. We firstly group news from different aspects: time, topic and category. Then we extract the most crucial news in each group by the SOTA extractive summarization method. Finally, we conduct interaction between the news and the trade data with attention to predict the forex movement. The experimental results show that the category based method performs best among three grouping methods and outperforms all the baselines. Besides, we study the influence of essential news attributes (category and region) by statistical analysis and summarize the influence patterns for different currency pairs.
Sequence-to-sequence Pre-training with Data Augmentation for Sentence Rewriting
Sep 20, 2019
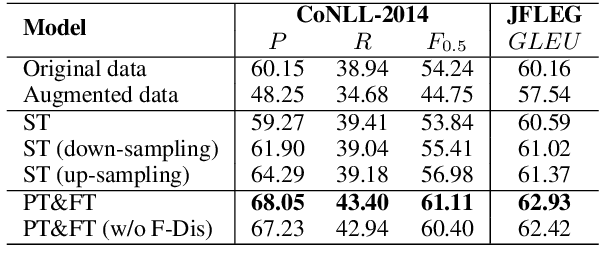
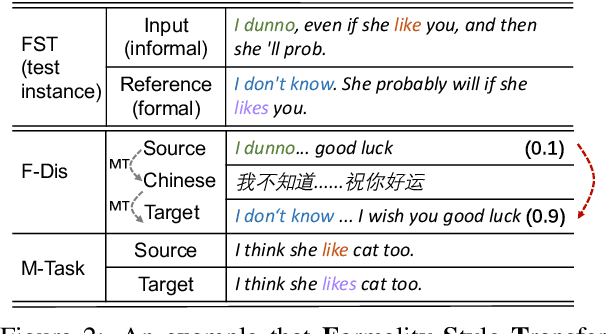
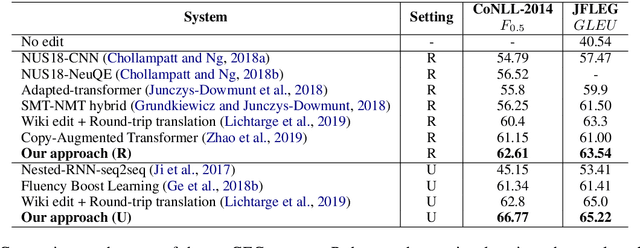
We study sequence-to-sequence (seq2seq) pre-training with data augmentation for sentence rewriting. Instead of training a seq2seq model with gold training data and augmented data simultaneously, we separate them to train in different phases: pre-training with the augmented data and fine-tuning with the gold data. We also introduce multiple data augmentation methods to help model pre-training for sentence rewriting. We evaluate our approach in two typical well-defined sentence rewriting tasks: Grammatical Error Correction (GEC) and Formality Style Transfer (FST). Experiments demonstrate our approach can better utilize augmented data without hurting the model's trust in gold data and further improve the model's performance with our proposed data augmentation methods. Our approach substantially advances the state-of-the-art results in well-recognized sentence rewriting benchmarks over both GEC and FST. Specifically, it pushes the CoNLL-2014 benchmark's $F_{0.5}$ score and JFLEG Test GLEU score to 62.61 and 63.54 in the restricted training setting, 66.77 and 65.22 respectively in the unrestricted setting, and advances GYAFC benchmark's BLEU to 74.24 (2.23 absolute improvement) in E&M domain and 77.97 (2.64 absolute improvement) in F&R domain.
Recursive Graphical Neural Networks for Text Classification
Sep 18, 2019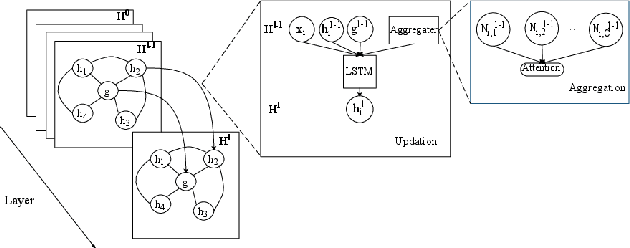
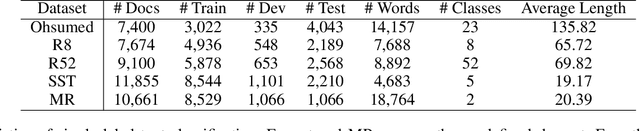

The complicated syntax structure of natural language is hard to be explicitly modeled by sequence-based models. Graph is a natural structure to describe the complicated relation between tokens. The recent advance in Graph Neural Networks (GNN) provides a powerful tool to model graph structure data, but simple graph models such as Graph Convolutional Networks (GCN) suffer from over-smoothing problem, that is, when stacking multiple layers, all nodes will converge to the same value. In this paper, we propose a novel Recursive Graphical Neural Networks model (ReGNN) to represent text organized in the form of graph. In our proposed model, LSTM is used to dynamically decide which part of the aggregated neighbor information should be transmitted to upper layers thus alleviating the over-smoothing problem. Furthermore, to encourage the exchange between the local and global information, a global graph-level node is designed. We conduct experiments on both single and multiple label text classification tasks. Experiment results show that our ReGNN model surpasses the strong baselines significantly in most of the datasets and greatly alleviates the over-smoothing problem.
