 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Few-Shot Performance of Language Models via Nearest Neighbor Calibration
Dec 05, 2022



Pre-trained language models (PLMs) have exhibited remarkable few-shot learning capabilities when provided a few examples in a natural language prompt as demonstrations of test instances, i.e., in-context learning. However, the performance of in-context learning is susceptible to the choice of prompt format, training examples and the ordering of the training examples. In this paper, we propose a novel nearest-neighbor calibration framework for in-context learning to ease this issue. It is inspired by a phenomenon that the in-context learning paradigm produces incorrect labels when inferring training instances, which provides a useful supervised signal to calibrate predictions. Thus, our method directly augments the predictions with a $k$-nearest-neighbor ($k$NN) classifier over a datastore of cached few-shot instance representations obtained by PLMs and their corresponding labels. Then adaptive neighbor selection and feature regularization modules are introduced to make full use of a few support instances to reduce the $k$NN retrieval noise. Experiments on various few-shot text classification tasks demonstrate that our method significantly improves in-context learning, while even achieving comparable performance with state-of-the-art tuning-based approaches in some sentiment analysis tasks.
A Review of Federated Learning in Energy Systems
Aug 20, 2022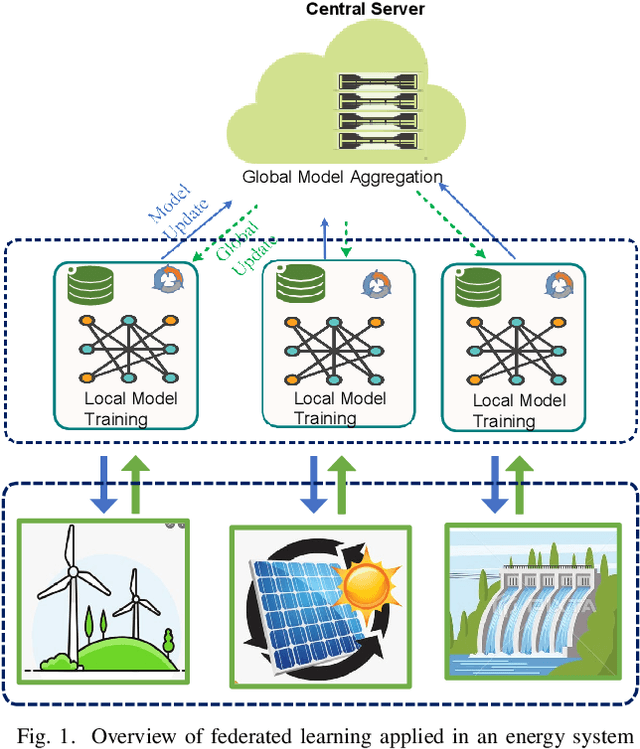
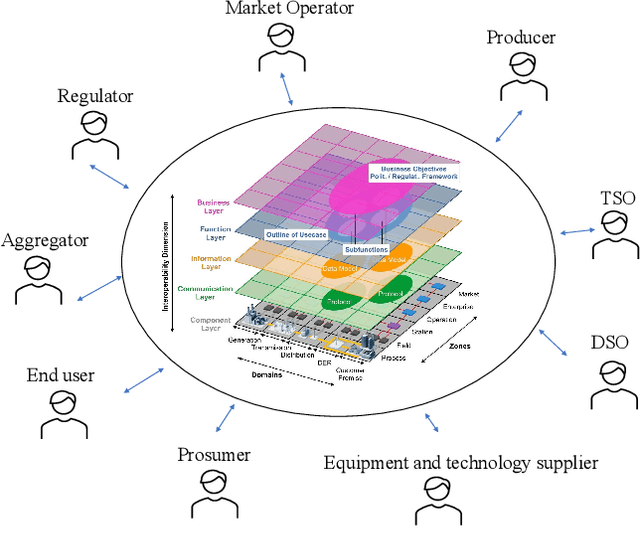
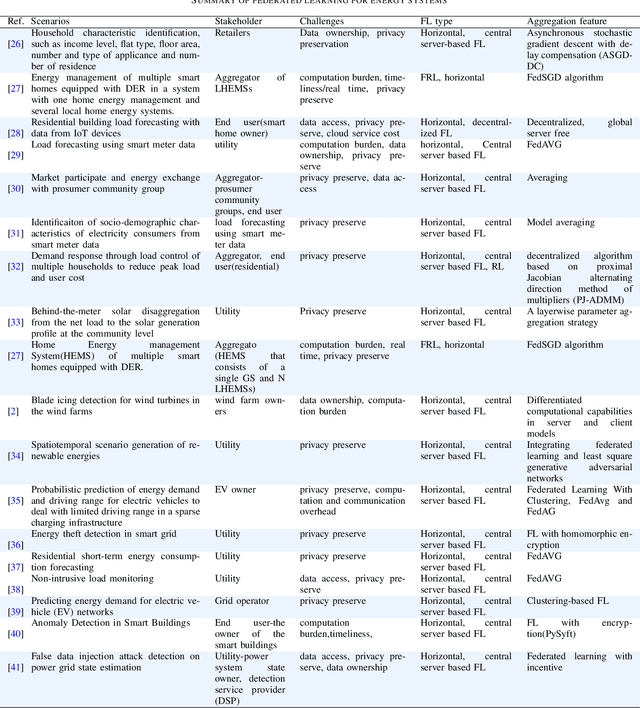
With increasing concerns for data privacy and ownership, recent years have witnessed a paradigm shift in machine learning (ML). An emerging paradigm, federated learning (FL), has gained great attention and has become a novel design for machine learning implementations. FL enables the ML model training at data silos under the coordination of a central server, eliminating communication overhead and without sharing raw data. In this paper, we conduct a review of the FL paradigm and, in particular, compare the types, the network structures, and the global model aggregation methods. Then, we conducted a comprehensive review of FL applications in the energy domain (refer to the