 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona-Aware Alignment Framework for Personalized Dialogue Generation
Nov 13, 2025Personalized dialogue generation aims to leverage persona profiles and dialogue history to generate persona-relevant and consistent responses. Mainstream models typically rely on token-level language model training with persona dialogue data, such as Next Token Prediction, to implicitly achieve personalization, making these methods tend to neglect the given personas and generate generic responses. To address this issue, we propose a novel Persona-Aware Alignment Framework (PAL), which directly treats persona alignment as the training objective of dialogue generation. Specifically, PAL employs a two-stage training method including Persona-aware Learning and Persona Alignment, equipped with an easy-to-use inference strategy Select then Generate, to improve persona sensitivity and generate more persona-relevant responses at the semantics level. Through extensive experiments, we demonstrate that our framework outperforms many state-of-the-art personalized dialogue methods and large language models.
Extensions of Robbins-Siegmund Theorem with Applications in Reinforcement Learning
Sep 30, 2025The Robbins-Siegmund theorem establishes the convergence of stochastic processes that are almost supermartingales and is foundational for analyzing a wide range of stochastic iterative algorithms in stochastic approximation and reinforcement learning (RL). However, its original form has a significant limitation as it requires the zero-order term to be summable. In many important RL applications, this summable condition, however, cannot be met. This limitation motivates us to extend the Robbins-Siegmund theorem for almost supermartingales where the zero-order term is not summable but only square summable. Particularly, we introduce a novel and mild assumption on the increments of the stochastic processes. This together with the square summable condition enables an almost sure convergence to a bounded set. Additionally, we further provide almost sure convergence rates, high probability concentration bounds, and $L^p$ convergence rates. We then apply the new results in stochastic approximation and RL. Notably, we obtain the first almost sure convergence rate, the first high probability concentration bound, and the first $L^p$ convergence rate for $Q$-learning with linear function approximation.
IIET: Efficient Numerical Transformer via Implicit Iterative Euler Method
Sep 26, 2025



High-order numerical methods enhance Transformer performance in tasks like NLP and CV, but introduce a performance-efficiency trade-off due to increased computational overhead. Our analysis reveals that conventional efficiency techniques, such as distillation, can be detrimental to the performance of these models, exemplified by PCformer. To explore more optimizable ODE-based Transformer architectures, we propose the \textbf{I}terative \textbf{I}mplicit \textbf{E}uler \textbf{T}ransformer \textbf{(IIET)}, which simplifies high-order methods using an iterative implicit Euler approach. This simplification not only leads to superior performance but also facilitates model compression compared to PCformer. To enhance inference efficiency, we introduce \textbf{I}teration \textbf{I}nfluence-\textbf{A}ware \textbf{D}istillation \textbf{(IIAD)}. Through a flexible threshold, IIAD allows users to effectively balance the performance-efficiency trade-off. On lm-evaluation-harness, IIET boosts average accuracy by 2.65\% over vanilla Transformers and 0.8\% over PCformer. Its efficient variant, E-IIET, significantly cuts inference overhead by 55\% while retaining 99.4\% of the original task accuracy. Moreover, the most efficient IIET variant achieves an average performance gain exceeding 1.6\% over vanilla Transformer with comparable speed.
TCPO: Thought-Centric Preference Optimization for Effective Embodied Decision-making
Sep 10, 2025



Using effective generalization capabilities of vision language models (VLMs) in context-specific dynamic tasks for embodied artificial intelligence remains a significant challenge. Although supervised fine-tuned models can better align with the real physical world, they still exhibit sluggish responses and hallucination issues in dynamically changing environments, necessitating further alignment. Existing post-SFT methods, reliant on reinforcement learning and chain-of-thought (CoT) approaches, are constrained by sparse rewards and action-only optimization, resulting in low sample efficiency, poor consistency, and model degradation. To address these issues, this paper proposes Thought-Centric Preference Optimization (TCPO) for effective embodied decision-making. Specifically, TCPO introduces a stepwise preference-based optimization approach, transforming sparse reward signals into richer step sample pairs. It emphasizes the alignment of the model's intermediate reasoning process, mitigating the problem of model degradation. Moreover, by incorporating Action Policy Consistency Constraint (APC), it further imposes consistency constraints on the model output. Experiments in the ALFWorld environment demonstrate an average success rate of 26.67%, achieving a 6% improvement over RL4VLM and validating the effectiveness of our approach in mitigating model degradation after fine-tuning. These results highlight the potential of integrating preference-based learning techniques with CoT processes to enhance the decision-making capabilities of vision-language models in embodied agents.