Measuring and Relieving the Over-smoothing Problem for Graph Neural Networks from the Topological View
Sep 07, 2019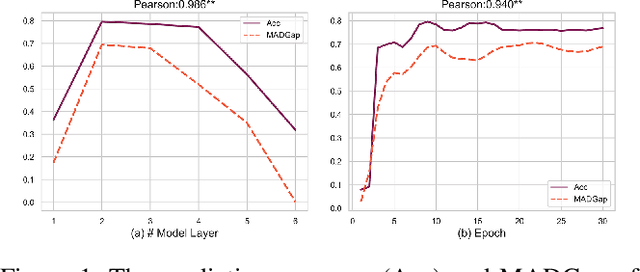
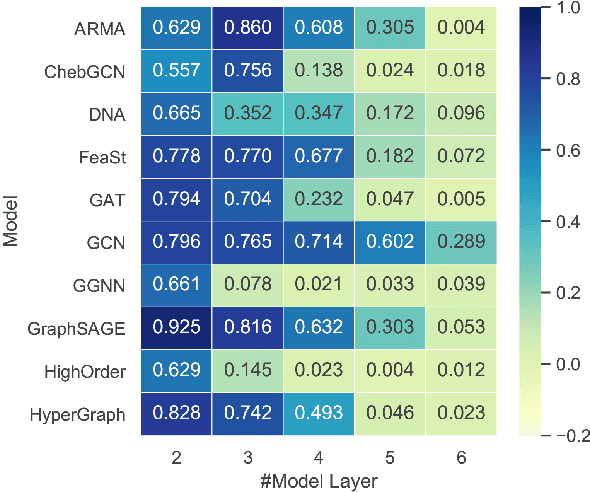
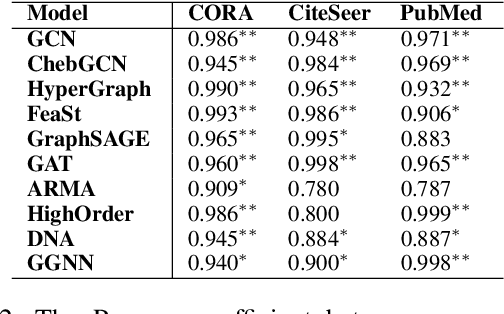
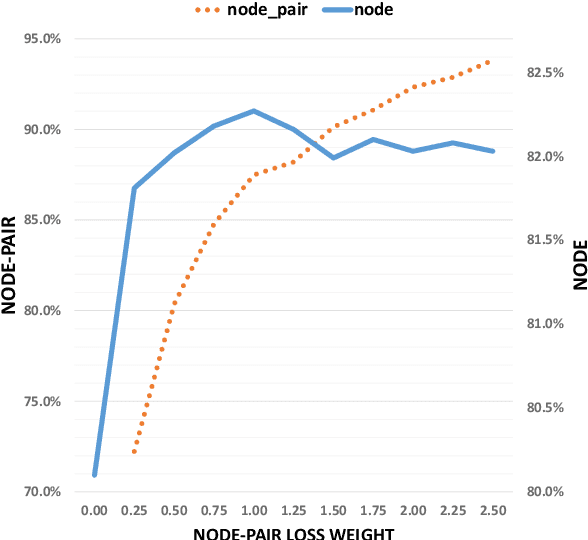
Graph Neural Networks (GNNs) have achieved promising performance on a wide range of graph-based tasks. Despite their success, one severe limitation of GNNs is the over-smoothing issue (indistinguishable representations of nodes in different classes). In this work, we present a systematic and quantitative study on the over-smoothing issue of GNNs. First, we introduce two quantitative metrics, MAD and MADGap, to measure the smoothness and over-smoothness of the graph nodes representations, respectively. Then, we verify that smoothing is the nature of GNNs and the critical factor leading to over-smoothness is the low information-to-noise ratio of the message received by the nodes, which is partially determined by the graph topology. Finally, we propose two methods to alleviate the over-smoothing issue from the topological view: (1) MADReg which adds a MADGap-based regularizer to the training objective;(2) AdaGraph which optimizes the graph topology based on the model predictions. Extensive experiments on 7 widely-used graph datasets with 10 typical GNN models show that the two proposed methods are effective for relieving the over-smoothing issue, thus improving the performance of various GNN models.