smart grid in this paper). We provide a thematic classification of FL to address a variety of energy-related problems, including demand response, identification, prediction, and federated optimizations. We describe the taxonomy in detail and conclude with a discussion of various aspects, including challenges, opportunities, and limitations in its energy informatics applications, such as energy system modeling and design, privacy, and evolution.
Quantifying the Knowledge in a DNN to Explain Knowledge Distillation for Classification
Aug 18, 2022
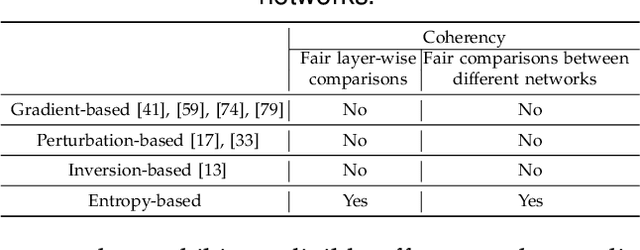
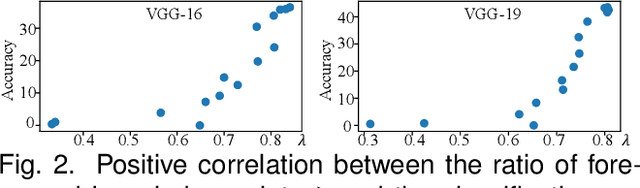
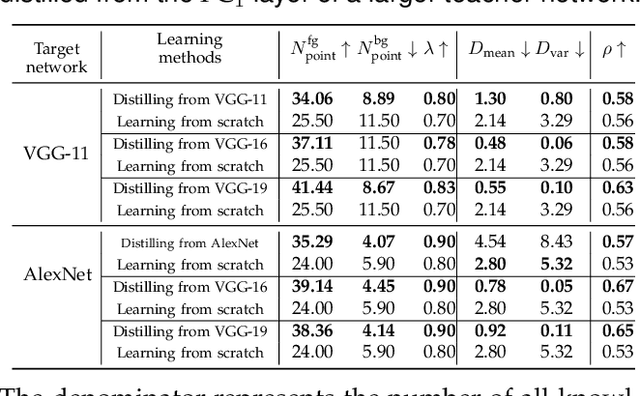
Compared to traditional learning from scratch, knowledge distillation sometimes makes the DNN achieve superior performance. This paper provides a new perspective to explain the success of knowledge distillation, i.e., quantifying knowledge points encoded in intermediate layers of a DNN for classification, based on the information theory. To this end, we consider the signal processing in a DNN as the layer-wise information discarding. A knowledge point is referred to as an input unit, whose information is much less discarded than other input units. Thus, we propose three hypotheses for knowledge distillation based on the quantification of knowledge points. 1. The DNN learning from knowledge distillation encodes more knowledge points than the DNN learning from scratch. 2. Knowledge distillation makes the DNN more likely to learn different knowledge points simultaneously. In comparison, the DNN learning from scratch tends to encode various knowledge points sequentially. 3. The DNN learning from knowledge distillation is often optimized more stably than the DNN learning from scratch. In order to verify the above hypotheses, we design three types of metrics with annotations of foreground objects to analyze feature representations of the DNN, \textit{i.e.} the quantity and the quality of knowledge points, the learning speed of different knowledge points, and the stability of optimization directions. In experiments, we diagnosed various DNNs for different classification tasks, i.e., image classification, 3D point cloud classification, binary sentiment classification, and question answering, which verified above hypotheses.