FusionCounting: Robust visible-infrared image fusion guided by crowd counting via multi-task learning
Aug 28, 2025



Most visible and infrared image fusion (VIF) methods focus primarily on optimizing fused image quality. Recent studies have begun incorporating downstream tasks, such as semantic segmentation and object detection, to provide semantic guidance for VIF. However, semantic segmentation requires extensive annotations, while object detection, despite reducing annotation efforts compared with segmentation, faces challenges in highly crowded scenes due to overlapping bounding boxes and occlusion. Moreover, although RGB-T crowd counting has gained increasing attention in recent years, no studies have integrated VIF and crowd counting into a unified framework. To address these challenges, we propose FusionCounting, a novel multi-task learning framework that integrates crowd counting into the VIF process. Crowd counting provides a direct quantitative measure of population density with minimal annotation, making it particularly suitable for dense scenes. Our framework leverages both input images and population density information in a mutually beneficial multi-task design. To accelerate convergence and balance tasks contributions, we introduce a dynamic loss function weighting strategy. Furthermore, we incorporate adversarial training to enhance the robustness of both VIF and crowd counting, improving the model's stability and resilience to adversarial attacks. Experimental results on public datasets demonstrate that FusionCounting not only enhances image fusion quality but also achieves superior crowd counting performance.
aiXiv: A Next-Generation Open Access Ecosystem for Scientific Discovery Generated by AI Scientists
Aug 20, 2025Recent advances in large language models (LLMs) have enabled AI agents to autonomously generate scientific proposals, conduct experiments, author papers, and perform peer reviews. Yet this flood of AI-generated research content collides with a fragmented and largely closed publication ecosystem. Traditional journals and conferences rely on human peer review, making them difficult to scale and often reluctant to accept AI-generated research content; existing preprint servers (e.g. arXiv) lack rigorous quality-control mechanisms. Consequently, a significant amount of high-quality AI-generated research lacks appropriate venues for dissemination, hindering its potential to advance scientific progress. To address these challenges, we introduce aiXiv, a next-generation open-access platform for human and AI scientists. Its multi-agent architecture allows research proposals and papers to be submitted, reviewed, and iteratively refined by both human and AI scientists. It also provides API and MCP interfaces that enable seamless integration of heterogeneous human and AI scientists, creating a scalable and extensible ecosystem for autonomous scientific discovery. Through extensive experiments, we demonstrate that aiXiv is a reliable and robust platform that significantly enhances the quality of AI-generated research proposals and papers after iterative revising and reviewing on aiXiv. Our work lays the groundwork for a next-generation open-access ecosystem for AI scientists, accelerating the publication and dissemination of high-quality AI-generated research content. Code is available at https://github.com/aixiv-org. Website is available at https://forms.gle/DxQgCtXFsJ4paMtn8.
Improved Personalized Headline Generation via Denoising Fake Interests from Implicit Feedback
Aug 10, 2025Accurate personalized headline generation hinges on precisely capturing user interests from historical behaviors. However, existing methods neglect personalized-irrelevant click noise in entire historical clickstreams, which may lead to hallucinated headlines that deviate from genuine user preferences. In this paper, we reveal the detrimental impact of click noise on personalized generation quality through rigorous analysis in both user and news dimensions. Based on these insights, we propose a novel Personalized Headline Generation framework via Denoising Fake Interests from Implicit Feedback (PHG-DIF). PHG-DIF first employs dual-stage filtering to effectively remove clickstream noise, identified by short dwell times and abnormal click bursts, and then leverages multi-level temporal fusion to dynamically model users' evolving and multi-faceted interests for precise profiling. Moreover, we release DT-PENS, a new benchmark dataset comprising the click behavior of 1,000 carefully curated users and nearly 10,000 annotated personalized headlines with historical dwell time annotations. Extensive experiments demonstrate that PHG-DIF substantially mitigates the adverse effects of click noise and significantly improves headline quality, achieving state-of-the-art (SOTA) results on DT-PENS. Our framework implementation and dataset are available at https://github.com/liukejin-up/PHG-DIF.
* Accepted by the 34th ACM International Conference on Information and Knowledge Management (CIKM '25), Full Research Papers track
EndoGen: Conditional Autoregressive Endoscopic Video Generation
Jul 23, 2025Endoscopic video generation is crucial for advancing medical imaging and enhancing diagnostic capabilities. However, prior efforts in this field have either focused on static images, lacking the dynamic context required for practical applications, or have relied on unconditional generation that fails to provide meaningful references for clinicians. Therefore, in this paper, we propose the first conditional endoscopic video generation framework, namely EndoGen. Specifically, we build an autoregressive model with a tailored Spatiotemporal Grid-Frame Patterning (SGP) strategy. It reformulates the learning of generating multiple frames as a grid-based image generation pattern, which effectively capitalizes the inherent global dependency modeling capabilities of autoregressive architectures. Furthermore, we propose a Semantic-Aware Token Masking (SAT) mechanism, which enhances the model's ability to produce rich and diverse content by selectively focusing on semantically meaningful regions during the generation process. Through extensive experiments, we demonstrate the effectiveness of our framework in generating high-quality, conditionally guided endoscopic content, and improves the performance of downstream task of polyp segmentation. Code released at https://www.github.com/CUHK-AIM-Group/EndoGen.