Key Fact as Pivot: A Two-Stage Model for Low Resource Table-to-Text Generation
Aug 08, 2019
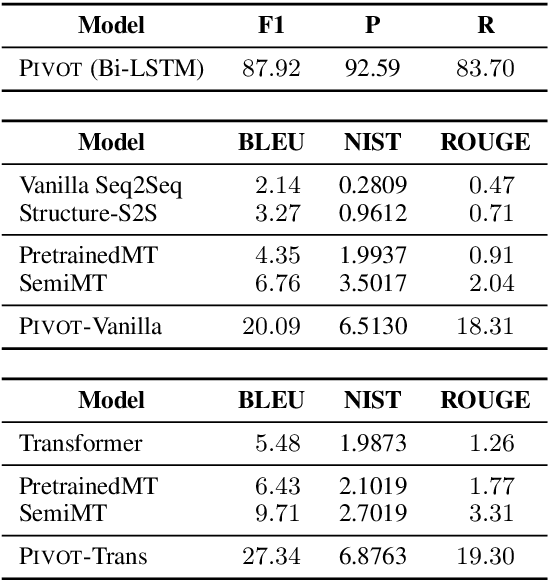
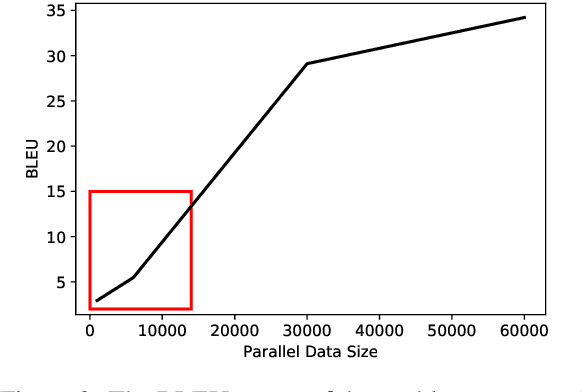
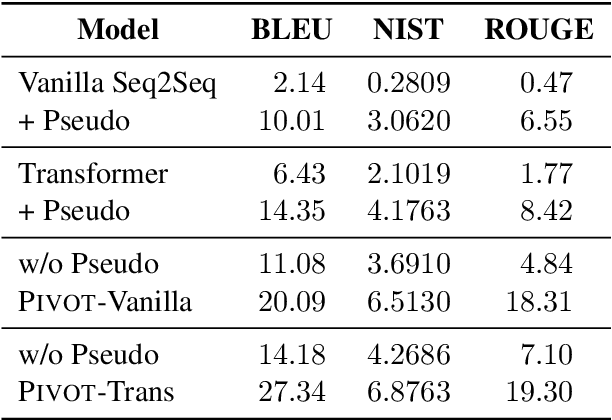
Table-to-text generation aims to translate the structured data into the unstructured text. Most existing methods adopt the encoder-decoder framework to learn the transformation, which requires large-scale training samples. However, the lack of large parallel data is a major practical problem for many domains. In this work, we consider the scenario of low resource table-to-text generation, where only limited parallel data is available. We propose a novel model to separate the generation into two stages: key fact prediction and surface realization. It first predicts the key facts from the tables, and then generates the text with the key facts. The training of key fact prediction needs much fewer annotated data, while surface realization can be trained with pseudo parallel corpus. We evaluate our model on a biography generation dataset. Our model can achieve $27.34$ BLEU score with only $1,000$ parallel data, while the baseline model only obtain the performance of $9.71$ BLEU score.