Proving Common Mechanisms Shared by Twelve Methods of Boosting Adversarial Transferability
Jul 24, 2022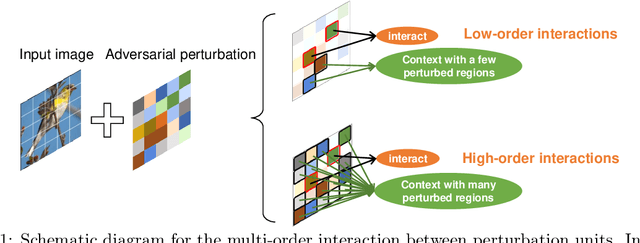
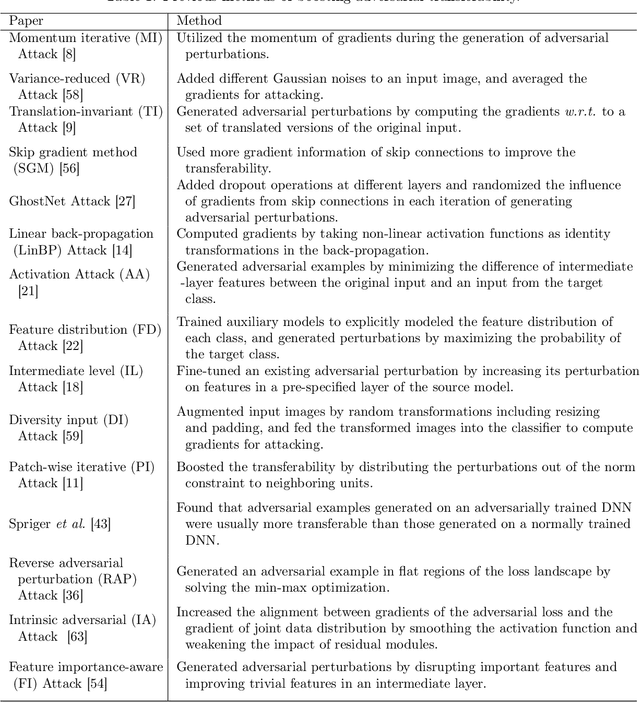
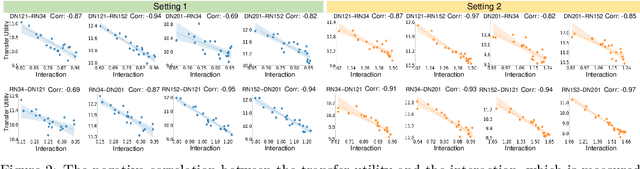
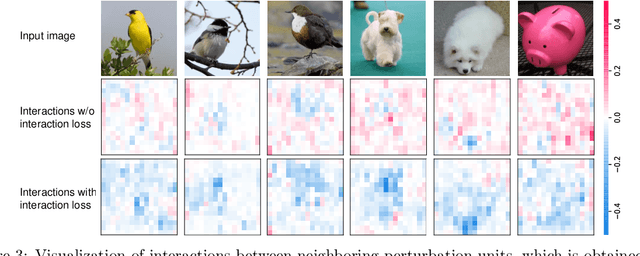
Although many methods have been proposed to enhance the transferability of adversarial perturbations, these methods are designed in a heuristic manner, and the essential mechanism for improving adversarial transferability is still unclear. This paper summarizes the common mechanism shared by twelve previous transferability-boosting methods in a unified view, i.e., these methods all reduce game-theoretic interactions between regional adversarial perturbations. To this end, we focus on the attacking utility of all interactions between regional adversarial perturbations, and we first discover and prove the negative correlation between the adversarial transferability and the attacking utility of interactions. Based on this discovery, we theoretically prove and empirically verify that twelve previous transferability-boosting methods all reduce interactions between regional adversarial perturbations. More crucially, we consider the reduction of interactions as the essential reason for the enhancement of adversarial transferability. Furthermore, we design the interaction loss to directly penalize interactions between regional adversarial perturbations during attacking. Experimental results show that the interaction loss significantly improves the transferability of adversarial perturbations.