ExAct: A Video-Language Benchmark for Expert Action Analysis
Jun 06, 2025We present ExAct, a new video-language benchmark for expert-level understanding of skilled physical human activities. Our new benchmark contains 3521 expert-curated video question-answer pairs spanning 11 physical activities in 6 domains: Sports, Bike Repair, Cooking, Health, Music, and Dance. ExAct requires the correct answer to be selected from five carefully designed candidate options, thus necessitating a nuanced, fine-grained, expert-level understanding of physical human skills. Evaluating the recent state-of-the-art VLMs on ExAct reveals a substantial performance gap relative to human expert performance. Specifically, the best-performing GPT-4o model achieves only 44.70% accuracy, well below the 82.02% attained by trained human specialists/experts. We believe that ExAct will be beneficial for developing and evaluating VLMs capable of precise understanding of human skills in various physical and procedural domains. Dataset and code are available at https://texaser.github.io/exact_project_page/
Track Any Anomalous Object: A Granular Video Anomaly Detection Pipeline
Jun 05, 2025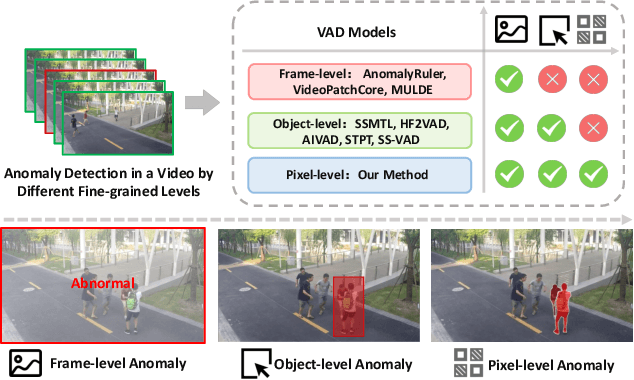
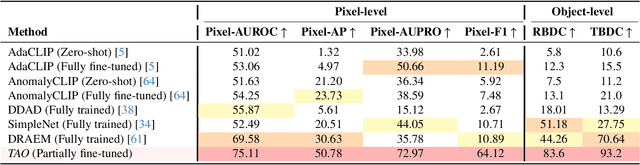
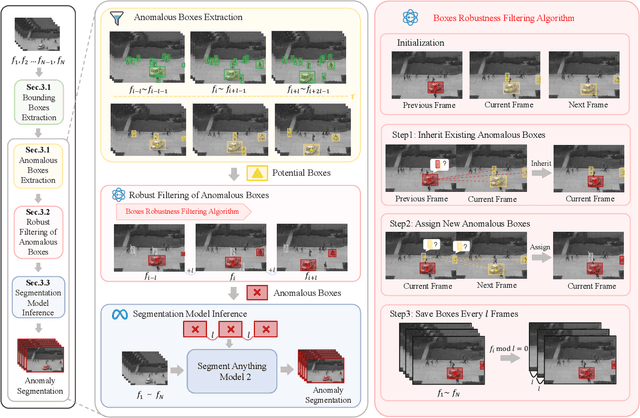
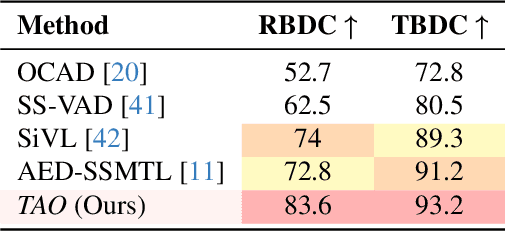
Video anomaly detection (VAD) is crucial in scenarios such as surveillance and autonomous driving, where timely detection of unexpected activities is essential. Although existing methods have primarily focused on detecting anomalous objects in videos -- either by identifying anomalous frames or objects -- they often neglect finer-grained analysis, such as anomalous pixels, which limits their ability to capture a broader range of anomalies. To address this challenge, we propose a new framework called Track Any Anomalous Object (TAO), which introduces a granular video anomaly detection pipeline that, for the first time, integrates the detection of multiple fine-grained anomalous objects into a unified framework. Unlike methods that assign anomaly scores to every pixel, our approach transforms the problem into pixel-level tracking of anomalous objects. By linking anomaly scores to downstream tasks such as segmentation and tracking, our method removes the need for threshold tuning and achieves more precise anomaly localization in long and complex video sequences. Experiments demonstrate that TAO sets new benchmarks in accuracy and robustness. Project page available online.