Masked Autoencoders for Generic Event Boundary Detection CVPR'2022 Kinetics-GEBD Challenge
Jun 17, 2022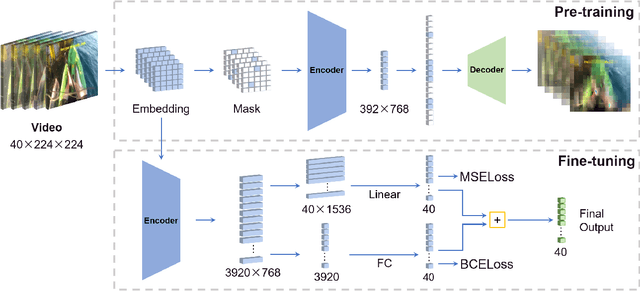
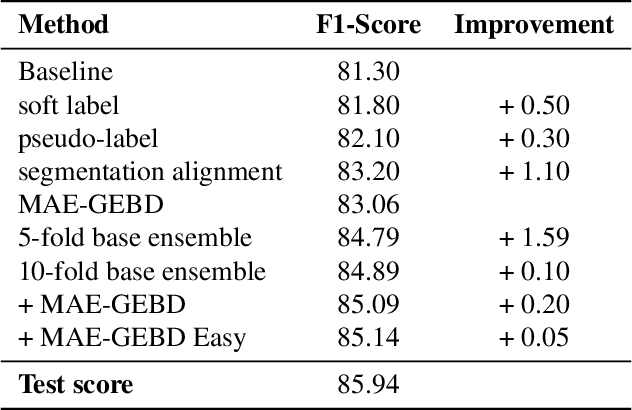
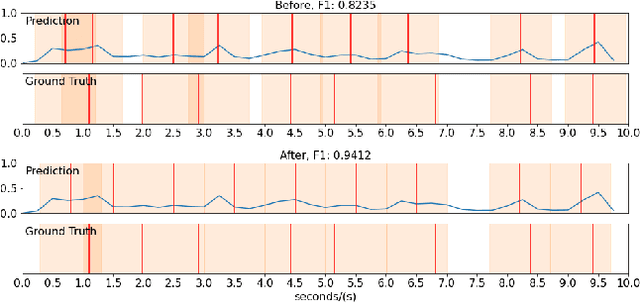
Generic Event Boundary Detection (GEBD) tasks aim at detecting generic, taxonomy-free event boundaries that segment a whole video into chunks. In this paper, we apply Masked Autoencoders to improve algorithm performance on the GEBD tasks. Our approach mainly adopted the ensemble of Masked Autoencoders fine-tuned on the GEBD task as a self-supervised learner with other base models. Moreover, we also use a semi-supervised pseudo-label method to take full advantage of the abundant unlabeled Kinetics-400 data while training. In addition, we propose a soft-label method to partially balance the positive and negative samples and alleviate the problem of ambiguous labeling in this task. Lastly, a tricky segmentation alignment policy is implemented to refine boundaries predicted by our models to more accurate locations. With our approach, we achieved 85.94% on the F1-score on the Kinetics-GEBD test set, which improved the F1-score by 2.31% compared to the winner of the 2021 Kinetics-GEBD Challenge. Our code is available at https://github.com/ContentAndMaterialPortrait/MAE-GEBD.
Why Adversarial Training of ReLU Networks Is Difficult?
May 30, 2022
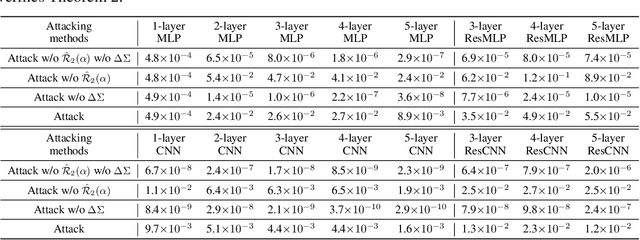
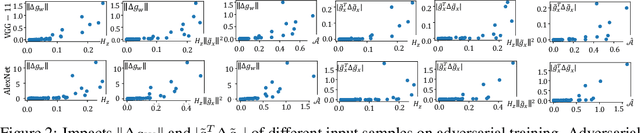

This paper mathematically derives an analytic solution of the adversarial perturbation on a ReLU network, and theoretically explains the difficulty of adversarial training. Specifically, we formulate the dynamics of the adversarial perturbation generated by the multi-step attack, which shows that the adversarial perturbation tends to strengthen eigenvectors corresponding to a few top-ranked eigenvalues of the Hessian matrix of the loss w.r.t. the input. We also prove that adversarial training tends to strengthen the influence of unconfident input samples with large gradient norms in an exponential manner. Besides, we find that adversarial training strengthens the influence of the Hessian matrix of the loss w.r.t. network parameters, which makes the adversarial training more likely to oscillate along directions of a few samples, and boosts the difficulty of adversarial training. Crucially, our proofs provide a unified explanation for previous findings in understanding adversarial training.
GRAND+: Scalable Graph Random Neural Networks
Mar 12, 2022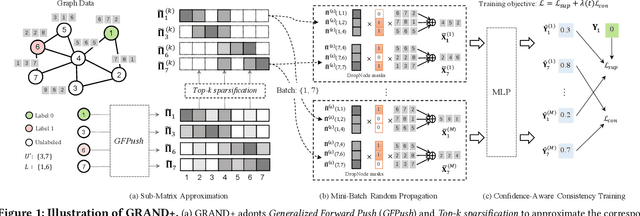
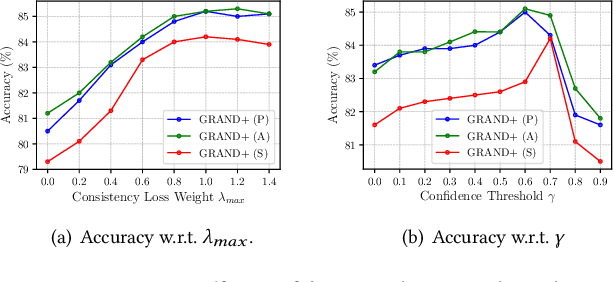
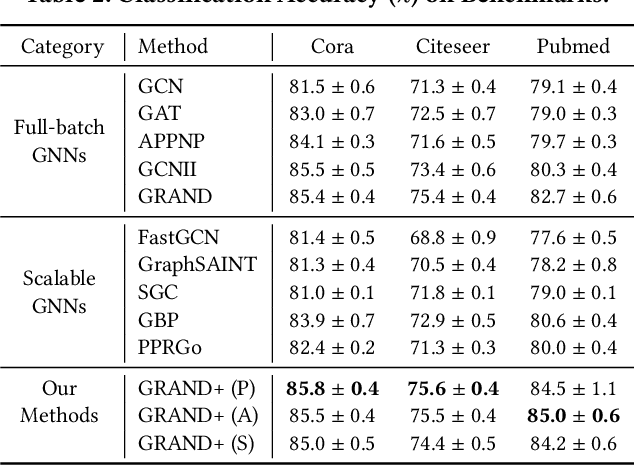
Graph neural networks (GNNs) have been widely adopted for semi-supervised learning on graphs. A recent study shows that the graph random neural network (GRAND) model can generate state-of-the-art performance for this problem. However, it is difficult for GRAND to handle large-scale graphs since its effectiveness relies on computationally expensive data augmentation procedures. In this work, we present a scalable and high-performance GNN framework GRAND+ for semi-supervised graph learning. To address the above issue, we develop a generalized forward push (GFPush) algorithm in GRAND+ to pre-compute a general propagation matrix and employ it to perform graph data augmentation in a mini-batch manner. We show that both the low time and space complexities of GFPush enable GRAND+ to efficiently scale to large graphs. Furthermore, we introduce a confidence-aware consistency loss into the model optimization of GRAND+, facilitating GRAND+'s generalization superiority. We conduct extensive experiments on seven public datasets of different sizes. The results demonstrate that GRAND+ 1) is able to scale to large graphs and costs less running time than existing scalable GNNs, and 2) can offer consistent accuracy improvements over both full-batch and scalable GNNs across all datasets.
Flexible-Modal Face Anti-Spoofing: A Benchmark
Feb 16, 2022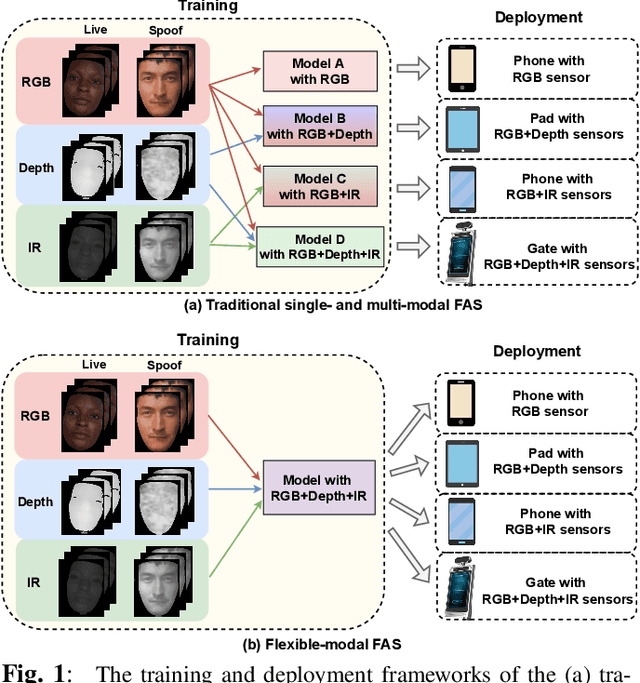
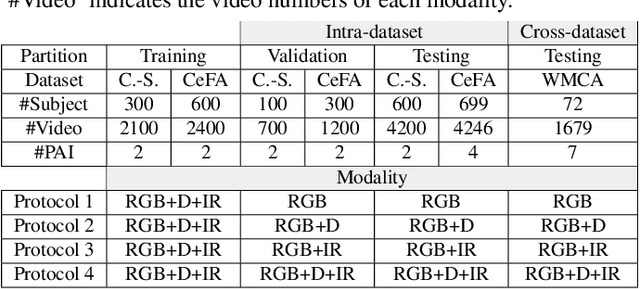
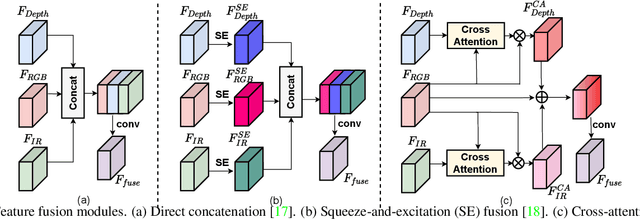
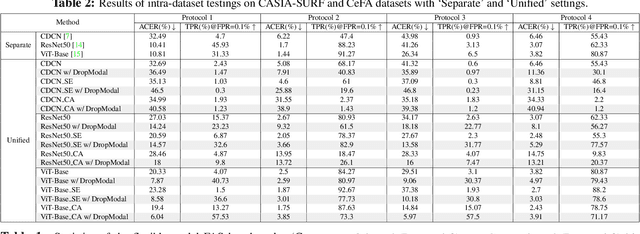
Face anti-spoofing (FAS) plays a vital role in securing face recognition systems from presentation attacks. Benefitted from the maturing camera sensors, single-modal (RGB) and multi-modal (e.g., RGB+Depth) FAS has been applied in various scenarios with different configurations of sensors/modalities. Existing single- and multi-modal FAS methods usually separately train and deploy models for each possible modality scenario, which might be redundant and inefficient. Can we train a unified model, and flexibly deploy it under various modality scenarios? In this paper, we establish the first flexible-modal FAS benchmark with the principle `train one for all'. To be specific, with trained multi-modal (RGB+Depth+IR) FAS models, both intra- and cross-dataset testings are conducted on four flexible-modal sub-protocols (RGB, RGB+Depth, RGB+IR, and RGB+Depth+IR). We also investigate prevalent deep models and feature fusion strategies for flexible-modal FAS. We hope this new benchmark will facilitate the future research of the multi-modal FAS. The protocols and codes are available at https://github.com/ZitongYu/Flex-Modal-FAS.
Reasoning Through Memorization: Nearest Neighbor Knowledge Graph Embeddings
Jan 14, 2022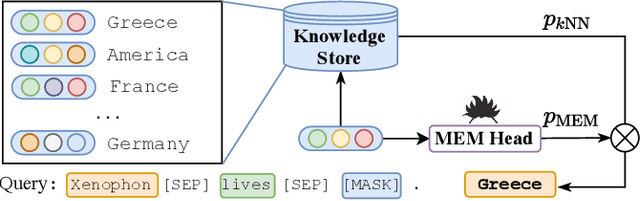
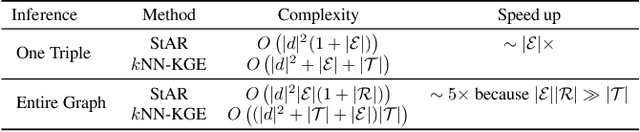
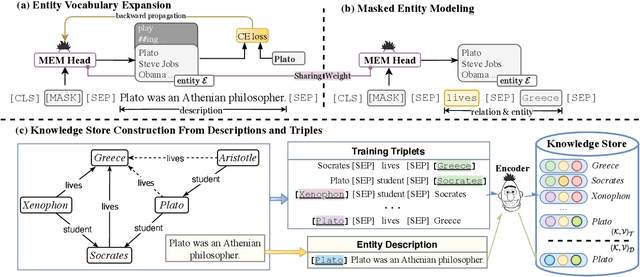
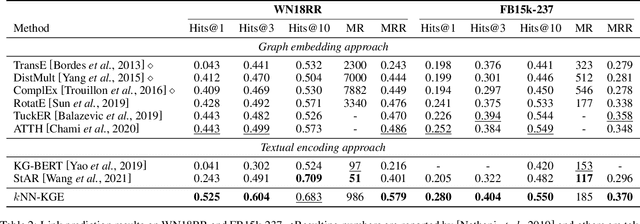
Previous knowledge graph embedding approaches usually map entities to representations and utilize score functions to predict the target entities, yet they struggle to reason rare or emerging unseen entities. In this paper, we propose kNN-KGE, a new knowledge graph embedding approach, by linearly interpolating its entity distribution with k-nearest neighbors. We compute the nearest neighbors based on the distance in the entity embedding space from the knowledge store. Our approach can allow rare or emerging entities to be memorized explicitly rather than implicitly in model parameters. Experimental results demonstrate that our approach can improve inductive and transductive link prediction results and yield better performance for low-resource settings with only a few triples, which might be easier to reason via explicit memory.
A Unified Game-Theoretic Interpretation of Adversarial Robustness
Nov 08, 2021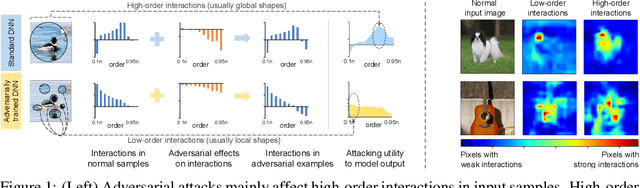

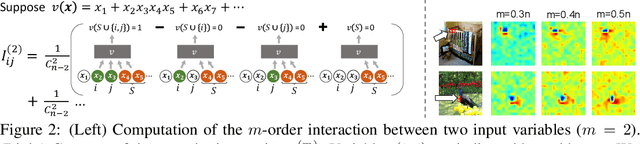
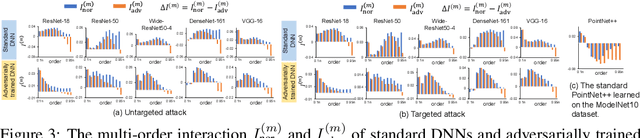
This paper provides a unified view to explain different adversarial attacks and defense methods, \emph{i.e.} the view of multi-order interactions between input variables of DNNs. Based on the multi-order interaction, we discover that adversarial attacks mainly affect high-order interactions to fool the DNN. Furthermore, we find that the robustness of adversarially trained DNNs comes from category-specific low-order interactions. Our findings provide a potential method to unify adversarial perturbations and robustness, which can explain the existing defense methods in a principle way. Besides, our findings also make a revision of previous inaccurate understanding of the shape bias of adversarially learned features.